Autonomous vehicles and advanced robotics depend on machines being able to interpret the physical world. To train those systems, companies collect large amounts of raw data from cameras, LiDAR, and other sensors. That data then has to be labeled so models can learn to identify objects, movement, distance, road conditions, obstacles, and other real-world signals accurately.
This is where data-labeling companies come in. In autonomous vehicles and robotics, their role is not limited to tagging a few images and sending them back. It is also about ingesting, organizing, retaining, and retrieving massive datasets over time.
Step
What it means in practice
Ingesting
Receiving large raw datasets from autonomous vehicle or robotics teams, such as road video, LiDAR files, camera feeds, and other machine-captured data
Organizing
Sorting the data so it can actually be worked on, for example by vehicle run, location, sensor type, scene, project, edge case, or labeling status
Retaining
Keeping the data after the first labeling pass because it may still be needed later for QA, relabeling, retraining, audits, or rare edge cases
Retrieving
Pulling older data back when needed, such as revisiting nighttime pedestrian clips or checking the original raw sequence behind a completed label set
Seen this way, autonomous vehicle and robotics labeling is not just an annotation task. It is also a data-handling and storage problem. In this blog post, we will spotlight three realities shaping this segment:
1. Autonomous vehicle and robotics labeling involves much larger and heavier datasets than many people assume 2. Labeling video, LiDAR, and multimodal data is more complex than standard annotation workflows 3. At scale, archived data becomes a trust problem, not just a storage problem
And we will close with where Filecoin fits in this stack, and why it becomes relevant for retained data that still needs to remain durable, economically retrievable, and trustworthy over time.
1. The datasets are much larger and heavier than they first appear
The first thing to understand about autonomous vehicle and robotics labeling is that the workflow begins with a large volume of raw machine-generated data. Before any labeling work begins, teams already have to handle huge quantities of video and sensor data that need to be uploaded, organized, and prepared for review. At that point, the challenge is no longer just annotation. It is also the operational work of moving and managing heavy datasets from the start.
Autonomous vehicles (AVs) are evolving into mobile computing platforms, equipped with powerful processors and diverse sensors that generate massive heterogeneous data, for example 14 TB per day.” – AVS paper by arXiv, November 2025
This is not just a theoretical concern. Rivian, an electric vehicle maker developing autonomy features, has already described the problem in operational terms. In a 2025 AWS case study, AWS said Rivian’s data-collection test fleet generates terabytes of sensor and camera data every day, creating a real challenge for upload, storage, and processing.
BMW offers another example of what happens when storage cost becomes part of the workflow. In 2025, AWS said it worked with BMW on a petabyte-scale automated driving data lake and built a way to identify recordings for faster archiving based on access patterns. The point was not just to store more data, but to move less-active recordings into cheaper archival storage sooner, potentially within days of arrival rather than waiting for the standard 30-day transition period.
That matters because even before labeling, QA, or reprocessing begin, the scale of the raw data is already substantial. For teams working in autonomous vehicle and robotics workflows, the scale of the raw data alone starts to push the work beyond lightweight annotation and into a storage-heavy data operation.
2. Video, LiDAR, and multimodal labeling are harder than standard annotation
The second reality is that “labeling” in autonomous vehicle and robotics workflows is not one single task. Different systems require different types of labels depending on what the model needs to learn. Some tasks involve identifying objects across long video sequences, others involve labeling three-dimensional LiDAR data, and others require multiple sensor views of the same scene to be aligned together.
Taken together, these methods make the work more demanding than standard annotation. Video requires consistency across time. LiDAR requires spatial understanding in three dimensions. Multimodal workflows require labels to remain aligned across different sensor views of the same environment. For example, Waymo’s public perception data includes camera and LiDAR data, along with tasks such as 2D and 3D tracking and 3D semantic segmentation.
That is a useful reminder that this segment is not dealing with simple one-pass annotation jobs. It is dealing with richer perception data that often requires more specialized tooling, tighter review, and repeated revisiting of the same underlying datasets.
As a result, the storage layer matters more here than in lighter annotation workflows, because the data often needs to remain available for review, relabeling, and future model iteration.
3. Archived data becomes an unproven liability at scale
Once autonomous vehicle and robotics datasets start to accumulate, the challenge is no longer just where they are stored. It is whether teams can trust that the data will still be usable when they need it again.
Older data does not always stay active, but it rarely becomes irrelevant. Teams may need to restore past video clips, LiDAR scans, sensor logs, or labeled datasets for QA, relabeling, model iteration, edge-case review, audit support, or incident investigation.
This creates a restore confidence gap: the gap between believing archived data is safe and being able to verify that it is still intact, recoverable, and tied back to the correct source material or dataset version. That gap matters because many systems treat archive integrity as an assumption. Data is written, retained, and expected to be available later. But in high-stakes AV and robotics workflows, teams may eventually need to prove:
Can the original data be restored?
Does it match what was originally stored?
Is it tied to the right version, label, or model workflow?
Has it remained intact over time?
This is where storage becomes more than a cost center. Cost, retrieval fees, and retrieval speed still matter, but the deeper operational problem is confidence. Cheap storage is not enough if archived data becomes difficult to verify, expensive to restore, or unreliable when needed.
A simple comparison helps make the issue more concrete. Consider AWS S3 Standard alongside Akave Cloud, an S3-compatible storage service backed by Filecoin:
Akave Cloud shows how Filecoin-backed storage can be packaged in a familiar cloud interface. But the stronger point is not just cost. It is verification. Filecoin is designed around a proof-based model where data existence and integrity can be checked over time, rather than simply assumed after upload.
For AV and robotics labeling, that distinction matters. Content addressing and provenance can help tie data back to exact files, versions, or dataset states. A decentralized storage network can also reduce reliance on a single provider or internal system.
The issue, then, is not just that storage gets harder at scale. It is that archived data becomes an unproven liability unless teams can verify that it remains retrievable, intact, and usable. This is where Filecoin’s relevance becomes clearer: it addresses the proof problem, not just the storage problem.
Conclusion
In conclusion, Filecoin’s relevance in autonomous vehicle and robotics labeling becomes clearer when these workflows are understood not just as annotation tasks, but as long-term data infrastructure problems.
Every video clip, LiDAR scan, sensor log, and labeled edge case can remain useful long after the first training run. Teams may need to revisit old labels, reproduce past datasets, investigate model behavior, or retain historical evidence for safety, QA, and audit purposes. In that context, the question is no longer just where the data is stored. It is whether teams can restore it with confidence.
That is where Filecoin’s role becomes more specific. It is not meant to replace every part of the AV or robotics data stack, but to support the retained data layer where durability, retrievability, and verifiability matter most. Through proof-based storage, content addressing, and Filecoin-backed services such as Akave Cloud, teams can begin to treat long-term data retention as something that can be checked and verified over time, not simply assumed.
As AV and robotics datasets continue to grow, the teams that manage their data foundations well will have an advantage. The future will not only depend on who can label data faster, but on who can preserve, restore, and trust the data their models continue to rely on.
Keep exploring Filecoin
Follow FilecoinTLDR for ecosystem explainers and updates.
Start the Filecoin Quest Hub to learn, complete quests, and get involved.
Subscribe to the newsletter for future posts and insights.
Estimated reading time: 8 minutes
Filecoin is entering a market moment that increasingly rewards the kind of infrastructure it was built to provide.
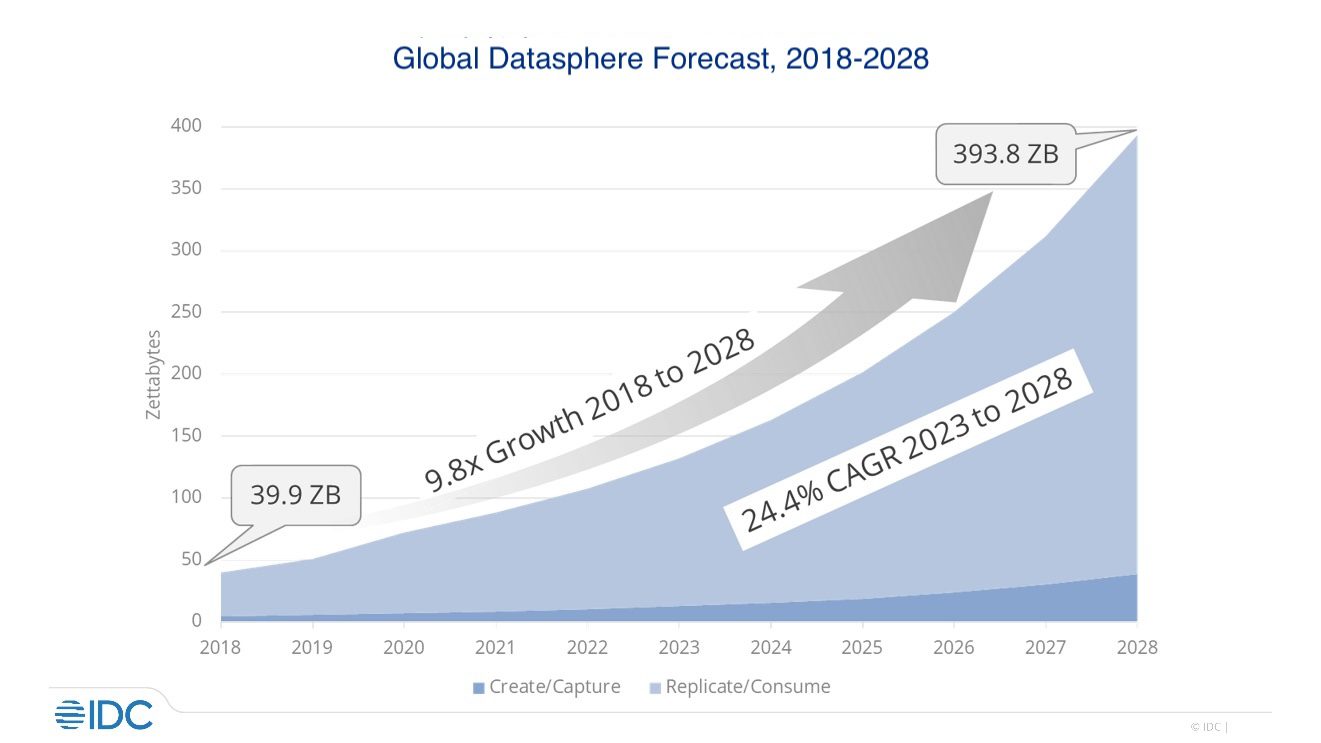
Global data creation is accelerating across AI, enterprise systems, public datasets, and machine-generated workloads. As that growth compounds, storage infrastructure is becoming more strategic, more capital-intensive, and harder to scale through centralized expansion alone. At the same time, AI is raising the bar for what storage needs to provide: not just capacity, but durability, verifiability, and fit for machine-driven workflows.
Together, these shifts are making Filecoin easier to understand as a more serious storage platform – one with real infrastructure, growing commercial relevance, and stronger alignment with next-generation data needs. Filecoin’s 2026 strategy reflects that shift, moving from supply buildout toward demand capture through paid onchain storage, stronger network economics, and flagship client adoption.
In this piece, we examine three forces shaping that opportunity:
Data is growing faster than centralized storage can handle
AI is shifting value toward infrastructure and data layers
As infrastructure grows more strategic, lock-in costs are getting harder to ignore
1. Data growth is accelerating faster than centralized storage can comfortably absorb
The first macro shift is straightforward: the world is generating more data, across more systems, at a faster pace than before, creating a storage environment that is no longer growing linearly.
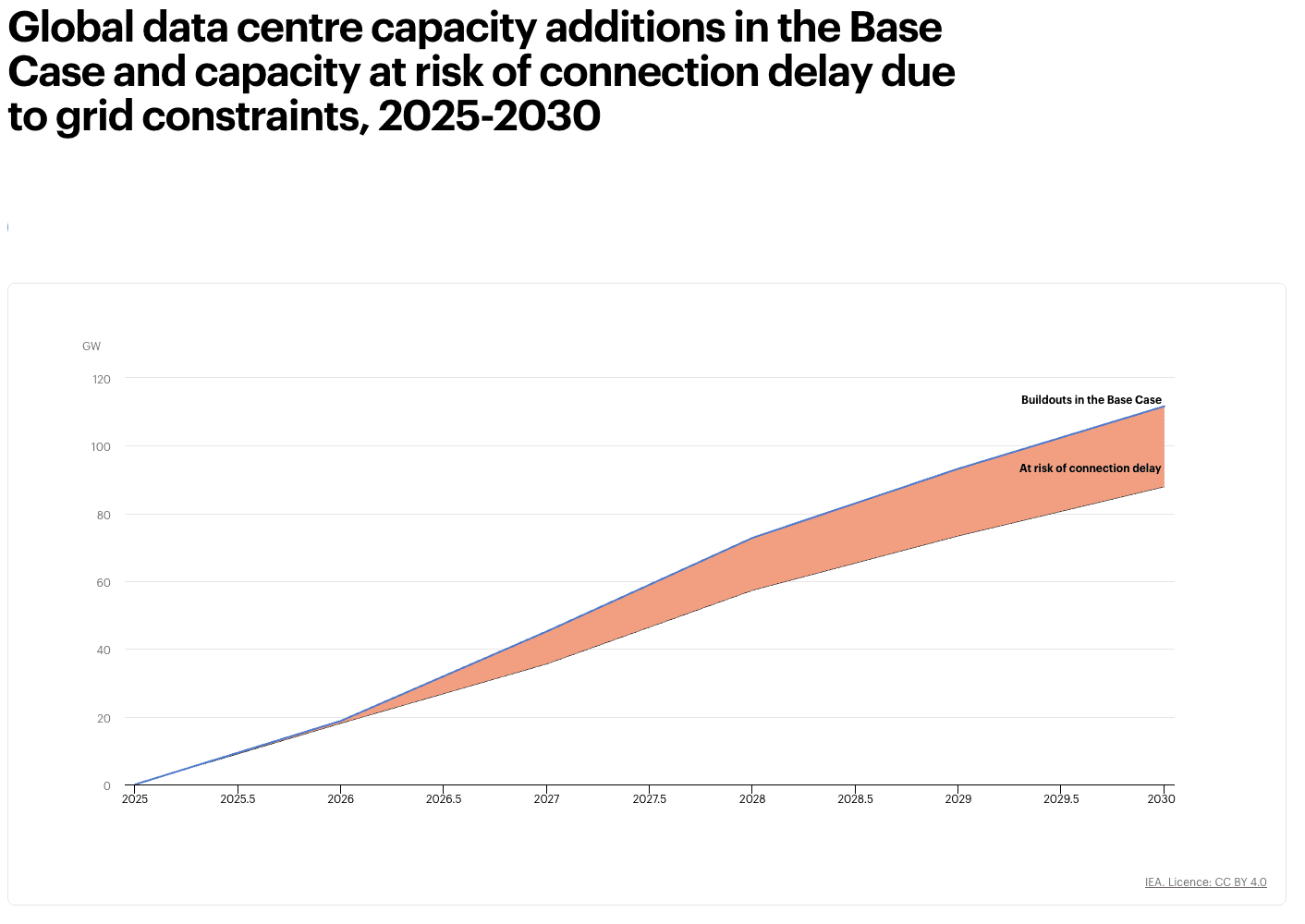
Even the dominant cloud model is still constrained by physical expansion. Amazon, Microsoft, and Google built the defining infrastructure model of the cloud era, but scaling it still depends on land, power, hardware, and time. Microsoft has already said that demand exceeded available supply across Azure workloads, pointing to a broader reality: as infrastructure becomes more power- and hardware-intensive, storage and compute are increasingly shaped by the limits of physical buildout, not just software demand.
That constraint is already showing up in the buildout pipeline itself. Around one-fifth of planned global data-centre buildout could face connection delays due to grid constraints, highlighting how AI-era infrastructure growth is increasingly shaped by physical bottlenecks.
This is where Filecoin becomes more relevant. Its model does not depend on one company expanding its footprint one location at a time; it aggregates storage capacity across a distributed network of providers.
At peak onboarding in 2021, the network added more than 59 PiB of raw storage in a single day, showing how quickly real infrastructure could be deployed across that base. That makes Filecoin more than a different storage architecture. It makes it a different supply model – one with meaningful capacity, broad operator participation, and a way of scaling infrastructure that is fundamentally less tied to centralized buildout.
2. AI is shifting value toward infrastructure and data layers
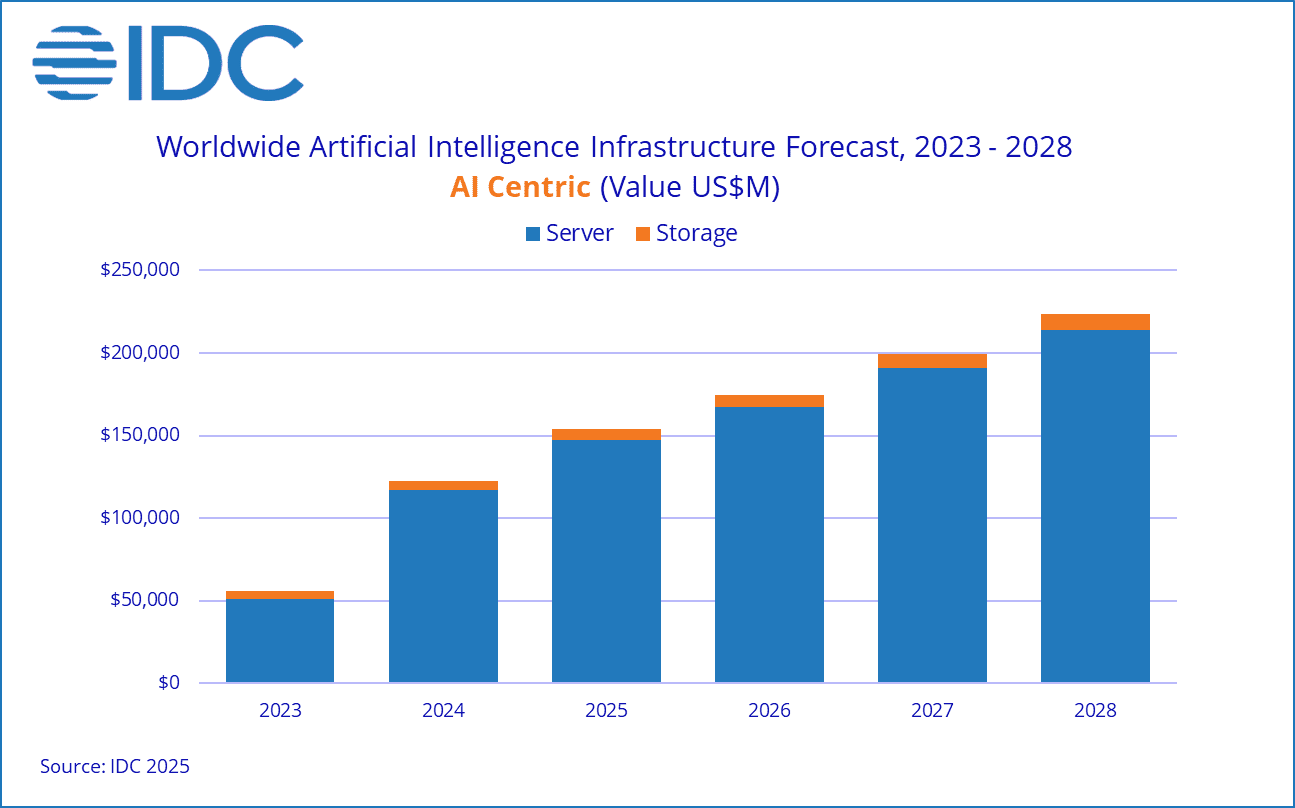
What some in tech and AI circles have started calling the “saaspocalypse” is less the end of software than a shift in where value accrues. As AI becomes more capable, it may start to replace parts of the traditional SaaS layer – including workflows businesses may once have paid for on a per-seat basis. But as that happens, value does not disappear; it tends to move down the stack. Infrastructure and data-layer businesses are already benefiting as value shifts down the stack. Palantir reported 70% year-over-year revenue growth in Q4 2025, while Databricks said in February 2026 that it had surpassed a $5.4 billion revenue run-rate, growing more than 65% year over year, with its AI products alone crossing a $1.4 billion run-rate.
That same shift is also visible at the market level. Spending on AI infrastructure is rising sharply, reinforcing that AI is no longer a marginal software layer but a core infrastructure priority.
As AI systems move deeper into business workflows, the question of what businesses need from their infrastructure also changes. That raises the importance of properties that matter in practical terms:
Resilience – so data is not lost
Provenance – so teams can understand where data came from and how it has been handled
Sovereignty – so sensitive data can be controlled and moved more easily across systems
Verifiability – so businesses can check that data has been stored, handled, and preserved as expected
The recent interest in tools like OpenClaw reflects a broader desire to keep more AI-driven workflows on users’ own devices, with greater control over how data is handled, who can access it, and what remains verifiable over time.
That is where Filecoin’s relevance becomes clearer. It is designed around verifiable storage, which matters more in an environment where data is harder to trust, more valuable to validate, and increasingly consumed by systems rather than people. As datasets grow larger and more distributed, those requirements become more important – not just technically, but commercially, because businesses need stronger confidence in the data that underpins real workflows, products, and decisions.
Emerging use cases make that argument more tangible. 375ai, which says its edge network is deployed across more than 40,000 retail, industrial, and logistics locations in the U.S., is working with Akave on a verifiable data pipeline that includes redundant backups on Filecoin for added durability. It is a useful example of how AI-era data infrastructure can converge around provenance, sovereignty, and durable storage by design.
3. As infrastructure becomes more strategic, the costs of lock-in become harder to ignore
The integrated cloud model delivered a powerful value proposition: convenience, scale, tooling, and performance inside one ecosystem. That is a large part of what made AWS, Azure, and Google Cloud so dominant. But as infrastructure becomes more strategic, the tradeoffs of that model become more material – especially when moving data across closed infrastructure ecosystems carries real cost and friction.
A 2026 survey from Parallels found that 94% of organizations are concerned about vendor lock-in, with nearly half saying they are very concerned.
As data volumes grow, those tradeoffs become more material. What feels manageable at a smaller scale can become far more constraining once datasets are large, long-lived, and central to business operations.Infrastructure decisions become harder to reverse, and architectural dependency becomes more expensive to absorb.
That does not mean enterprises are abandoning hyperscalers. They remain foundational. But it does mean businesses may become more open to complementary infrastructure models with different tradeoffs around portability, verification, reach, and cost.
This is another place where Filecoin becomes more legible in market terms. Amazon, Microsoft, and Google remain foundational, but their dominance also makes the limits of the integrated model more visible as infrastructure requirements change. Filecoin offers a different infrastructure logic – one built around globally aggregated supply, verifiable storage, and a more modular approach to how data and workloads can be retained, moved, and increasingly composed across layers. That is what makes Filecoin increasingly credible not only as infrastructure, but as a complement within the broader infrastructure stack.
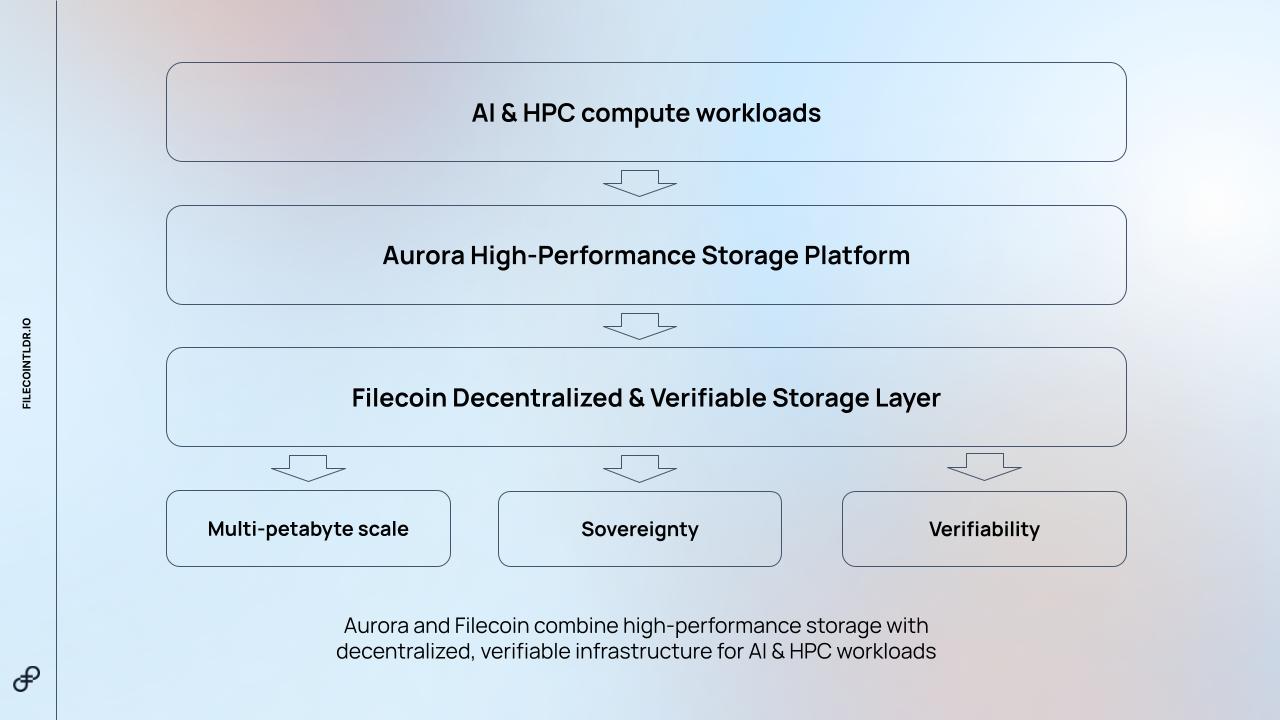
That broader positioning is becoming easier to see in the ecosystem itself. Aurora is partnering with a European AI and high-performance computing (HPC) provider to deliver high-performance storage powered by Filecoin across 100MW AI compute data centers in Europe. The solution is built for multi-petabyte workloads, high-speed access, and stronger guarantees around privacy, sovereignty, and verifiability in data-intensive AI environments.
Why this moment matters now
What makes this moment more important is not just that the market is changing. It is that the market is changing in ways that increasingly align with what Filecoin was built to offer.
Data growth is accelerating. AI is making infrastructure and data layers more strategic, more trust-sensitive, and more operationally important. And as infrastructure decisions become harder to reverse, businesses are becoming more attentive to portability, control, and the limits of closed infrastructure models.
At the same time, the Filecoin ecosystem is becoming more commercially legible. The strategic shift toward paid onchain storage, stronger network economics, and flagship client adoption matters because macro tailwinds only matter if the infrastructure is positioned to capture them.
That is what makes this moment more consequential. Filecoin is becoming easier to understand not just as an alternative architecture, but as infrastructure increasingly aligned with where the market is going.
Follow the ecosystem’s 2026 push toward paid usage, stronger economics, and flagship client adoption.
To stay updated on the latest in the Filecoin ecosystem, follow the @Filecointldr handle or join us on Discord.
Many thanks to Jonathan Victor and Oleh for providing valuable insights to this piece.
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
Introduction and Overview
In this post, we explore what the Filecoin Onchain Cloud (FOC) is, why it matters, and how it turns the Filecoin network into a trustless, programmable cloud layer for the open data economy:
What FOC Is and Why It’s Needed We start by explaining what Filecoin Onchain Cloud is, why it was developed, and what it enables. This section highlights the core components, architecture, and foundational services that make programmable, verifiable, and trustless cloud workloads possible and how these capabilities strengthen the Filecoin ecosystem.
Use-Case Verticals and Real-World Builders We then outline the key use-case verticals enabled by FOC For each vertical, we highlight both potential opportunities and the early integrations.
Developer Resources & Ways to Get Involved Finally, we share tools, resources, and actionable next steps for developers, storage providers, and ecosystem participants looking to build on FOC.
1. What is Filecoin Onchain Cloud and What It Unlocks
The Filecoin Onchain Cloud (FOC) marks a major milestone in Filecoin’s evolution, transforming the network from a storage provisioning protocol into a programmable, verifiable, and composable onchain cloud platform.
First introduced at Filecoin Dev Summit 5 (FDS-5), FOC builds on the foundations of Filecoin Web Services and formalizes it as a core part of the Filecoin roadmap. It was born out of a recurring question within the community: “What is Filecoin, and how can anyone easily use it to power everyday application storage needs?”
After five years of growth, the network had expanded significantly, but builders still sought easier ways to leverage Filecoin for everyday application storage needs. FOC was developed to make Filecoin more usable, flexible, and aligned with the demands of modern Web3 developers and applications. Filecoin Onchain Cloud officially launched on November 18th, marking the beginning of this new chapter for the Filecoin network.
Why It’s Needed and What It Unlocks
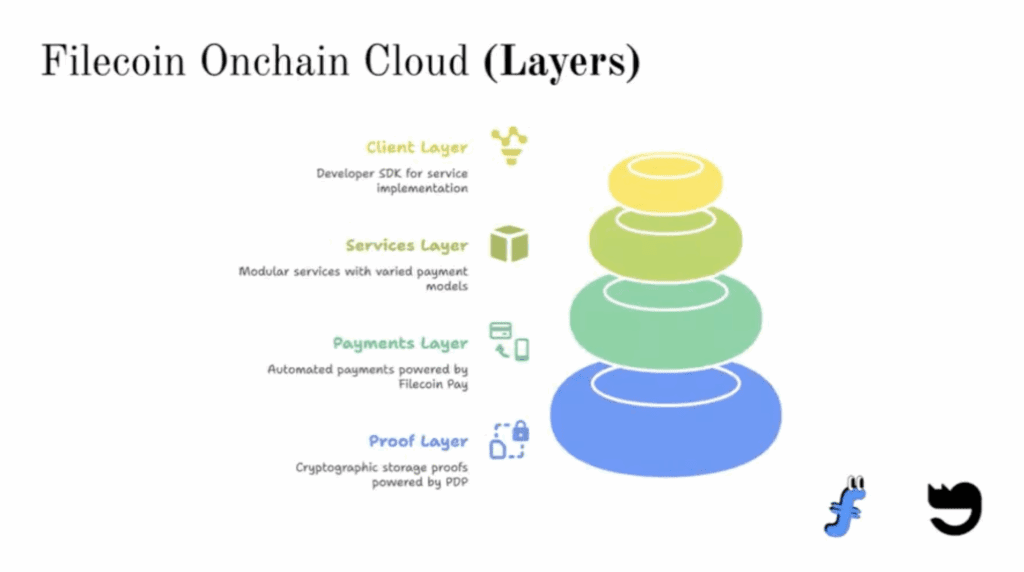
At its core, Filecoin Onchain Cloud (FOC) turns Filecoin from a decentralized storage network into a fully programmable onchain cloud. It is the next step in the network’s evolution, made possible by prior upgrades: the Filecoin Virtual Machine (FVM), Proof of Data Possession (PDP) and F3 retrieval guarantees. These upgrades unlocked the ability to bring together Filecoin’s three core markets – storage, retrieval, and compute into a single layer.
On top of this foundation, FOC provides developers, storage providers, and users with a set of capabilities that address modern application needs and enable new types of services, which are outlined below:
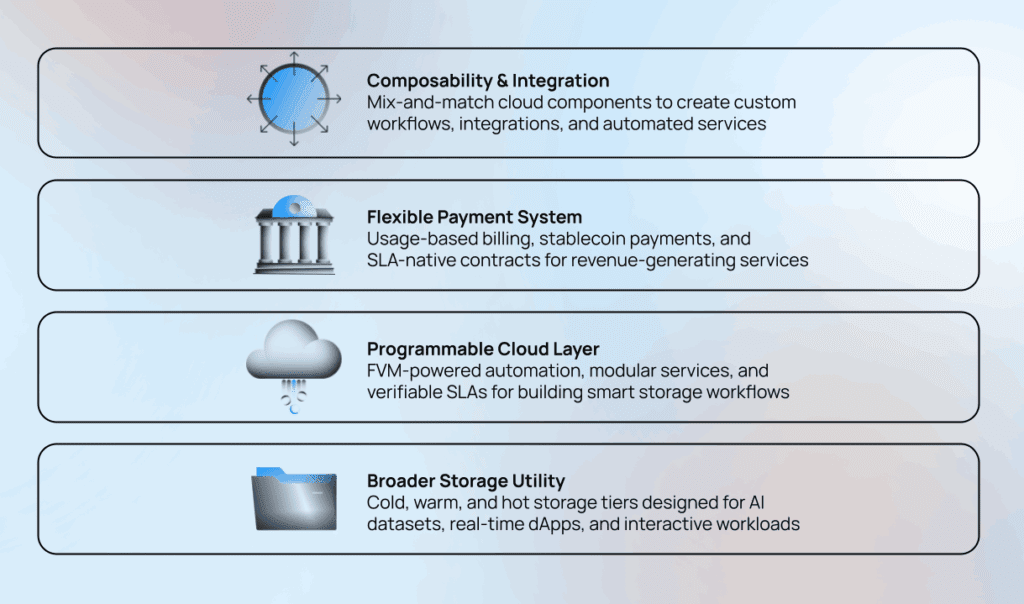
Composability and Integration: FOC supports modular and composable cloud components, allowing builders to combine, and remix services. (For example: combining Filecoin Warm Storage Services + Filecoin Beam + Filecoin Pay allows a developer to create a verifiable, usage-based backup service with automated scheduling and billing)
Flexible Payment System: Tools like Filecoin Pay and SLA-native payment contracts let service creators run revenue-generating offerings with recurring and stablecoin-based payments (e.g., USDFC). This helps power a robust, programmable onchain economy.
Programmable Cloud Layer: Existing decentralized storage infrastructure often lack programmability and automation, making it difficult to run complex workflows or enforce service-level guarantees. Filecoin Onchain Cloud (FOC) solves this by turning Filecoin into a fully programmable onchain cloud via the Filecoin Virtual Machine (FVM). Developers can deploy modular, verifiable services with onchain guarantees, enabling automated storage workflows, Service Level Agreements (SLA) – based agreements, and composable infrastructure for diverse applications.
Broader Storage Utility: Filecoin began as a cold storage network for archival data, but modern Web3 applications – like AI datasets, real-time dApps, and interactive platforms – demand fast, warm, and cold storage tiers. FOC meets this need, enabling dynamic access to data while maintaining verifiability.
By enabling new services and economic activity, FOC solidifies Filecoin as a foundational programmable cloud for Web3.
Filecoin Pay – Enables onchain payments that are tied to verifiable service performance, supporting both one-off and recurring transactions.
Filecoin Pin – Brings IPFS and Filecoin closer than ever for fast, decentralized, and persistent data storage.
Filecoin Beam – Bridges verifiable data movement across onchain and offchain systems.
Synapse SDK – Provides developers with simple APIs and interfaces to connect and interact with FOC services.
These building blocks form the foundation for a programmable, composable, and verifiable onchain cloud, allowing developers to create reliable applications with automated guarantees and measurable service performance.
2. Exploring Use Cases with Filecoin Onchain Cloud
Filecoin Onchain Cloud enables a wide range of applications, spanning AI, autonomous agents, web3 dApps, archival storage, and more. Here’s a breakdown by vertical:
AI and Autonomous Agents
Filecoin Onchain Cloud allows AI and autonomous agents to store models, execute tasks, and automate payments with onchain proofs. This enables trustless, usage-based workflows that traditional cloud systems cannot provide.
Current Integrations and Builders:
Monad: EVM-based L1 providing low-latency compute paired with Filecoin Onchain Cloud’s verifiable storage for AI model training and deployment.
ERC-8004: Open-source SDK enabling onchain AI agent creation and verifiable storage of agent metadata.
Cairn: Rewards reproducible AI research using verifiable storage and Filecoin Pay.
Groundline: Decentralized knowledge-graph database for AI and research teams.
Web3 dApps and Frontends
Filecoin Onchain Cloud provides Web3 applications with a verifiable foundation where storage and updates can be audited on-chain. Frontends can be deployed without centralized servers, using smart contracts and onchain coordination to control how content is stored, retrieved, and updated.
Current Integrations and Builders:
Ethereum Name Service (ENS) and SAFE: Combines ENS onchain naming, Filecoin verifiable storage, and Safe multisig governance for resilient, user-controlled web experiences.
Filosign: Onchain DocuSign alternative with cryptographic e-signatures.
Cha-Ching: Rewards developers and AI agents for verified GitHub contributions.
Filecoin Onchain Cloud offers verifiable storage for archival, web preservation, and data-heavy workloads such as AI and ML. Builders can create modular storage services with programmable payments and storage proofs. FOC supports both cold and warm storage, fast retrieval through Filecoin Beam, and IPFS integration, enabling higher-throughput applications with verifiable data.
Storacha Forge: Verifiable warm storage for enterprise AI training data and DePIN telemetry.
Akave Cloud: Decentralized backup and archiving tier with S3 compatibility and verifiable proofs.
DePIN Networks and Verifiable Infrastructure
Filecoin Ochain Cloud lets developers deploy DePIN applications – sensors, bandwidth, mapping services – directly on-chain with verifiable storage, retrieval, and payment workflows. It also supports local or sovereign cloud infrastructure for enterprises and regional providers.
Current Integrations and Builders
dCipher: Enables fast, secure cross-chain settlement for assets and applications on Filecoin.
Expanding Potential Use Cases
While early builders are focusing on AI, Web3 dApps, archival storage, and DePIN networks, we’re particularly bullish on these areas because they demonstrate FOC’s capabilities. The examples below show where FOC can add value, though its potential goes beyond these verticals:
Enterprise SaaS & Compliance Platforms: Automate SLAs, verifiable storage of client data, and recurring payments with stablecoins.
Media & Content Platforms: Deliver content with verifiable access, usage-based payments, and faster retrieval.
Financial Services & Document Workflows: Securely store records, link workflows to verifiable events, and automate payments.
Data Marketplaces & Analytics Platforms: Sell datasets or APIs with verifiable delivery and automated payments.
Hybrid Web 2.5 Applications: Integrate verifiable storage and programmable payments into existing applications.
Access the Official Filecoin Onchain Cloud documentation: Explore all core services, developer tools, SDKs, and guides. This is your central hub for learning how to build, integrate, and deploy on FOC.
Dive into the FOC Stack with the Cheat Sheet by FIL Builders: Get a detailed breakdown of the underlying infrastructure – from cryptographic storage and economic layers to full service implementation with the developer SDK. The cheat sheet helps builders understand how the components connect and how to leverage them effectively.
In Conclusion: Building the Cloud Layer of the Open Data Economy
The Filecoin Onchain Cloud extends Filecoin’s mission – transforming the world’s largest decentralized storage network into a programmable, verifiable, and composable cloud platform.
Where the FVM enabled base-layer programmability, the Filecoin Onchain Cloud adds a service layer that allows developers to create dynamic onchain applications capable of supporting modern workloads and competing with traditional cloud infrastructure.
If Filecoin’s first era created a decentralized data vault, the Filecoin Onchain Cloud adds the tools and infrastructure needed for developers to build reliable, accountable, and verifiable services on top of it.
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
Editor’s Note: This blogpost is a summarised repost of the original content published on 25 April 2025, by Jonathan Victor from Ansa Research. Ansa Research is a research firm focused on distributed infrastructure. The firm covers digital networks aiming to rebuild how internet infrastructure operates.
Introduction
In the evolving landscape of blockchain technology, understanding how a network accrues and sustains its value is paramount for its long-term success. This fundamental question of value accrual is critically examined for Filecoin, drawing comparisons to established models like Bitcoin and other Layer 1 (L1) blockchains such as Ethereum and Solana.
While many Layer 1 networks accrue value through internal services or consensus mechanisms, Filecoin’s path stands apart. Filecoin’s long-term value proposition hinges on external demand – particularly the sale of decentralized storage and Filecoin-backed services.
This ecosystem-wide strategy raises two critical questions:
How can external service adoption be meaningfully tied to the network’s long-term value?
How can this model integrate with the rise of Layer 2s in a way that strengthens the broader Filecoin economy?
The path forward depends on cultivating sustainable, non-speculative value flows. This blogpost explores the core challenges in aligning external demand, protocol design, and Layer 2 development to unlock Filecoin’s full potential.
Understanding Value Accrual Models
To contextualize value accrual mechanisms, let’s start with Bitcoin’s model.
Bitcoin’s Value Accrual Model:
Bitcoin’s value accrual loop is fundamentally tied to its proof-of-work (PoW) security. This security mechanism underpins a compelling narrative, positioning Bitcoin as a decentralized store of value that is backed by energy.
This narrative is crucial because it gives value to the token rewards. These token rewards, in turn, serve to incentivize the proof-of-work process itself. This creates a self-reinforcing cycle or “nice little loop” where the security of the network reinforces the value of its token, and the value of the token incentivizes the maintenance of that security. The ecosystem has a strong tie around this narrative value, emphasizing concepts like the fixed supply of 21 million Bitcoins backed by energy and proof-of-work.
Ethereum and Solana: Value Through Utility
Unlike Bitcoin’s narrative-driven model, Ethereum and Solana accrue value through direct network usage. Their Proof-of-Stake (PoS) systems underpin a utility-centric loop: users pay in native tokens (ETH, SOL) to access core network services, creating real demand.
Key drivers of this value loop include:
Blockspace sales – users pay to include transactions
Execution fees – costs to run smart contracts
Storage fees – charges for persisting data
Transaction prioritization – optional fees to expedite processing
This model links token value to actual on-chain activity. The more developers build and users interact, the more these L1 tokens accrue value – not from external narratives, but from tangible utility baked into the protocol itself.
While networks like Bitcoin, Ethereum, and Solana accrue value through native mechanisms – whether through security incentives or on-chain usage, Filecoin’s approach centers on external demand.
Filecoin’s proposed path for long-term value accrual lies in external services. This strategy involves actively selling Filecoin storage or Filecoin-backed services to the broader world..
This strategic direction raises fundamental questions regarding its execution:
How to effectively connect the sale of these external services to the actual Filecoin value accrual story
How this strategy will function within the growing landscape of Layer 2s (L2s), particularly ensuring that the growth of L2s (especially if they become a significant source of demand generation) is symbiotic and aligned with the Filecoin network
Understanding how value flows throughout the Filecoin economy is crucial for its value accrual. Value flows into the Filecoin economy when people buy FIL to utilize services that Filecoin pushes out into the world. The more that internal transactions can be generated, and mechanisms for locking FIL are created, the more internal demand can be fostered within the ecosystem.
Additionally, consumptive elements, such as gas fees, permanently remove Filecoin from circulation. Conversely, “imports” occur when Filecoin is used to fund external operational or capital expenses.
The goal is to increase the balance of trade so that FIL is more directly connected to the actual value capture loop, rather than merely existing passively on the side. This means ensuring that revenue generated through external services ultimately accretes into the broader Filecoin story and can be measured on-chain.
Filecoin’s Strengths, Challenges, and Opportunities
Filecoin holds a distinct position in the crypto landscape – especially in the DePIN (Decentralized Physical Infrastructure Networks) category. Understanding its current standing requires looking at its core strengths, the hurdles it faces, and where the biggest opportunities lie as it pushes toward sustainable value accrual.
What Sets Filecoin Apart
Filecoin brings a combination of physical infrastructure and economic design that differentiates it from other Layer 1s:
Hardware-Heavy Network: Unique especially among DePINs due to the total aggregate value of the capital it holds, with its deployed hardware serving as the economic base for productive monetization.
Established Brand & Distribution: Broad awareness and institutional credibility position Filecoin well for onboarding partners and developers.
Early Focus on Real Revenue: The ecosystem leads most crypto networks in thinking about sustainable monetization and generating cash flows into the Filecoin economy.
Key Challenges on the Road to Value Accrual
Despite these advantages, Filecoin faces several challenges as it aims to solidify its value loop and drive demand for FIL:
Infrastructure Gaps
Latency-sensitive use cases remain challenged by Filecoin’s block times and finality constraints
On-chain payments can feel clunky for end users, particularly when compared to the smoother experiences on more payment-oriented chains
Ecosystem Positioning and Alignment
As Layer 2s emerge, ensuring alignment with FIL’s value accrual model is crucial. Fragmented tokens and narratives could dilute FIL’s role if not carefully managed
Some new DePIN projects default to other L1s like Solana – Filecoin must remain proactive in competing for developer and user mindshare
Strengthening On-Chain Value Capture
Converting real-world demand (e.g., storage usage) into on-chain value remains a work-in-progress. FIL-based settlement is not yet the default for many clients, especially those operating in fiat or off-chain contexts.
DeFi and dynamic applications still face adoption friction, with FIL-denominated flows requiring better incentives and infrastructure.
Clarity and Proof of Progress
The ecosystem is in a “show me” phase – with more focus on proving real usage, rather than relying solely on forward-looking narratives
Complexity around tokenomics (e.g., Baseline vs. simple minting) remains a source of confusion, though this is likely to ease post-2026
Opportunities That Could Drive the Next Growth Cycle
If executed well, these strategic opportunities could solidify Filecoin’s role as a foundational layer for decentralized infrastructure:
Identify where value leaks from the ecosystem and redesign those flows to keep more within the Filecoin economy
Activate the Storage Provider Base
Help SPs monetize their deployed capacity through tools like Ramo and aligned L2s that translate hardware into cash flow.
Scale Through Layered Ecosystem Plays
Build derivative businesses, from compute networks to data marketplaces – atop established usage patterns.
As flywheel momentum builds, Filecoin can move into adjacent sectors like AI data infra, persistent rails, and verifiable compute.
Ensure Ecosystem Alignment
Define what “aligned L2s” look like and structure token incentives to reward symbiotic behavior.
Encourage system coherence to ensure long-term value accrual flows back to FIL
The Three-Step Pitch for Maximizing Value
To reach its full potential, Filecoin must go beyond narratives and demonstrate measurable, on-chain economic activity. The goal is to establish a value loop that drives real revenue, aligns with tokenomics, and reinforces the network’s long-term utility.
1. Anchor Non-Speculative Value On-Chain
The primary goal is to settle meaningful, revenue-generating activity on-chain to counter inflation and establish durable demand for FIL.
Services like “sealing-as-a-service” and running compute jobs on unused storage
Tools like CIDGravity, Storacha, Akave, Lighthouse, Curio, and Ramo make it easier for storage providers to convert hardware capacity into fiat-based revenue streams
On-chain settlement matters:
Enables visibility and measurement
Avoids fragmentation across L2s/subnets where value might accrue to other tokens instead of FIL, letting FIL remain as the “default currency” of value
2. Develop Derivative Businesses
Once core economic activity is on-chain, the next step is to build businesses that leverage this foundation.
These could include analytics, marketplaces, compute services, or data tooling tied to Filecoin’s storage layer
This helps translate ecosystem growth into value that extends beyond storage alone
3. Expand the Total Addressable Market (TAM)
With the value flywheel spinning, Filecoin can broaden its scope:
Serve more use cases (e.g., AI, big data, verifiable compute)
Attract new market segments beyond Web3
Strengthen its position as the default infrastructure for decentralized data
Conclusion
Filecoin’s challenge and opportunity lie in building a credible value accrual loop—anchored in real-world utility, on-chain revenue, and aligned ecosystem growth. Moving beyond narrative, its long-term success depends on turning external demand into sustained economic gravity.
To learn more about Filecoin Value Accrual, explore the following talk that happened during FDS-6:
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
Editor’s Note: This blogpost is a summarised repost of the original content published on 25 April 2025, by Molly Mackinlay from FilOz. Founded in 2024, FilOz is a team of 14 protocol researchers, engineers, TPMs, and community engineers focused on securing, upgrading, and expanding the Filecoin network.
Introduction
Nearly five years into its launch, Filecoin – now the world’s largest decentralized storage network, caters to more than one type of user. It serves a diverse range of customer segments where adoption and traction are already taking hold. A strong signal of product-market fit is paying demand – users who see enough value to pay for the service.
This blogpost offers a comprehensive look at Filecoin’s Ideal customer profiles (ICPs), analyzes current adoption trends, identifies high-opportunity areas based on payment signals and data volume, and outlines key strategies to drive future client success.
Identifying and Targeting Ideal Customer Profiles (ICPs)
At the heart of this demand push is a clear focus on Ideal Customer Profiles (ICPs) – specific categories of users the network is targeting for adoption. These ICPs represent use cases where Filecoin’s decentralized storage offers immediate value. Paying demand is one of the strongest indicators of product-market fit, and Filecoin is seeing traction in several key segments:
Four Core Vertical Markets:
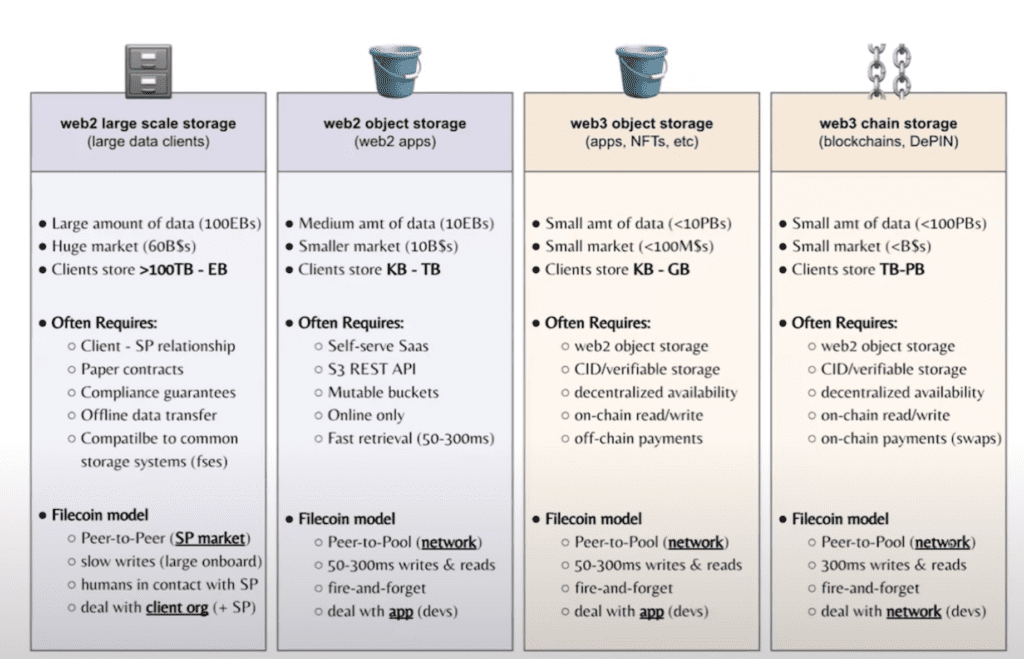
Large-Scale Data Clients (Primarily Web2): Traditionally focused on archival storage, now evolving toward faster reads/writes due to AI workloads. Think multi-exabyte archives with 24-hour retrieval tolerances.
Web2 Object Storage (e.g., AWS S3 alternative): Demands fast access, pricing competitiveness, Snowflake integrations, and strict controls over data locality—especially amid rising geopolitical tensions.
Web3 Object Storage: Adoption from decentralized websites, NFTs, social apps, and AI agents. Nascent potential includes data DAOs and decentralized AI use cases.
Web3 Chain Storage: Early traction from chains like Solana and Cardano, with data from Ethereum L2s scaling up to terabytes and petabytes. Strong potential, but more robust on-ramps are needed.
It’s also worth noting that beyond these four verticals, DePINs – particularly those collecting large volumes of consumer data are a key focus for 2025. In addition, edge computing and AI are emerging as high-potential sectors, driven by their rapidly growing, data-intensive workloads.
Mapping Filecoin’s Strengths to Its Most Promising Use Cases
To effectively serve the right customer segments, it’s essential to ask: what core strengths does the Filecoin network offer – and how can those be applied to the ideal customer profiles that stand to benefit most?
The following slide summarizes Filecoin’s strengths (and its learnings):
Building on Filecoin’s core strengths, the next slide highlights the key Ideal Customer Profiles (ICPs) driving real-world adoption today. It identifies which client segments are actively paying, which have rapidly growing data volumes, and where early adoption is gaining momentum:
While Filecoin has attracted paying users across various sectors, scaling from a few customers to a broad, thriving user base remains a key challenge. A major bottleneck is the lack of strong on-ramps specialized Layer 2 solutions – that serve high-volume, fast-growing ICPs like Web3 chain storage. This gap presents a clear opportunity for builders to develop targeted solutions.
Scaling client success ties directly to Filecoin’s 2025 core KPIs:
Revenue from on-chain paid storage deals: The main indicator of product-market fit. Despite off-chain payments, on-chain revenue is near zero. Bridging this gap with Proof of Data Possession (PDP) and Filecoin Web Services (FWS) is critical.
Growing a satisfied client base: Paying clients exist, but better transparency and dashboards are needed to track success.
Increasing service activity and value accrual: Tools like the USDFC stablecoin and FIP-100 protocol are in place, but accelerating on-chain payments and fee flows is essential.
To achieve this growth, several strategic steps are required, as outlined below:
Filecoin is actively transitioning from a capacity-focused infrastructure to a user-driven ecosystem. With a sharpened focus on ICPs, a maturing network of on-ramps, and powerful protocol innovations, it’s well-positioned to scale demand and adoption. Key challenges, especially around on-chain revenue and retrievability remain, but the foundation for sustained growth is rapidly taking shape.
To learn more about State of Client Adoption and ICPs for Filecoin, explore the following talk that happened during FDS-6:
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
Editor’s Note: This blogpost is a summarised repost of the original content published on 25 April 2025, by HQ Han from Ansa Research. Ansa Research is a research firm focused on distributed infrastructure. The firm covers digital networks aiming to rebuild how internet infrastructure operates.
Executive Summary
Filecoin has now entered the next phase of development, focusing on users, demand generation and adoption.
In this regard, Filecoin is not alone – while DePIN networks have now proven very successful at bootstrapping supply, the focus of this sector has also now turned towards demand.
There has been some exciting progress on Filecoin’s demand story:
Growth in the underlying demand for Filecoin’s services
We are seeing data clients in both Web2 and Web3 paying for storage on Filecoin. In some cases, Filecoin has been chosen in parallel or over Web2 providers.
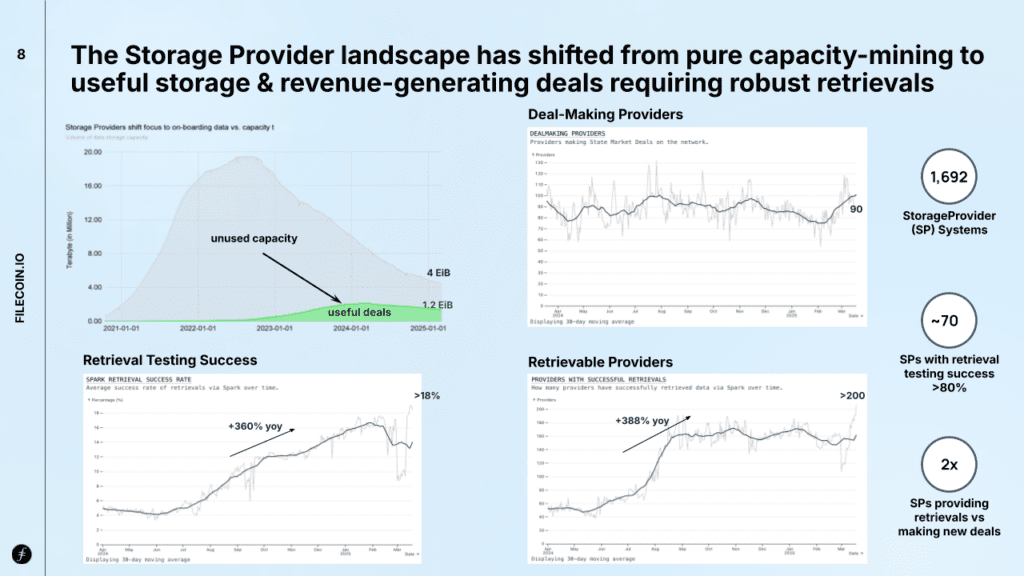
The storage provider landscape is reflective of this – whilst capacity and # of SPs have dropped, there has been an increase in quality and data utilization on the network – showing a shift in network resources towards demand
There is a pathway to scale
Filecoin is still expanding its core services to cater to demand with important protocol level upgrades – F3, PDP, and Filecoin Web Services (FWS)
New Filecoin-powered storage solutions have come to market (Akave, Storacha, Recall etc) – and all already charging for deals within their target markets
DeFi continues to scale on FVM – notably, FIL-backed stablecoins coming online
Storing more data on the network and creating multi-service APIs creates the building blocks to bring compute needs to the data
Filecoin is at an inflection point as its services mature to meet the demands of AI, enterprise & nation state focus on data locality, and global cost-cutting driving orgs away from costly Web2 cloud providers.
This blog post examines Filecoin’s adoption, including milestones and use cases, its scaling path via infrastructure, tooling, and coordination, and cryptoeconomics, covering incentives, token dynamics, and network sustainability.
Adoption & Client Demand
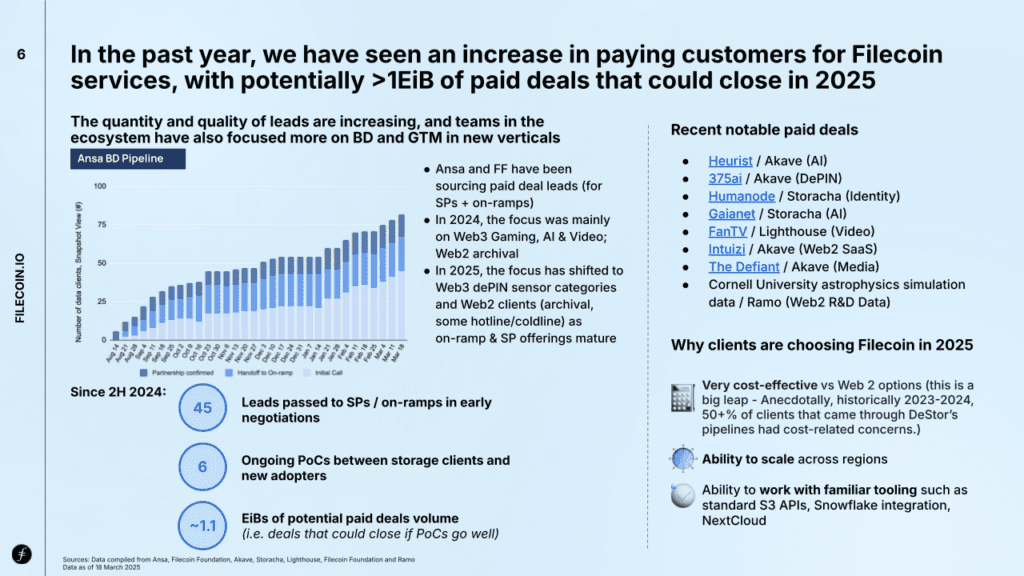
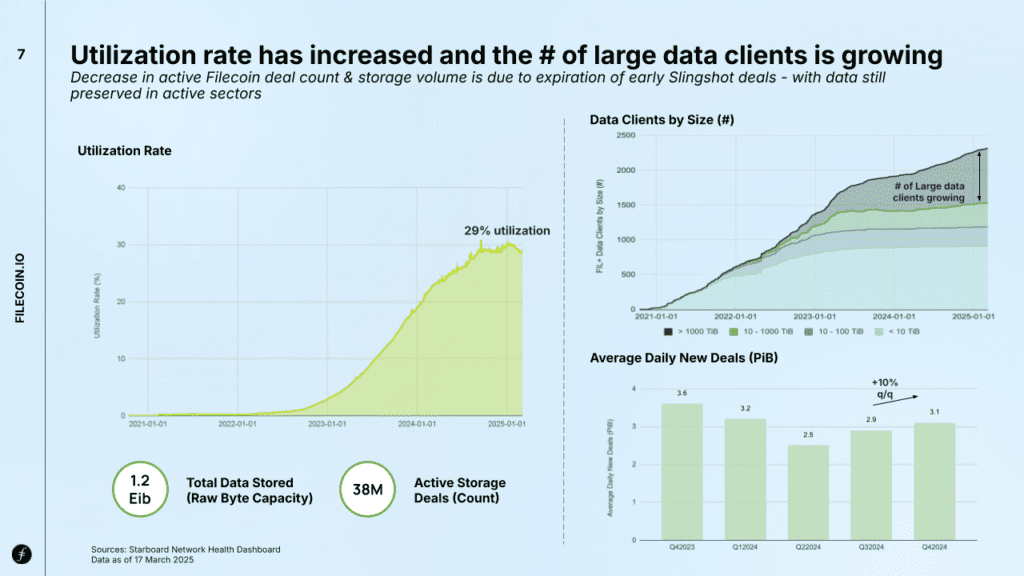
Over the past year, Filecoin has seen a rise in paying customers, with projections suggesting over 1 EiB of paid storage deals could close in 2025. This would raise the network’s utilization from its current 29% to nearly 100% with fully paid usage.
The number and quality of leads are growing, driven by efforts from teams like Ansa Research and the Filecoin Foundation, who are actively sourcing paid deals for on-ramps and Storage Providers. Business development has also shifted focus toward high-potential DePIN categories, particularly those collecting large volumes of consumer data as well as Web2 clients with archival and hot/cold storage needs.
Filecoin’s network utilization has risen to around 29%, signaling increased demand. A growing number of large-scale clients (storing over 1,000 TiB) possibly in the enterprise and/or long-term archival space, demonstrates that efforts by on-ramps and Storage Providers (SPs) are on the right path.
After earlier declines as the network shifted its focus from generating supply to generating demand, average daily new deals have recently increased by over 10% from Q3’24 to Q4’24.
The Storage Provider (SP) landscape is shifting from a focus on raw capacity to delivering useful, client-driven storage. In its early phase, the network prioritized onboarding as much storage as possible, often without regard for actual usage or retrievability. Now, as Filecoin emphasizes demand generation and adoption, SPs are adapting by pursuing paid deals and ensuring robust data retrieval. This marks a clear move from quantity to quality, with incentives increasingly aligned to real-world client needs – reflected in a 388% year-over-year surge in the number of SPs achieving successful retrievals.
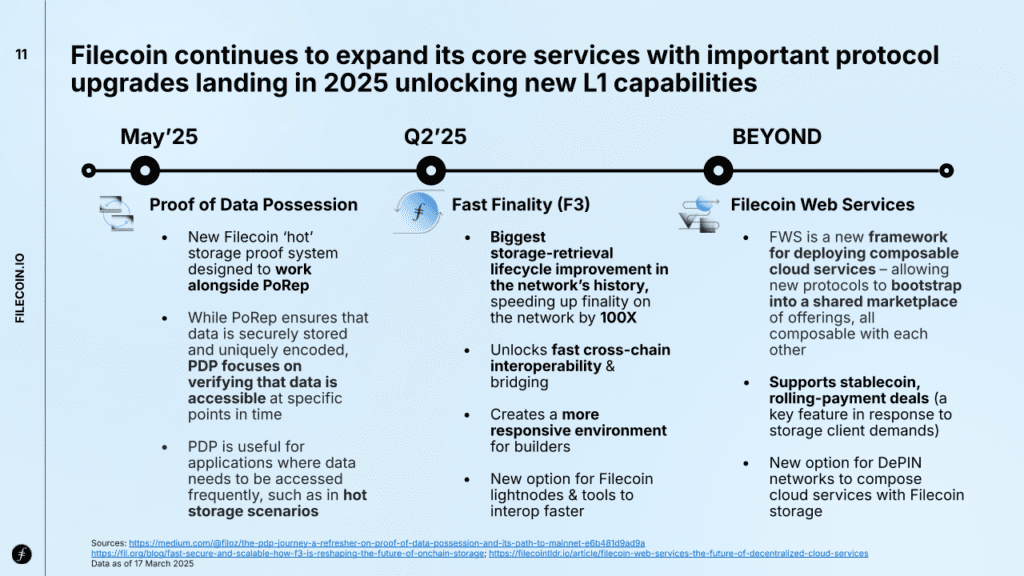
The network’s path to scale is envisioned along three main lines:
Expanding core protocol capabilities with the introduction of Proof of Data Possession (PDP), Fast Finality (F3), and Filecoin Web Services (FWS)
Launching new on-ramps and Layer 2 solutions to support vertical-specific adoption
Improving economic efficiency through decentralized finance (DeFi)
1. Expanding Core Protocol Services
Filecoin will go through key protocol updates, primarily;
Proof of Data Possession (PDP) – that has shipped as of 8th May 2025, and Storage Providers can participate in PDP SPX, a short-term initiative to onboard select Storage Providers to test, validate, and demonstrate Proof of Data Possession (PDP).
Fast Finality (F3) – that has arrived early and went live on Filecoin Mainnet as of April 2025, bringing 100x improvement on transaction speeds
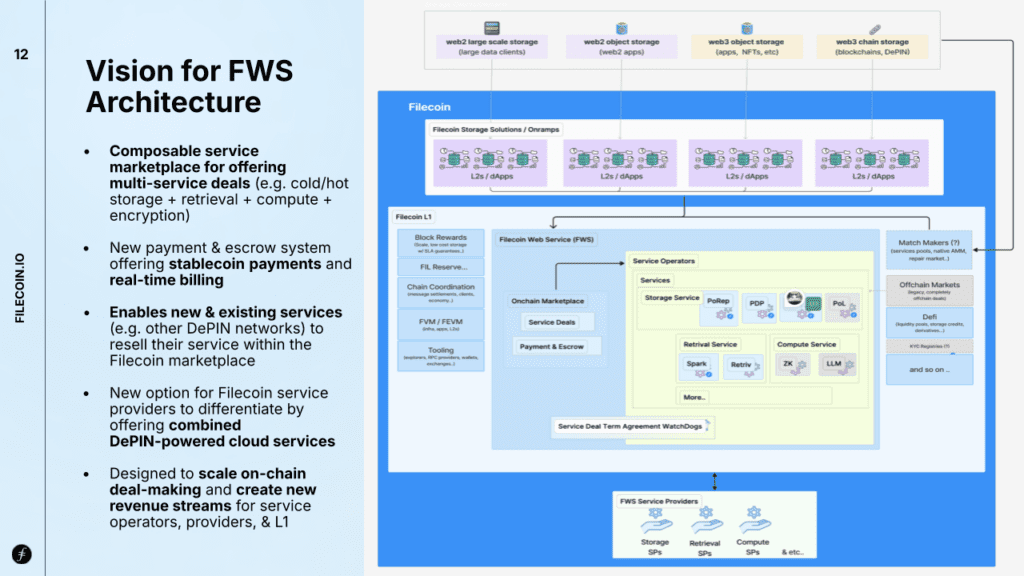
Filecoin Web Services (FWS) – a composable service marketplace for offering multi-service deals
Introduced last year as part of Filecoin’s broader vision, Filecoin Web Services (FWS) marks a major step toward expanding the network’s capabilities beyond storage. At its core, FWS is a composable service marketplace that enables users to bundle multiple services—such as cold and hot storage, retrieval, compute, and encryption—into a single deal.
FWS aims to offer a more flexible and integrated alternative to traditional Web2 cloud platforms. It also opens the door for other DePIN networks to offer and resell their services within the Filecoin ecosystem. With integrated payments and escrow, FWS supports the creation of customizable service combinations, enhancing utility for both consumers and enterprises.
A key part of Filecoin’s scaling strategy is the emergence of new storage on-ramps, functioning like Layer 2s – that are launching mainnets and targeting specific verticals. These startups tailor Filecoin’s storage stack to meet the needs of niche markets, helping to establish beachhead use cases. Notable examples include:
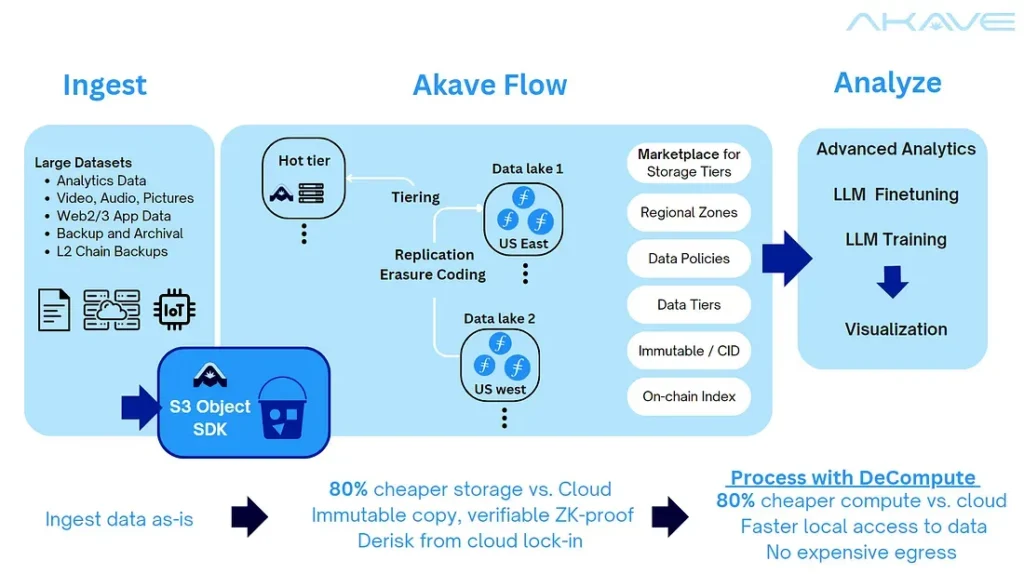
Akave: Focused on Web2 enterprises, Akave offers a hot storage layer on top of Filecoin, supporting archival, hot/cold storage, and S3 integrations. They’ve also integrated with Snowflake.
Storacha: Targeting Web3 applications in social, AI, and identity, they specialize in storage solutions for decentralized platforms.
Recall: Aimed at the AI sector, specifically towards AI agent storage and data processing.
Filecoin’s DeFi ecosystem is growing, playing a key role in improving economic efficiency across the network. A major focus is on stablecoins, which help retain economic activity within the ecosystem. Secured Finance has introduced USDFC, a FIL-backed stablecoin that allows FIL holders and Storage Providers to use their tokens as collateral instead of selling them—similar to MakerDAO on Ethereum.
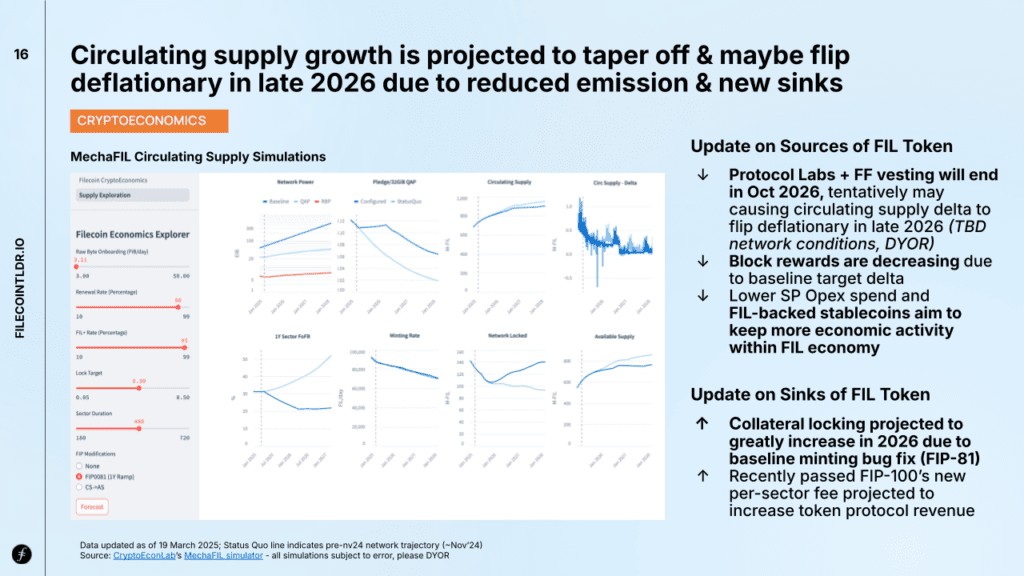
The central forecast: FIL’s circulating supply growth is expected to slow and may turn negative or deflationary by late 2026. This shift stems from a combination of reduced token issuance and increased demand sinks that lock or remove FIL from circulation.
Supply-Side Pressures Easing
Several key developments are reducing new FIL issuance:
Vesting Completion: Token vesting from early stakeholders, including Protocol Labs and the Filecoin Foundation, ends in October 2026 – removing a major source of new tokens.
Decreasing Block Rewards: FIL block rewards follow a declining emission schedule by design.
FIL-Backed Stablecoins: Stablecoins like USDFC by Secured Finance allow FIL holders to use tokens as collateral instead of selling, keeping more value within the network and reducing sell pressure.
Demand-Side Sinks Growing
At the same time, FIL demand is increasing through new utility and locking mechanisms:
Rising Collateral Requirements: Storage Provider collateral is set to increase in 2025, partly due to a fix under FIP-81 that enhances locking behavior.
Increased Protocol Revenue: FIP-100 is projected to boost FIL-denominated revenue, much of which is burned or otherwise removed from circulation.
Together, these trends suggest a pivotal moment in Filecoin’s economic evolution: a potential transition to a deflationary supply model, signaling a tighter and potentially more valuable FIL economy.
[Disclaimer: Circulating supply analysis is based on a 3rd party model: https://mechafil-jax-web-levers.streamlit.app/ These models are based on many assumptions, and should not be relied upon as the source of truth. There are many factors that can and will affect the actual numbers. Simulations should not be relied upon and are for illustrative purposes only. DYOR and adjust the model yourself, or build your own models in Dune.]
For those looking to dive deeper into the Filecoin ecosystem, Ansa Research has compiled a curated directory of key metrics and data sources. These resources provide essential insights into network health, development trends, and adoption signals – making them useful for both regular monitoring and deeper research.
Whether you’re tracking protocol upgrades, storage deals, or adoption patterns, this data directory is a valuable starting point for your own analysis.
Filecoin is entering a new phase centered on demand, adoption, and long-term sustainability. With supply successfully bootstrapped, focus has shifted to real usage – evidenced by rising paid storage deals, potentially exceeding 1 exabyte by 2025, and a shift toward higher-quality, retrievable data.
Key upgrades like Proof of Data Possession (PDP), faster finality (F3), and new Layer 2 solutions are unlocking capabilities across data and DeFi, including FIL-backed stablecoins that help retain value within the network.
At the same time, token issuance is set to slow, with vesting ending in late 2026 and block rewards declining – while demand sinks like collateral locking (FIP-81) and protocol revenue (FIP-100) increase. Together, these trends suggest a potential shift to a deflationary FIL supply and a more mature, sustainable network economy.
To listen to the entire talk by HQ Han (Ansa Research) at FDS-6, watch here on YouTube:
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
Editor’s Note: This blogpost is a summarised repost of the original content published on 26 March 2025, by Luca from FilOz. Founded in 2024, FilOz is a team of 14 protocol researchers, engineers, TPMs, and community engineers focused on securing, upgrading, and expanding the Filecoin network.
Introduction
As Web3 applications mature, fast and reliable access to data becomes just as important as storing it. Whether it’s video streaming, serving assets for dApps, or powering AI agents with on-demand data, retrievability is a foundational piece of user experience.
Unlike traditional cloud providers where data retrieval is instant and guaranteed by a centralized service (often aided by CDNs), retrieval of data in Web3 introduces new challenges — spanning considerations around network performance, data redundancy, storage provider reliability, and incentive alignment. Filecoin has built the world’s largest decentralized storage network and how to tackle retrievals on that foundation deserves some exploration. How should Filecoin evolve its retrieval capabilities in a decentralized internet? What is the best approach for its users?
This guide aims to unpack the state of Retrievability on Filecoin, exploring where we are today and where improvements are needed. What we will aim to cover:
Overview of Retrievability on Filecoin, including key strategies, challenges, and improvements
Explore retrieval strategies and protocols, their guarantees, and limitations
Outline payment models and how SPs and clients can select each other
Highlight potential protocol-level improvements to enhance retrievability
Retrievability on Filecoin
Filecoin enables decentralized storage, allowing clients to store data with Storage Providers (SPs) and retrieve it on demand. Unlike storage, which is provable through Proof of Replication and Proof of SpaceTime, retrieval is a separate process that isn’t always provable, depending on protocols and strategies addressing various challenges.
Retrievability on Filecoin is influenced by factors such as:
Network and SP performance
Data availability
Retrieval optimization protocols
There is no one-size-fits-all solution for retrievability. The best strategy depends on a client’s needs, including retrieval speed, reliability, and cost constraints. Clients can choose simple retrieval from a single SP for non-critical data or more complex solutions like redundancy, SLAs, or off-chain backups for mission-critical files. Advanced protocols, like Spark or CDN integration, offer higher performance but come with added costs or complexity.
Trust plays a crucial role in decentralized storage networks like Filecoin. Without trust, retrieval failures or delays can occur, especially with payment strategies like upfront payments. A CDN-like solution (e.g., retriev.org) could address these trust challenges by:
Providing monitoring services to ensure SPs meet obligations
Offering arbitration to resolve disputes and penalize non-performing SPs
Ensuring retrieval promises are backed by financial incentives and penalties
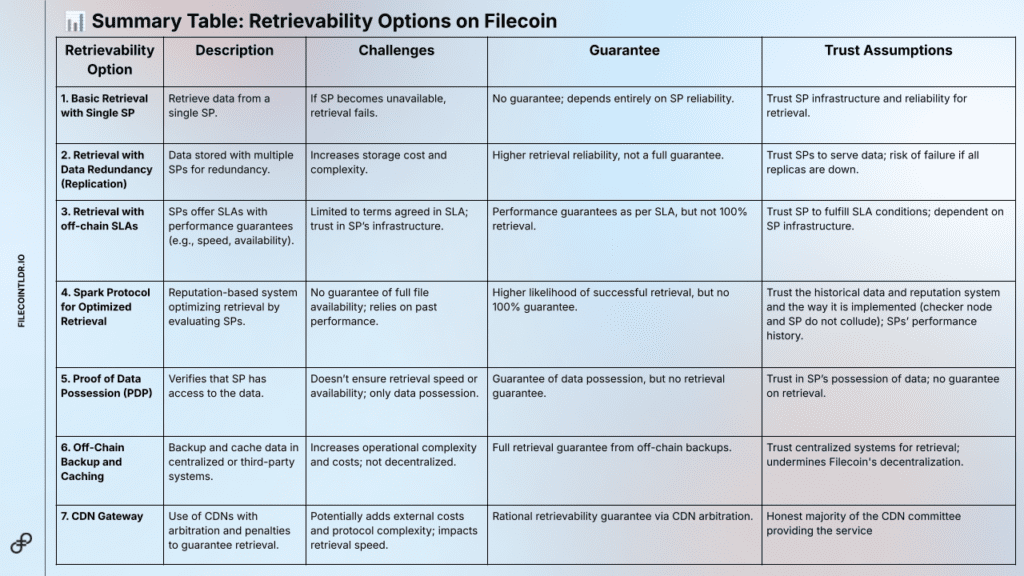
Filecoin offers various retrievability options, from redundancy models to retrieval networks and off-chain solutions. Below is a summarized table of these options:
For the full breakdown on Retrievability Options on Filecoin, read here.
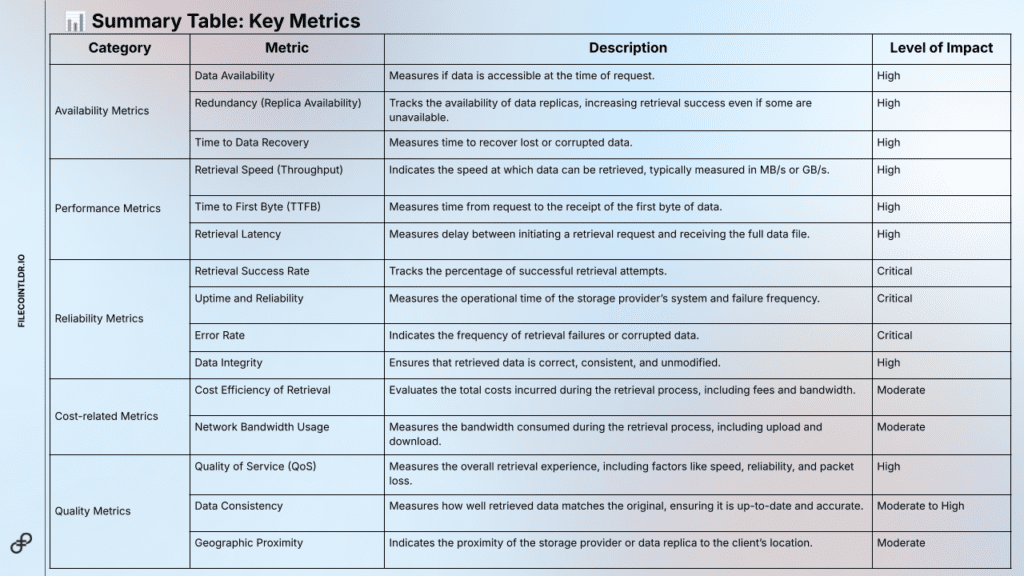
Key Metrics
When evaluating retrievability, clients need to consider several performance metrics that measure different aspects of the data retrieval process. These metrics ensure that data is not only stored but also accessible and retrievable efficiently when required. Key metrics include:
Availability Metrics: Measure the likelihood of data being accessible and quickly recoverable when issues arise. High availability and redundancy ensure retrieval even if some systems or replicas fail.
Performance Metrics: Assess retrieval speed and responsiveness, impacting user experience. Factors like throughput and latency are influenced by network bandwidth and data availability.
Reliability Metrics: Reflect the consistency and stability of data retrieval, including success rate, error rate, and data integrity. High uptime ensures high availability, while a low error rate guarantees data accuracy and successful retrieval attempts.
Cost-related Metrics: Help balance performance with cost efficiency, particularly in managing retrieval speed, bandwidth usage, and associated costs.
Quality Metrics: These metrics measure the overall quality of the retrieval process, ensuring a satisfactory user experience.
By grouping the metrics into these categories, clients can evaluate retrievability from multiple dimensions, ensuring efficient, reliable, and cost-effective data access. Below is a comprehensive list of key retrievability metrics, grouped by their category:
Retrievability on Filecoin combines payment options (how value is transferred) with payment strategies (when and under what terms payments occur). This modular structure allows clients and Storage Providers (SPs) to tailor agreements based on performance, trust, and cost considerations.
Selecting Storage Providers (SPs) for retrievability in Filecoin requires balancing control, cost, reliability, and trust. This process involves two key aspects: the deal-making process and the selection mechanism. Just as clients must carefully choose SPs, SPs also evaluate which client retrieval requests to fulfill, following the same two key components—deal-making and selection mechanisms.
Deal-Making Process
The deal-making process determines how clients and Storage Providers (SPs) establish retrieval agreements, balancing control, efficiency, and risk. It involves two key approaches:
Direct Negotiation: Clients and SPs engage directly to define retrieval terms, including cost, performance guarantees, and service conditions. This method offers full control but requires manual effort and carries risks such as extended negotiations, misunderstandings, and potential SP unreliability.
Automated or Delegated Deal-Making: Intermediaries or automated systems—such as content delivery networks (CDNs), smart contracts, or auction systems—facilitate the process. This reduces manual effort, optimizes terms based on real-time data, and enables market-driven pricing. However, it can introduce additional costs, reduced control, and reliance on third-party mechanisms for enforcement and dispute resolution.
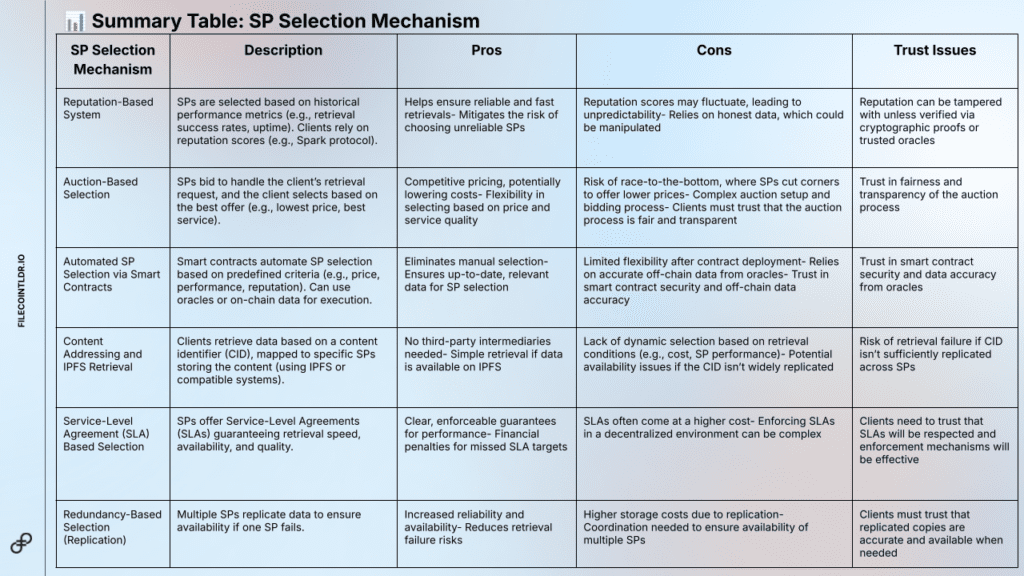
SP Selection Mechanisms (POV of a Client)
Once the deal-making process is determined, the actual selection mechanism defines how the SPs are chosen. These can range from reputation-based systems to auction-based or automated selections.
Below is summarised table on the various selection mechanisms:
For the full breakdown on SP Selection Mechanism, read here.
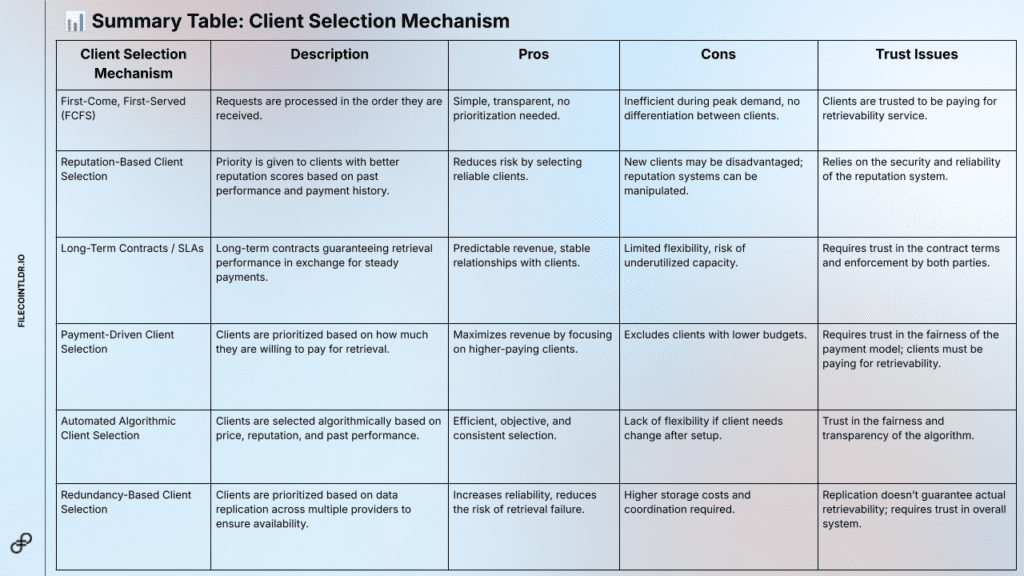
Client Selection Mechanisms (POV of a Storage Provider)
Once the deal-making process is determined, the client selection mechanism helps further narrow down on which clients’ retrieval requests the SP wishes to fulfill. Below is a summarised table to cover the various mechanisms:
For the full breakdown on Client Selection Mechanism, read here.
Next Steps
Retrievability guarantees for data stored on the Filecoin Network is essential for its long-term success and sustainability. However, we also recognize that each user may have distinct needs, preferences, and requirements when it comes to data accessibility and security guarantees.
To address this, we foresee a modular approach that allows users to select from a diverse range of services and combine them in a way that meets their specific retrievability and reliability goals. This flexibility will enable users to tailor their storage solutions to their unique use cases, ensuring both customization and scalability.
A promising path forward for enhancing retrievability guarantees on the Filecoin Network involves integrating advanced protocols and tools. By leveraging technologies and protocols like CDN Gateways, reputation systems, smart contract-powered storage solutions and incentives, we can create a more robust and reliable infrastructure.
These combined innovations will not only improve data accessibility and security but will also foster the overall growth and resilience of the Filecoin ecosystem.
For more pieces from FilOz, check out their Medium page here.
To stay updated on the latest in the Filecoin ecosystem, follow the @Filecointldr handle or join us on Discord.
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
2024 has been a pivotal year for Filecoin, with significant progress in the Filecoin Virtual Machine (FVM), Storage, Retrievals and Compute. In this blogpost, we’ll recap the key milestones of 2024 and take a look at the major growth drivers shaping Filecoin’s path into 2025.
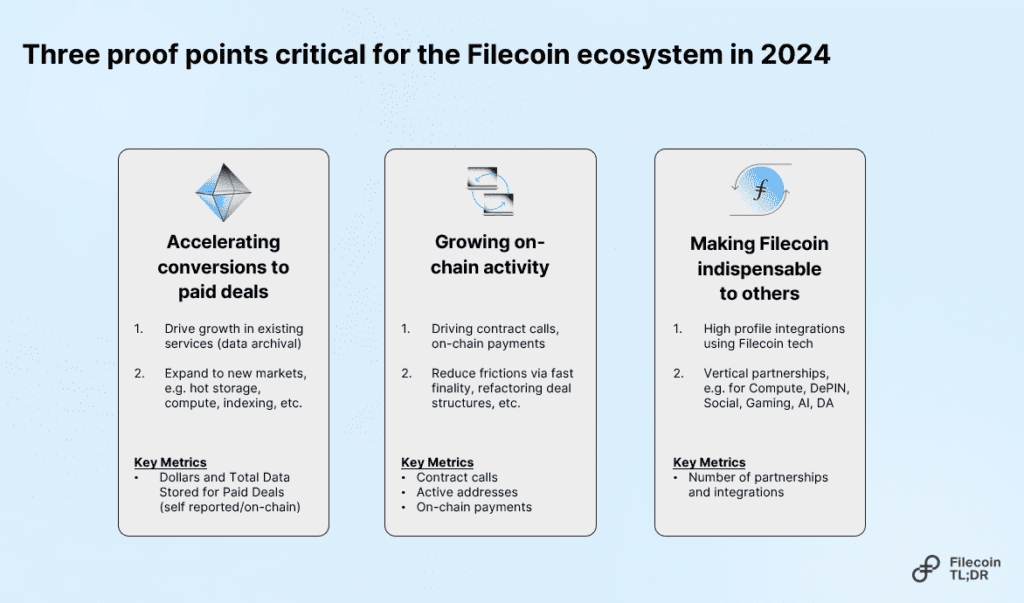
Accelerating Paid Deals: Boosting paid services (storage, retrieval, compute) on Filecoin to generate cashflow for service providers. This helps to support more sustainable hardware funding beyond token incentives.
Growing On-Chain Activity: Increasing activity through programmable services, DeFi, and new use cases.
Becoming Indispensable: Establishing Filecoin as an integral component of other projects and businesses.
These priorities are not mutually exclusive – they layer onto each other and are all signs that the Filecoin ecosystem is growing increasingly valuable.
So how did we fare across these priorities in 2024?
1. Accelerating Paid Deals
Paid Deals is an ecosystem-level metric that reflects the volume of paid services within the Filecoin network. FilecoinTLDR is currently tracking this metric here.
In 2024, Filecoin made significant strides in accelerating paid deals by reducing friction for businesses entering the ecosystem, with key advancements like the development of Proof of Data Possession (PDP) and the emergence of Layer 2 solutions.
Enabling Efficient Hot Storage with PDP
Projected for Q1 2025, Proof of Data Possession (PDP) introduces a new proof primitive to the Filecoin network, marking the first major proof development since Proof of Replication (PoRep) and Proof of Spacetime (PoSt). Unlike PoRep, which excels at cold storage through sealed sectors, PDP is designed for “hot data”, which is data that needs fast and frequent retrieval.
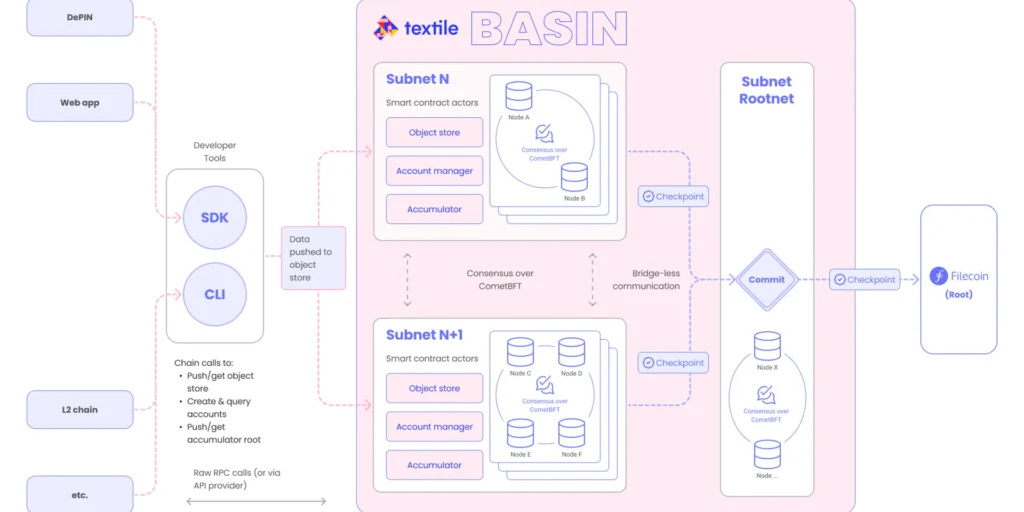
This new proof type enables cost-effective “cache” storage on Filecoin without sealing and unsealing, enabling rapid data onboarding and retrieval. PDP opens the door for a new class of storage providers focused on hot storage and fast retrievals, benefiting onramps like Basin, Akave, and Storacha.
Scaling Filecoin with L2s
In 2024, we saw a rise in Layer 2 solutions built on top of Filecoin (We also covered this in our earlier blogpost “State of L2s on Filecoin”). L2s like Basin, Akave and Storacha enable both horizontal and vertical scaling with secure, customizable subnets. These L2s enhance Filecoin by unlocking new use cases: including managing data-intensive workloads, supporting AI and unstructured data, powering gaming and privacy-focused applications — all of which create more opportunities for paid deals.
2. Growing On-Chain Activity
Filecoin has made notable progress in accelerating on-chain activity through the FVM, which spurred growth in its DeFi economy. The proposed Filecoin Web Services (FWS) and launch of FIL-collateralized stablecoins are set to further boost this momentum.
As of December 16 2024, more than 4,700 unique contracts have been deployed on FVM, enabling over 3 million transactions. DeFi activity on FVM saw average net deposits exceeding 30M FIL ($200M), driven by staking, liquid staking, and DEXs, with GLIF leading at 62%, followed by FilFi (10%) and SFT Protocol (9%). Net borrows averaged 26M FIL ($173M), highlighting strong growth in Filecoin’s DeFi ecosystem.
FIL-Collateralized Stablecoin for the Filecoin Ecosystem
USDFC is a FIL-backed stablecoin launched by Secured Finance in Q4 2024 to address key challenges in the Filecoin ecosystem. It introduces stability to a network previously lacking stablecoin options, reducing volatility and enhancing value storage, much like DAI did for Ethereum.
By allowing FIL holders and SPs to collateralize their assets for USD, USDFC helps cover operational costs without selling FIL, preserving asset value and network support. It also boosts liquidity in lending markets by providing FIL-backed stablecoin liquidity, driving more efficient capital flows within the Filecoin ecosystem.
3. Becoming Indispensable
DePIN gained prominence, with Filecoin strengthening its position through key partnerships with AI and compute projects. Meanwhile, on-chain archival received significant recognition through major on-ramp partnerships.
“…thanks to Filecoin for building an awesome decentralized archive layer. “ –Anatoly (Solana Co-Founder)
Notable On-Ramps of 2024
At Solana Breakpoint this year, Filecoin founder Juan Benet highlighted how Filecoin’s zero-knowledge (ZK) storage is securing the entire Solana ledger.
Similarly, Cardano apps now have the opportunity to boost data redundancy and decentralization through the Blockfrost integration with Filecoin.
SingularityNET’s integration with Filecoin (via Lighthouse) emphasizes the growing need for scalable and cost-effective storage in the AI-driven era, where managing vast amounts of data efficiently is critical.
These meaningful partnerships help signal Filecoin as a key player in both the Chain Archival and AI narratives.
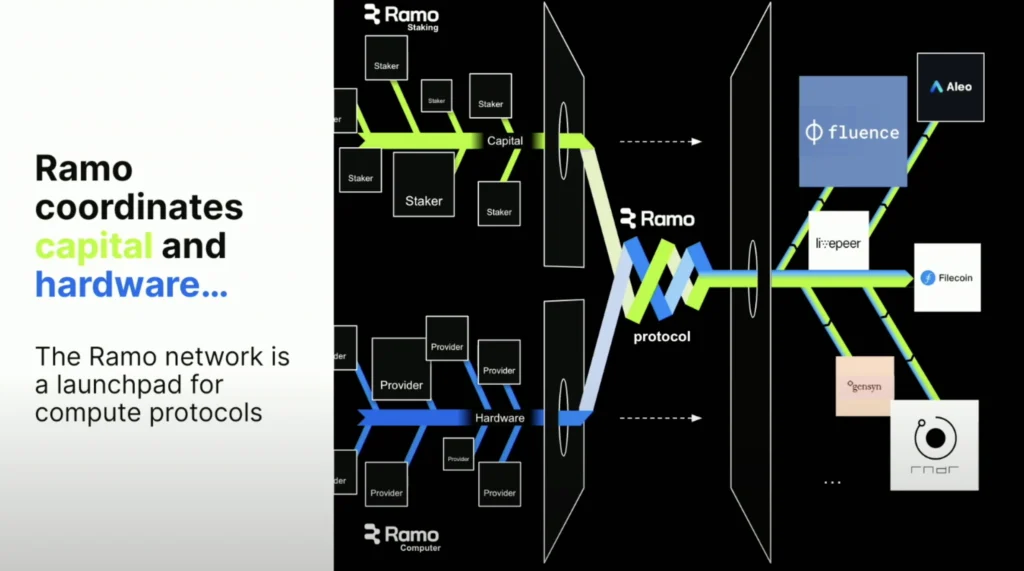
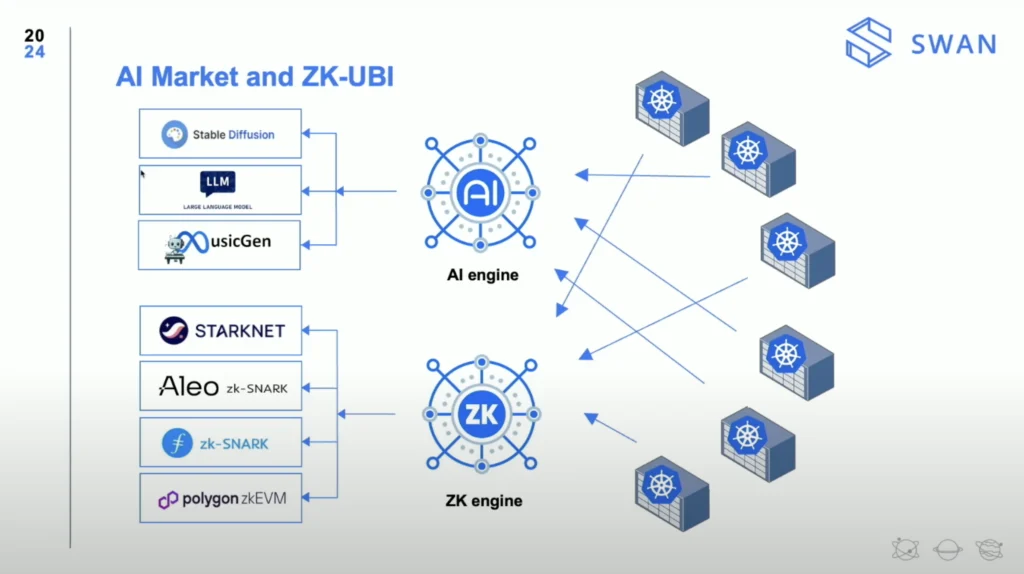
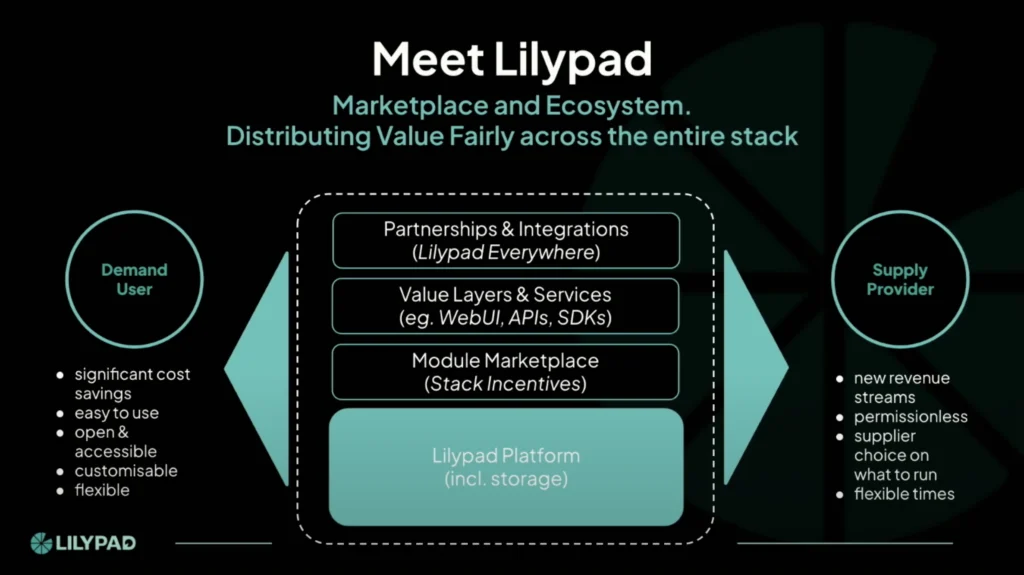
This year, Filecoin has positioned itself as a key player in the growing field of Decentralized AI. The onset of projects within the ecosystem like Ramo (network participation), Bagel (AI & cryptography research), Swan Chain (AI training and development), and Lilypad (distributed compute for AI) highlight Filecoin’s expanding role in powering AI innovation.
2024 Filecoin Challenges
Despite the immense progress, we noted some challenges that the community faced. Though bearing in mind that Web3 products are still very early, and the problem statement of forming a credible alternative to the centralized cloud is a huge one.
Product Market Fit:
Roadblocks like limited retrievability and high costs (driven by data replication), challenge the efficiency of the Filecoin network.
There is a need to make payments easier by allowing transactions directly on the Filecoin network, using methods like stablecoins or flexible payment options.
Improving visibility into the onboarding process and using customer data can help refine strategies and boost performance in key areas.
Building a Sustainable Economic Model + Stronger Economic Loops:
Viewing Filecoin as an island economy highlights its focus on accruing value by exporting goods and services while also keeping as much value as possible within the network by minimizing outflows.
A key challenge lies in reducing external outflows while finding ways to boost exports and capture more demand within the ecosystem.
Ensuring that transactions remain on-chain is equally crucial to strengthening this economic model and creating stronger economic loops.
Filecoin’s 2025 Outlook
Looking ahead to 2025, Filecoin’s evolution continues. Here are three key themes that could drive transformative growth for the network while addressing the 2024 challenges outlined above.
1. Accelerating Filecoin by 450x with Fast Finality (F3)
Fast Finality (F3), is one of the most impactful upgrades to Filecoin’s consensus layer since the launch of its mainnet. By drastically reducing transaction finality times, F3 overcomes a key limitation of the network’s original consensus mechanism. This enhancement is scheduled to go live on the mainnet in Q1 2025.
Old vs. New Finality:
Before F3, Filecoin’s consensus mechanism ensured secure block validation but required 7.5 hours (900 epochs) to finalize transactions, which was too slow for applications like smart contracts or cross-chain bridges.
With F3, transactions can now optimistically finalize in minutes—a 450X improvement.
What this means for Filecoin:
Enhanced Speed & UX: Transactions finalize within minutes, enabling low-latency applications and eliminating the long waits previously experienced.
Expanded Use Cases & Accessibility: L2 subnets like Interplanetary Consensus (IPC), Efficient smart contracts and decentralized applications, Blockchain bridges for interoperability with other chains.
Ultimately, this allows Filecoin to improve its usability across a wider variety of applications.
2. Moving Beyond Storage with FWS
Filecoin Web Services (FWS), emerged this year as a pivotal concept. It represents a strategic shift for Filecoin, expanding its scope from primarily a decentralized storage network to a broader marketplace for blockchain-based cloud services. This diversification can attract a wider range of users and use cases, potentially creating more positive economic loops within the network. Here are some pointers on why FWS should be on your radar:
Strengthening Filecoin’s Competitive Edge: FWS will introduce features like Programmatic SLAs (which automate and enforce service agreements through smart contracts, ensuring clear performance expectations and penalties) and Verifiable Proofs(which provide cryptographic evidence of service delivery, allowing clients to independently verify service execution).
Expands Filecoin’s Capabilities: Goes beyond Proof of Replication (PoRep) by adding Proof of Data Possession (PDP), enabling robust hot storage use cases. PDP will help improve data retrievability, a crucial factor in achieving product-market fit that has been widely discussed within the Filecoin community this year.
Positions Filecoin as a leading platform in the decentralized web: FWS will facilitate the integration of multiple networks and protocols, creating a cohesive marketplace for storage, compute, bandwidth, and other services. This could make Filecoin a key player in the growth of the decentralized web.
FWS is currently a concept in development, with a new storage service featuring PDP (v0) underway. Following this milestone, the development of the FWS marketplace will begin with its expected launch in Q1 2025.
3. Unlocking new value streams in Filecoin
As a Layer 1 blockchain, Filecoin primarily generates revenue through gas fee burns (which happen when chain resources are used or when faults arise). However, relying on gas fee burns as a main source of revenue is not scalable and more importantly increases operational expense costs as well as service costs.
A sustainable approach involves value returning to the Filecoin economy through the use of services in the FWS marketplace, fostering a more scalable and balanced revenue model. A proposed value accrual mechanisms includes:
FWS Fees: Commission (%) charged based on the transaction volume in the marketplace.
Service Fees: Applied when a user accesses a service or a vendor provides one
SLA Penalties: Imposed on service providers who fail to meet agreed-upon performance standards
This shift promises a more robust and diversified revenue stream, ensuring Filecoin’s continued relevance and profitability in the evolving market.
Final Thoughts
As data grows in value, we expect advancements in privacy-preserving machine learning, data-driven business models, and the increasing role of AI agents in unlocking decentralized storage’s potential.
Looking towards 2025, with the upcoming Fast Finality (F3) launch on the mainnet and the continued development of Filecoin Web Services, Filecoin is set to play a central role in shaping the future of data and AI within decentralized ecosystems. We expect to see these advancements positioning Filecoin beyond storage and unlocking a sustainable economic model through new revenue streams generated by FWS.
To stay updated on the latest in the Filecoin ecosystem, follow the @Filecointldr handle or join us on Discord.
Many thanks to HQ Han and Jonathan Victor for reviewing and providing valuable insights to this piece.
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
At first, the convergence of artificial intelligence (AI) and blockchain seemed like an awkward pairing of buzzwords—a notion often met with skepticism among early adopters. But in merely a year’s time, decentralized AI has evolved from being an obscure idea to one that is central to conversations around the Web3 environment. Such swift transformation owes its momentum to a few crucial elements:
Influence of AI: AI is set to significantly impact how we interact with the world. As AI agents grow more sophisticated, they will manage tasks like financial transactions and personal coaching. This evolution raises important questions about control and governance in AI development.
The Risks of Centralized Power: Centralized AI models controlled by a few tech giants pose serious risks, including bias, censorship, and data privacy concerns. This concentration of power stifles innovation and creates vulnerabilities, as highlighted by the recent security breach at Hugging Face.
The Demand for an Inclusive AI Ecosystem: Decentralized AI offers a pathway to a more equitable and accessible AI landscape by distributing computational processes across various systems. Key benefits include:
Reduced Costs: Lower barriers enable smaller developers and startups to innovate in AI.
Enhanced Data Integrity: Verifiable data provenance increases transparency and trust in AI models.
Combating Censorship: Aligning AI development with market needs fosters a more democratic technological environment.
These points highlight the value of an alternative approach to centralized AI.
Decentralized AI comprises 3 pillars: leverages idle computing power from users, utilizes secure decentralized storage, and implements transparent data labeling.
Decentralized Storage: Utilizing decentralized storage networks like Filecoin ensures secure and verifiable storage for large datasets.
Decentralized Compute: By leveraging idle computing power from individual users and distributing tasks across a network, Decentralized AI makes AI development more accessible and cost-effective.
Decentralized Data Labeling and Verification: Transparent and verifiable data labeling processes help ensure data quality and reduce bias, fostering trust in AI systems.
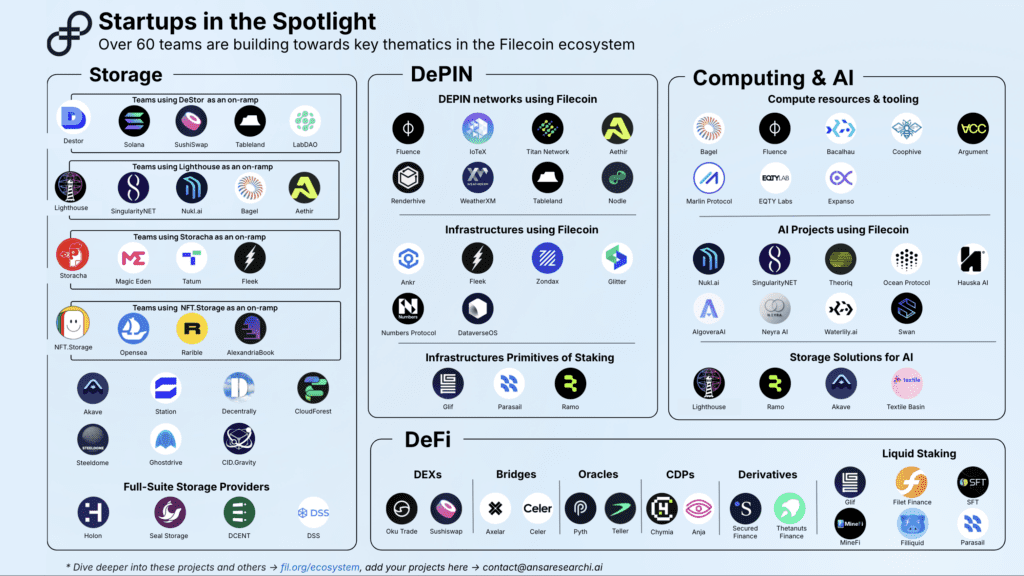
A closer look: Decentralized AI Projects in the Filecoin Ecosystem
To take a closer look into how the Web3 stack can offer benefits to the AI space, we’ll explore the various approaches 4 decentralized AI projects are taking. These projects are utilizing some or all of the pillars of decentralized AI as outlined above.
Ramo plays a crucial role in powering AI workloads by coordinating capital and hardware. By merging resources from various providers, Ramo facilitates the execution of complex tasks such as storage, SNARK generation, and computation, while allowing hardware resources to be jointly funded across multiple networks.
Multi-Network Jobs: Ramo supports jobs across multiple networks (e.g., read from Filecoin, process on Fluence, write back to Filecoin), helps maximize hardware providers’ revenue and reduces coordination complexity.
Swan Chain – Decentralized AI Training and Deployment (Funding Stage: Seed)
Swan Chain is a decentralized compute network, connecting users with idle computing resources for AI tasks like model training. Filecoin serves as its primary storage layer, ensuring secure, transparent, and accessible storage of AI data, aligning with the principles of decentralized AI.
Decentralized Compute Marketplace: Swan Chain aggregates global computing resources, offering a cost-effective alternative to centralized cloud services. Users can bid for computing jobs, and Swan Chain matches them with suitable providers based on requirements.
Filecoin Integration for Secure Data Storage: Swan Chain utilizes Filecoin and IPFS to securely store AI models and outputs, ensuring transparency and accountability in the AI development process.
Support for Diverse AI Workloads: Swan Chain supports various AI tasks, including model training, inference, and rendering, with examples like large language models and image/music generation.
Lilypad – Distributed Compute for AI (Funding Stage: Seed)
Lilypad aims to build a trustless, distributed compute network that unleashes idle processing power and creates a new marketplace for AI, machine learning, and other large-scale computations. By integrating Filecoin and utilizing IPFS for hot storage, Lilypad ensures secure, transparent, and verifiable data handling throughout the AI workflow, supporting an open and accountable AI development landscape.
Job-Based Compute Matching: Lilypad’s job-based model matches user-defined compute needs (e.g., GPU type, resources) with providers, creating a marketplace for developers to share and monetize AI models within the decentralized AI ecosystem.
Bagel – AI & Cryptography Research Lab (Funding Stage: Pre-Seed)
Bagel is an AI and cryptography research lab creating a decentralized machine learning ecosystem that enables AI developers to train and store models using the computing and storage power of decentralized networks like Filecoin. Its innovative GPU Restaking technology enhances Filecoin’s utility for AI applications by allowing storage providers (SPs) to contribute to both storage and compute networks simultaneously, thereby expanding support for AI developers and generating new revenue opportunities for SPs.
Increased Revenue for Filecoin SPs: Bagel helps storage providers monetize both storage and compute resources, boosting their income and incentivizing greater network participation.
Optimized Compute Utilization: With dynamic routing, Bagel directs GPUs to profitable networks, maximizing efficiency and returns for providers and users.
In Conclusion
The intersection of Filecoin and AI marks a significant step forward in the evolution of technology. By combining verifiable storage with computing networks, we are not only addressing current challenges but also paving the way for future innovations. As these technologies continue to develop, their impact on AI and beyond will be profound, offering new possibilities for businesses and developers alike.
To understand more about Ramo, Swan Chain, Lilypad or Bagel dive into the respective keynotes and links here:
To stay updated on the latest in the Filecoin ecosystem, follow the @Filecointldr handle or join us on Discord.
Many thanks to HQ Han and Jonathan Victor for reviewing and providing valuable insights to this piece.
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
Layer 2 solutions (L2s) are essential innovations in blockchain technology that enhance the scalability, efficiency, and functionality of their respective networks. For Filecoin, an L1 focused on decentralized storage, L2 solutions play a crucial role in bringing new capabilities to the base infrastructure of the network.
As Filecoin continues to grow, L2 solutions are helping bring Filecoin to market, and creating tailored offerings to builders focused on specific verticals. This post explores the current state of L2 solutions on Filecoin, highlighting the pioneering advancements and future directions.
Underlying Architecture
Before diving into the L2s, it’s useful to understand the shared framework that many of Filecoin’s L2s are built on: Interplanetary Consensus (IPC).
InterPlanetary Consensus (IPC) is a framework designed to solve the problem of scalability in decentralized applications (dApps). IPC achieves this by allowing the creation of subnets, which are independent blockchains that can be customized with specific consensus algorithms tailored to the needs of the application. These subnets can communicate seamlessly with each other, minimizing the need for cross-chain bridges – but anchored into the root Filecoin network.
Builders are drawn to IPC for several reasons. First, IPC subnets inherit the security features of their parent network, ensuring a high level of security for the dApps they host. Second, IPC leverages the Filecoin Virtual Machine (FVM), a versatile execution environment that supports various programming languages, allowing for greater interoperability with other blockchains. Finally, IPC’s tight integration with Filecoin, a large decentralized storage network, offers dApps easy access to robust data storage and retrieval capabilities. This combination of scalability, security, interoperability, and storage integration makes IPC an attractive choice for developers building the next generation of dApps.
Advancements in Data Management with Filecoin’s L2 Solutions
As the demand for efficient data management increases, Filecoin’s Layer 2 solutions are rising to meet these needs. These advancements focus on optimizing data storage and retrieval, offering enhanced scalability and cost-effectiveness across various applications. Basin is one such startup leading the charge.
Basin, the first data Layer 2 on Filecoin, represents an advancement in decentralized data infrastructure, bringing a swath of new services into the Filecoin ecosystem targeted at data heavy applications:
Key Features and Innovations
Hot and Cold Data Layers: Basin’s dual-layer approach incorporates a hot cache layer for real-time data access and a cold storage component for long-term archiving. This setup ensures both immediate accessibility and cost-effective storage, catering to diverse data needs.
Scalable Infrastructure: Basin’s architecture combines Filecoin’s secure storage capabilities with a flexible, scalable design ideal for handling high-volume data from IoT and AI applications.
Familiar Interfaces: Basin supports compatibility with S3, allowing developers to use familiar tools for managing data, which facilitates a smoother transition to decentralized solutions.
Basin is being actively used in real-world applications, such as handling weather data for decentralized stations with WeatherXM, and generating synthetic data for smart contracts. These use cases highlight Basin’s ability to efficiently store, manage, and monetize diverse data types, advancing practices in AI and machine learning.
Simplifying Decentralized Storage: Innovations and Challenges
Efficiently managing decentralized storage involves overcoming challenges related to user accessibility, cost, and integration. Providing more intuitive and cost-effective tools for data management will help address these challenges – and this is where Akave comes in.
Akave is the first L2 storage chain powering on-chain data lakes, offering a novel approach to managing large volumes of data within a decentralized network. Data lakes are used in traditional enterprises to manage all types of data – typically feeding into large scale compute flows (e.g. for big data analytics). By leveraging Filecoin’s infrastructure, Akave aims to become a leading solution in decentralized data management, with a focus on enhancing data handling capabilities and integrating advanced security measures.
Key Features and Innovations
On-Chain Data Management: Akave focuses on creating on-chain data lakes, which provide a highly scalable and secure solution for managing large volumes of data directly on Filecoin.
Advanced Data Handling: The platform supports customizable data handling options such as replication policies and erasure coding, enhancing data security and availability.
Integration with Filecoin: Akave leverages Filecoin’s blockchain for improved data management, security, and decentralization.
Akave’s Decentralized Data Lakes revolutionize data storage with faster local access by placing data close to compute stacks, cutting egress costs compared to centralized clouds, and ensuring immutability and integrity through ZK Proofs. Users benefit from competitive pricing and diverse options via an open marketplace. Continuous visibility into data status and history is provided through Akave’s integration with Filecoin’s InterPlanetary Consensus (IPC), enhancing transparency and trust.
Enhancing AI and Unstructured Data Storage with Filecoin’s L2 Solutions
In the realm of AI and unstructured data, specialized storage solutions are crucial for managing and processing large datasets efficiently. Filecoin’s Layer 2 solutions like Storacha Network are stepping up to provide high-performance storage tailored for these needs.
Storacha Network is a cutting-edge storage solution designed to enhance the management of AI and unstructured data. Leveraging Filecoin’s robust infrastructure, Storacha Network offers high-performance decentralized storage tailored for advanced applications. Looking ahead, Sriracha envisions evolving into a federated network with increased public participation, aiming to enhance global data access through a decentralized CDN and fostering broad community involvement.
Key Features and Innovations
High-Performance Storage: Storacha offers decentralized hot object storage, ensuring rapid access and retrieval of data, essential for AI applications that require quick processing and scaling.
Provenance and Ownership: Users maintain control over their data through UCANs (User-Controlled Authorization Networks), providing secure, cryptographic proofs of data ownership and access rights without frequent blockchain interactions.
Efficient Data Handling: Storacha handles large datasets by sharding files, facilitating quick retrieval and efficient management, crucial for large-scale AI operations.
Storacha Network supports a range of AI use cases by providing fast, scalable object storage optimized for both structured and unstructured data. It addresses key needs such as verifiability and provenance for decentralized GPU networks, ensuring that training processes are executed as expected and checkpoints are maintained.
Additionally, Storacha allows users to bring their own storage to training jobs, facilitating the sharing of hyperparameters and weights while ensuring ownership of training results.
In Conclusion
To wrap up, Filecoin’s Layer 2 solutions are paving the way for a new era in decentralized data management. Innovations like Basin, Akave, and Storacha Network are not only addressing the challenges of scalability and cost but also enhancing the efficiency and performance of data handling. As these technologies evolve, they promise to transform how data is stored, managed, and utilized, marking significant progress in the Web3 ecosystem.
Many thanks to Jonathan Victor for reviewing and providing valuable insights to this piece.
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.