Editor’s Note: This article draws heavily from David Aronchick’s presentation at the Filecoin Unleashed Paris 2023. David is the CEO of Expanso and former head of Compute-over-data at Protocol Labs which is responsible for the launch of the Bacalhau project. This blog post represents the independent view of the creator of the original content, who has given permission for this re-publication.
The world will store more than 175 zettabytes of data by 2025, according to IDC. That’s a lot of data, precisely 175 trillion 1GB USB sticks. Most of this data will be generated between 2020 and 2025, with an estimated compound annual growth of 61%.
The rapidly growing data sphere broadly poses two major challenges today:
- Moving data is slow and expensive. If you attempted to download 175 zettabytes at current bandwidth, it would take you roughly 1.8 billion years.
- Compliance is hard. There are hundreds of data-related governances worldwide which makes compliance across jurisdictions an impossible task.
The combined result of poor network growth and regulatory constraints is that nearly 68% of enterprise data is unused. That’s precisely why moving compute resources to where the data is stored (broadly referred to as compute-over-data) rather than moving data to the place of computation becomes all the more important, something which compute-over-data (CoD) platforms like Bacalhau are working on.
In the upcoming sections, we will briefly cover:
- How organizations are currently handling data today
- Propose alternative solutions based on compute-over-data
- Lastly, postulate why decentralized computation matters
The Present Scenario
There are three main ways in which organizations are navigating the challenges of data processing today — none of which are ideal.
Using Centralized Systems
The most common approach is to lean on centralized systems for large-scale data processing. We often see enterprises use a combination of compute frameworks — Adobe Spark, Hadoop, Databricks, Kubernetes, Kafka, Ray, and more — forming a network of clustered systems that are attached to a centralized API server. However, such systems fall short of effectively addressing network irregularities and other regulatory concerns around data mobility.
This is partly responsible for companies coughing up billions of dollars in governance fines and penalties for data breaches.
Building It Themselves
An alternative approach is for developers to build custom orchestration systems that possess the awareness and robustness the organizations need. This is a novel approach but such systems are often exposed to risks of failure by an over-reliance on a few individuals to maintain and run the system.
Doing Nothing
Surprisingly, more often than not, organizations do nothing with their data. A single city, for example, may collect several petabytes of data from CCTV recordings a day and only view them on local machines. The city does not archive or process these recordings because of the enormous costs involved.
Building Truly Decentralized Compute
There are 2 main solutions to the data processing pain points.
Solution 1: Build on top of open-source compute-over-data platforms.
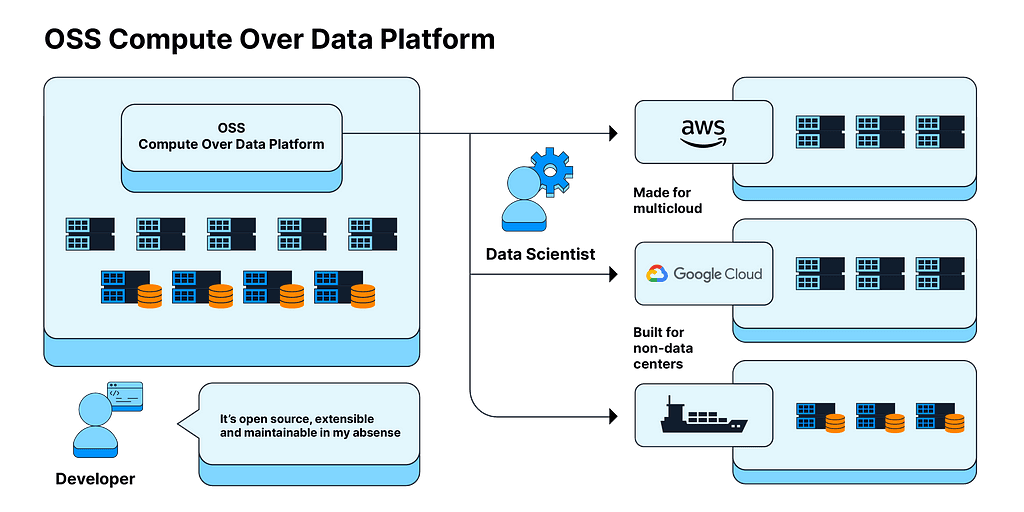
Instead of using a custom orchestration system as specified earlier, developers can use an open-source decentralized data platform for computation. Because it is open source and extensible, companies can build just the components they need. This setup caters to multi-cloud, multi-compute, non-data-center scenarios with the ability to navigate complex regulatory landscapes. Importantly, access to open-source communities makes the system less vulnerable to breakdowns as maintenance is no longer dependent on one or a few developers.
Solution 2: Build on top of decentralized data protocols.
With the help of advanced computational projects like Bacalhau and Lilypad, developers can go a step further and build systems not just on top of open-source data platforms as mentioned in Solution 1, but on truly decentralized data protocols like the Filecoin network.
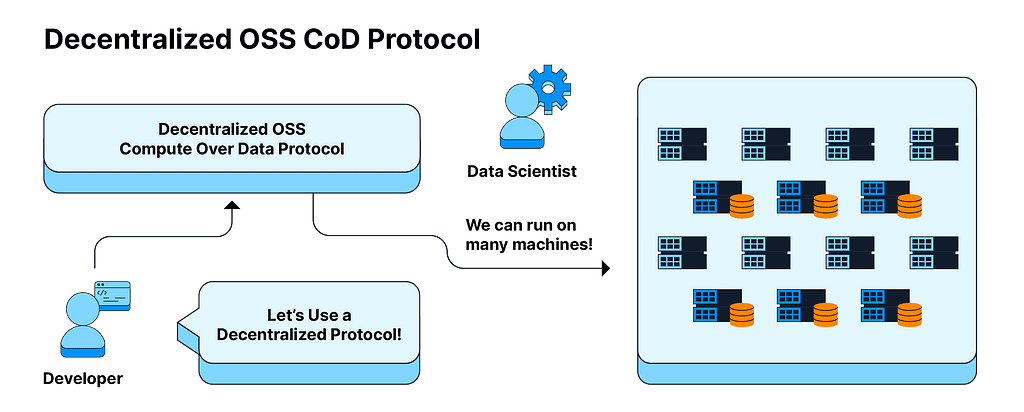
What this means is that organizations can leverage decentralized protocols that understand how to orchestrate and describe user problems in a much more granular way and thereby unlock a universe of compute right next to where data is generated and stored. This switchover from data centers to decentralized protocols can be carried out ideally with very few changes to the data scientists’ experience.
Decentralization is About Maximizing Choices
By deploying on decentralized protocols like the Filecoin network, the vision is that clients can access hundreds (or thousands) of machines spread across geographies on the same network, following the same protocol rules as the rest. This essentially unlocks a sea of options for data scientists as they can request the network to:
- Select a dataset from anywhere in the world
- Comply with any governance structures, be it HIPAA, GDPR, or FISMA.
- Run at the cheapest rates possible
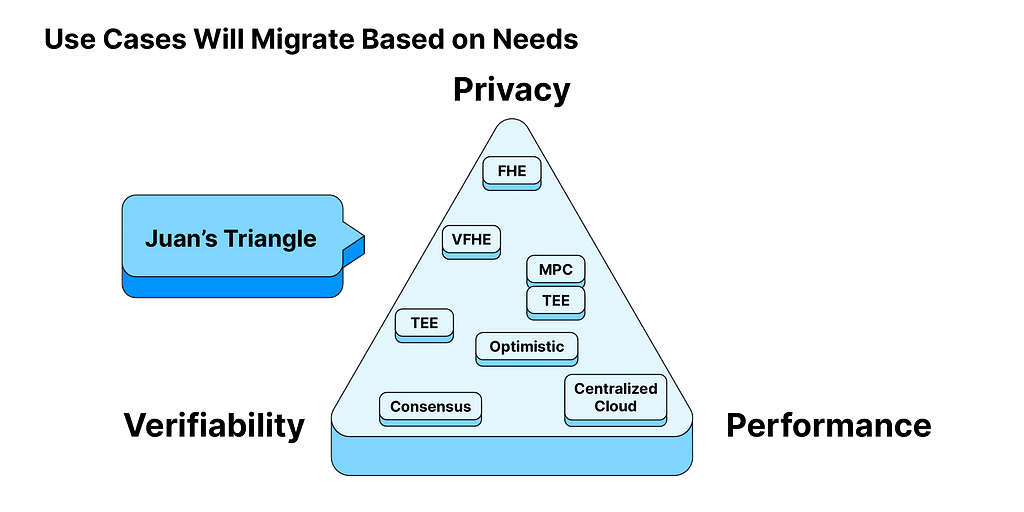
The concept of maximizing choices brings us to what’s called “Juan’s triangle,” a term coined after Protocol Labs’ founder Juan Benet for his explanation of why different use cases will have (in the future) different decentralized compute networks backing them.
Juan’s triangle explains that compute networks often have to trade off between 3 things: privacy, verifiability, and performance. The traditional one-size-fits-all approach for every use case is hard to apply. Rather, the modular nature of decentralized protocols enables different decentralized networks (or sub-networks) that fulfill different user requirements — be it privacy, verifiability, or performance. Eventually, it is up to us to optimize for what we think is important. Many service providers across the spectrum (shown in boxes within the triangle) fill these gaps and make decentralized compute a reality.
In summary, data processing is a complex problem that begs out-of-the-box solutions. Utilizing open-source compute-over-data platforms as an alternative to traditional centralized systems is a good first step. Ultimately, deploying on decentralized protocols like the Filecoin network unlocks a universe of compute with the freedom to plug and play computational resources based on individual user requirements, something that is crucial in the age of Big Data and AI.
Follow the CoD working group for all the latest updates on decentralized compute platforms. To learn more about recent developments in the Filecoin ecosystem, tune into our blog and follow us on social media at TL;DR, Bacalhau, Lilypad, Expanso, and COD WG.