
Introduction
This article is part of FilecoinTLDR’s use case exploration series, where we look at real-world problems that Filecoin’s verifiable storage layer can help address.
Imagine an AI team preparing to retrain a model using a dataset archived six months ago. The files are restored, but something is off: some data does not clearly match the original version, metadata is incomplete, and a few labels no longer line up with the source data. The dataset looks usable, but the team cannot easily prove it is the exact version they meant to reuse. The issue is no longer just whether the dataset was restored. It is whether the team can trust it enough to build the next model on top of it.
This is the restored-data accuracy problem. For model retraining, investigations, research, audits, and compliance, older data only becomes useful if teams can verify that it still matches what was originally stored.
When that confidence is missing, the risk can become operational, compliance-related, and reputational. Current solutions like checksums, immutable storage, and restore testing help reduce the risk, but they are still partial mitigations. At scale, teams still need stronger ways to show that restored data has remained intact, unchanged, and independently verifiable over time.

In this blog post, we will look at three reasons this matters:
- Old data is being reused, not just stored
- Restores need to be proven, not assumed
- Verifiable storage is becoming more important
We will then bring this back to Filecoin, and how verifiable storage can help make retained data easier to trust, prove, and reuse over time.
1. Old data is being reused, not just stored
Archived data used to be judged mainly by whether it could be kept and found later. If the file, record, or dataset was still there when someone needed it, storage had done its job.
That standard starts to change when old data is brought back into use. A restored dataset for model retraining has to match the version the team intended to use. Audit records have to be complete and tied to the right time period. Research data has to be consistent enough for someone to reproduce the same result. Legal evidence has to come with a clear record of where it came from and how it was handled. In each case, the restore is not just about getting data back. It is about whether the restored data is reliable enough to support the next decision.
This shift shows up across very different sectors. The specific data changes, but the underlying question is similar: when historical data is restored, can the team trust it enough to use it again?
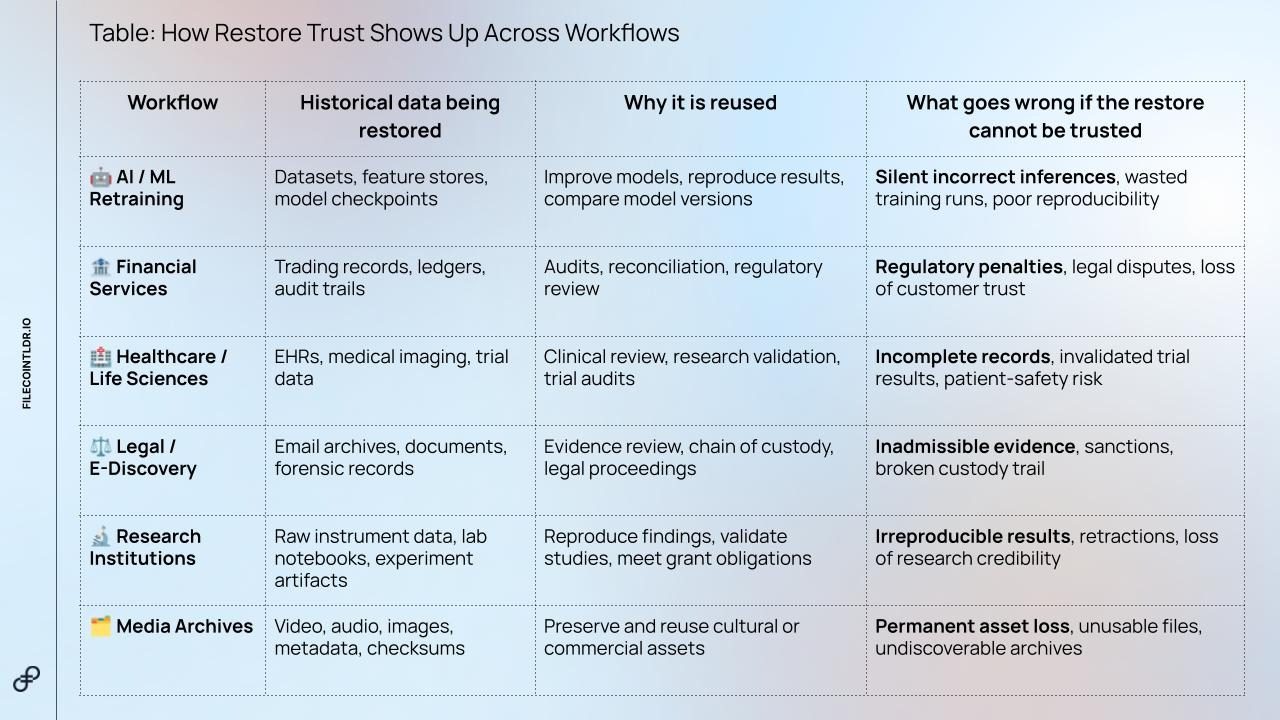
The pattern is clear: the restore moment is no longer just about access. It is a trust checkpoint. If the restored data cannot be verified, the next step becomes harder to defend, whether that step is model retraining, an audit, a legal review, or research validation.
2. Restores need to be proven, not assumed
The hard part about restored data is that failure does not always look obvious. A restore can finish successfully, files can show up in the right folder, and systems can come back online, while the data itself may still be incomplete, outdated, corrupted, compromised, or tied to the wrong version.
That is what creates the restore trust gap: the gap between believing recovery will work and being able to prove that the restored data is complete, correct, and usable when it matters.
Restore confidence often runs ahead of restore reality: A Veeam data resilience report found that while 90% of organizations expressed confidence in their ability to recover from a cyber incident, fewer than one in three ransomware victims fully recovered their data. On average, organizations recovered only 72% of affected data.
The point is not only that recovery can fail. It is that teams often discover the limits of their restore process only when the data is already needed.
This is especially clear in ransomware recovery. The U.S. National Institute of Standards and Technology (NIST), a widely cited cybersecurity standards body, warns that if a backup is created after malicious software has already affected the system, the backup may preserve the damaged version too. In that case, restoring from backup is not enough. Teams have to identify the correct backup version: the last clean version before the data was corrupted or compromised.
The question is not just “can we restore something?” It is “can we prove this is the right restore point?”
Real-world examples
- GitLab, 2017: An accidental production database deletion exposed that several backup and replication methods were unavailable or had failed silently. GitLab ultimately restored from an older snapshot, resulting in around six hours of production data loss and an 18-hour outage. The incident showed that backup success is not the same as restore readiness: when recovery was actually needed, several assumed recovery paths were not usable.
- City of Baltimore, 2019: After a ransomware incident, critical audit data was corrupted and could not support confidence in reported figures. The broader attack reportedly cost the city millions in recovery costs, but the sharper lesson here is that the problem moved from IT recovery into auditability, reporting, and public trust.
- Usagi Forest AI, 2026: An AI agent accidentally deleted around 42,000 S3 objects. The team was able to recover only because S3 versioning had already been enabled, turning what could have been permanent loss into a recoverable incident.
These examples are different, but they point to the same issue: recovery is not just about whether data exists somewhere. It is about whether teams can prove that the restored data is still what it should be: complete, unchanged, tied to the right version, and reliable enough to use.
3. Verifiable storage is becoming more important
Teams are not starting from zero. Most organizations already use tools like checksums, fixity checks, immutable storage, restore testing, DR drills, audit logs, and backup platforms to reduce restore risk. These solutions already address parts of the restore trust problem, but each comes with trade-offs:
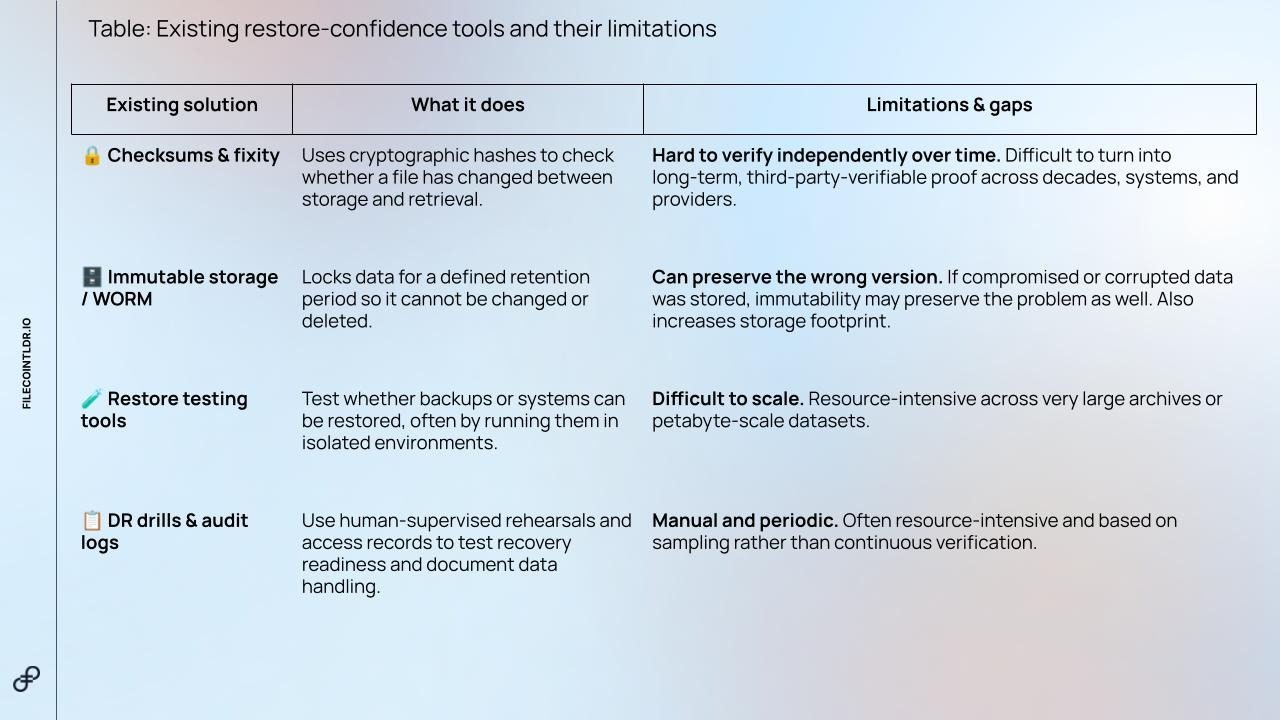
These controls exist for a reason. Data can become corrupted quietly, even in large and mature infrastructure systems. Meta has described silent data corruption as a real problem at modern scale, where hidden errors can spread across systems, create application-level issues, and take months to find and fix.
But even with controls in place, restore confidence becomes harder to prove as data grows larger, older, and more complex.
- Some validation still requires human judgment.
A checksum may show that a file has not changed, but it cannot tell whether the restored data is actually right for the application using it. A dataset may be intact at the file level, but still be paired with the wrong labels, schema, feature pipeline, model version, or business context. - Scale makes full verification harder.
As datasets grow into millions or billions of objects, checking everything becomes expensive and operationally difficult. Metadata expands, restore times stretch, and teams may end up relying on samples instead of verifying the full archive. - At petabyte scale, verification becomes an economic question.
The issue is no longer just whether verification is technically possible. It is whether teams can realistically verify enough of the archive, often enough, to trust it.
This is why the conversation starts to move from storage durability to verifiable integrity.
Durability asks whether the system is designed to avoid losing data. Verifiable integrity asks a harder question: can someone later prove that the data is still complete, unchanged, and tied to the right record?
As restored data becomes more valuable, that distinction matters. The future storage question is not only whether data can be retained or recovered, but whether its integrity can be proven over time.
Where Filecoin Fits
If the restored-data problem is partly a proof problem, then Filecoin’s value isn’t just that it stores data – it’s that it helps teams prove retained data has stayed intact over time. When a team restores old data, the first question is simple: is this the same data we stored before?
Filecoin is designed to help answer that. Content addressing helps verify that retrieved data matches what was originally stored, and storage proofs help show that storage commitments were maintained over time – instead of relying only on internal logs or provider claims. That matters because restored data is often trusted by people beyond the original team: auditors, partners, public institutions, researchers, future users.
Three layers of restore confidence
- Identify the data through content addressing. Building on the model used by IPFS, data is identified by what it is, not just where it lives. If the content changes, the identifier changes—so teams can tell whether what came back matches what was stored.
- Prove it was stored over time. Storage proofs, including Proof-of-Spacetime (PoSt), show that committed data continued to be stored rather than relying on a provider’s word.
- Verify data presence for active data. Newer mechanisms like Proof of Data Possession (PDP) let providers prove they hold an accessible copy, so problems surface before retrieval, not during it.
A concrete example: Fil One
Much of this can sound abstract until it shows up in a product you can actually point your existing tools at. Fil One is one of the clearest examples: S3-compatible object storage, backed by Filecoin, that turns verifiable integrity into a default feature rather than a research concept.
Its core promise speaks directly to the restore-trust gap: rather than asking you to take its word for it, Fil One provides daily proof that your data is stored exactly as you uploaded it. Each dataset gets a unique content identifier (CID) at upload, and the system automatically re-checks the data roughly every 24 hours to confirm it still matches that original fingerprint. That is exactly the “is this still what we stored?” question, answered continuously instead of only at the moment of restore.
| What Fil One offers | Why it matters for restored data |
|---|---|
| Daily CID integrity proofs | Auditable, 24/7 evidence that data hasn’t been altered – so integrity is proven continuously, not assumed at restore time. |
| S3-compatible API | Existing SDKs, CLIs, and workflows connect with little change, so verifiable storage doesn’t mean re-platforming. |
| No single-provider dependency | Data is spread across an independent network of providers, reducing the single points of failure behind many restore disasters. |
| 11 nines of durability | Distributed, redundant storage with audit-ready visibility into integrity – pairing durability with provable integrity. |
| $4.99/TB/month, no egress fees | Predictable economics make it realistic to keep, and keep verifying – large archives over the long term. |
For AI and data-intensive workloads, audit-sensitive data, multi-cloud strategies, and long-term retention, that combination is the point: durability and provable integrity, delivered through an interface teams already know.
This is already happening across the ecosystem
- AI-native retained data: Projects such as Recall or Kite AI Projects such as Recall and Kite AI point to a growing need for AI systems to keep track of data, memory, and records over time. As models, agents, and datasets become more important to business workflows, more AI data will need to be identified, verified, and trusted later. This is where Filecoin’s strengths around content addressing, storage proofs, and long-term verifiability become increasingly relevant.
- Enterprise-accessible storage: Akave Cloud is an S3-compatible, Filecoin-backed object storage platform that brings verifiable audit trails and policy-based access control into familiar storage workflows. Its work with 375ai shows how Filecoin-backed infrastructure can support data-heavy AI workflows where teams need to preserve data, control access, and maintain trust over time.
- Public records: The Government of Bermuda announced an initiative with Filecoin Foundation, carried out in collaboration with Internet Archive, to upload public datasets to Filecoin as part of Democracy’s Library. The goal was to make critical public information more resilient, transparent, and verifiable over time.
Across these examples, the pattern is the same: Filecoin is most relevant where data needs to be preserved, verified, and trusted over time. That is why Filecoin fits the restored-data accuracy problem. Its value is not only storage capacity, but the ability to make retained data easier to identify, verify, and trust when it needs to be used again.
Keep exploring Filecoin
- Try Fil One – verifiable, S3-compatible storage on Filecoin, free for 30 days.
- Follow FilecoinTLDR for ecosystem explainers and updates.
- Join the Filecoin Discord to connect with the community.
- Start the Filecoin Quest Hub to learn, complete quests, and get involved.
- Subscribe to the newsletter for future posts and insights.


