Editor’s Note: This blogpost is a repost of the original content published on 5 April 2024, by Turan VuralYuki Yuminaga from Fenbushi Capital. Established in 2015, Fenbushi Capital holds the distinction of being Asia’s pioneering blockchain-focused asset management firm with an AUM of $1.6 billion. Through research and investment, the firm aims to play a vital role in shaping the future of blockchain tech across diverse sectors.This blogpost is an example of these efforts, and represents the independent view of these authors, whom have given permission for this re-publication.
Data availability (DA) is a core technology in the scaling of Ethereum, allowing a node to efficiently verify that data is available to the network without having to host the data in question. This is essential for the efficient building of rollups and other forms of vertical scaling, allowing execution nodes to ensure that transaction data is available during the settlement period. This is also crucial for sharding and other forms of horizontal scaling, a planned future update to the Ethereum network, as nodes will need to prove that transaction data (or blobs) stored in network shards are indeed available to the network.
Several DA solutions have been discussed and released recently (e.g., Celestia, EigenDA, Avail), all with the intent of providing performant and secure infrastructure for applications to post DA.
The advantage of an external DA solution over an L1 such as Ethereum is that it provides an inexpensive and performant vehicle for on-chain data. DA solutions often consist of their own public chains built to enable cheap and permissionless storage. Even with modifications, the fact remains that hosting data natively from a blockchain is extremely inefficient.
Thus, we find that it is intuitive to explore a storage-optimized solution such as Filecoin for the basis of a DA layer. Filecoin uses its blockchain to coordinate storage deals between clients and storage providers but allows data to be stored off-chain.
In this post, we investigate the viability of a DA solution built on top of a Distributed Storage Network (DSN). We consider Filecoin specifically, as it is the most adopted DSN to date. We outline the opportunities that such a solution would offer, and the challenges that need to be overcome to build it.
A DA layer provides the following to services relying on it:
Client Safety: No node can be convinced that unavailable data is available.
Global Safety: The un/availability of data is agreed upon by all except at most a small minority of nodes.
Efficient data retrievability.
All of this needs to be done efficiently to enable scaling. A DA layer provides higher performance at a lower cost across the three points above. For example, any node can request a full copy of the data to prove custody, but this is inefficient. By having a system that provides all three of these, we achieve a DA layer that provides the security required for L2s to coordinate with an L1, along with stronger lower bounds in the presence of a malicious majority.
Custody of Data
Data posted to a DA solution has a useful lifetime: long enough to settle disputes or verify a state transition. Transaction data needs to be available only long enough to verify a correct state transition or to give validators enough opportunity to construct fraud proofs. As of writing, Ethereum calldata is the most common solution used by projects (rollups) requiring data availability.
Efficient Verification of Data
Data Availability Sampling (DAS) is the standard method of answering the question of DA. It comes with additional security benefits, strengthening network actors’ ability to verify state information from their peers. However, it relies on nodes to perform sampling: DAS requests must be answered to ensure mined transactions won’t be rejected, but there is no positive or negative incentive for a node to request samples. From the perspective of nodes that request samples, there is no negative penalty for not performing DAS. As an example, Celestia provides the first and only light client implementation to perform DAS, delivering stronger security assumptions to users and reducing the cost of data verification.
Efficient Access
A DA needs to provide efficient access to data to the projects using it. A slow DA may become the bottleneck for the services relying on it, causing inefficiencies at best and system failures at worst.
Decentralized Storage Network
A Decentralized Storage Network (DSN, as formalized in the Filecoin Whitepaper¹) is a permissionless network of storage providers that offer storage services for users of the network. Informally, it allows independent storage providers to coordinate storage deals with clients that need storage services and provides cheap and resilient data storage to clients seeking storage services at a low price. This is coordinated through a blockchain that records storage deals and enables the execution of smart contracts.
A DSN scheme is a tuple of three protocols: Put, Get, and Manage. This tuple comes with properties such as fault tolerance guarantees and participation incentives.
Put(data) → key Clients execute Put to store data under a unique key. This is achieved by specifying the duration for which data will be stored on the network, the number of replicas of the data that are to be stored for redundancy, and a negotiated price with storage providers.
Get(key) → data Clients execute Get to retrieve data that is being stored under a key.
Manage() The Manage protocol is called by network participants to coordinate the storage space and services made available by providers and repair faults. In the case of Filecoin, this is managed via a blockchain. This blockchain records data deals being made between clients and data providers and proofs of correctly stored data to ensure that data deals are being upheld. Correctly stored data is proved via the posting of proofs generated by data providers in response to challenges from the network. A storage fault occurs when a storage provider fails to generate a Proof-of-Replication or Proof-of-Spacetime promptly when requested by the Manage protocol, which results in the slashing of the storage provider’s stake. Deals can self-heal in the case of a storage fault if more than one provider is hosting a copy of the data on the network by finding a new storage provider to honor the storage deal.
DSN Opportunities
The work done thus far in DA projects has been to transform a blockchain into a platform for hot storage. Since a DSN is storage-optimized, rather than transforming a blockchain into a storage platform, we can simply transform a storage platform into one that provides data availability. The collateral of storage providers in the form of native FIL token can provide crypto-economic security that guarantees data is stored. Finally, the programmability of storage deals can provide flexibility around the terms of data availability.
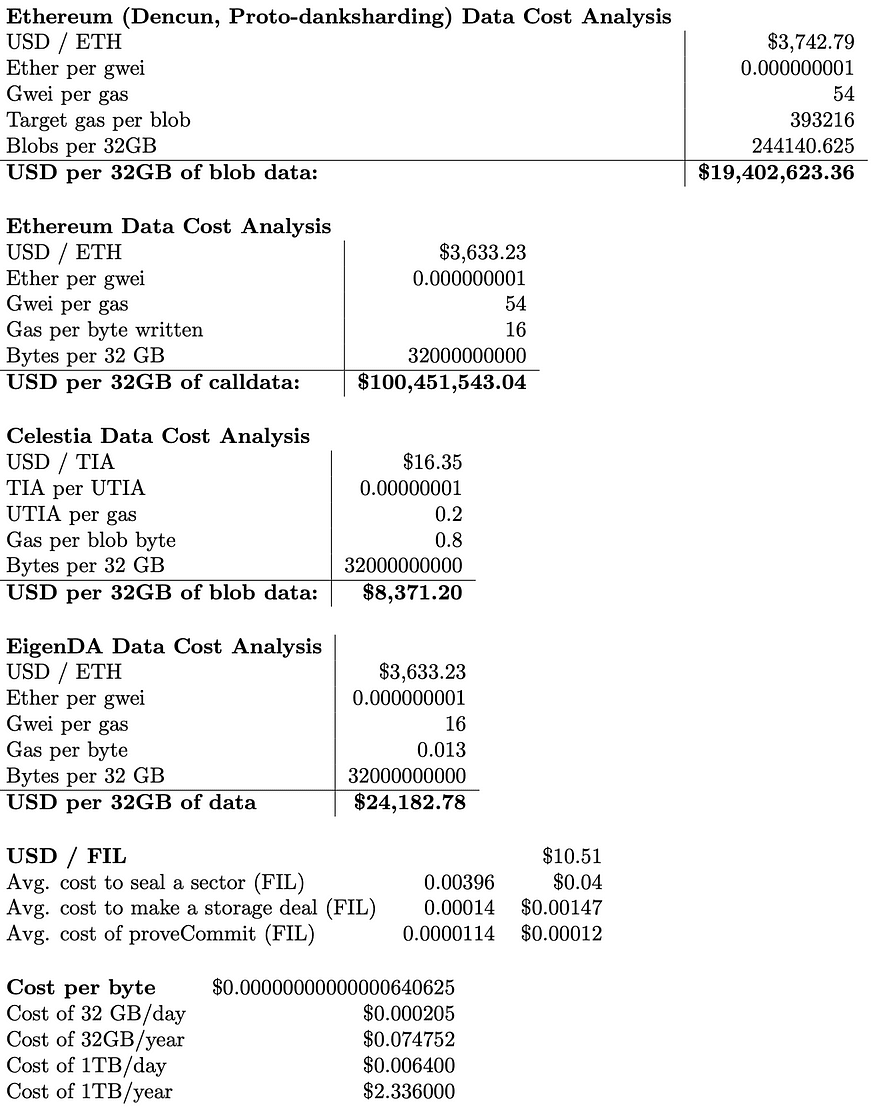
The most compelling motivation to transform the capabilities of a DSN to solve DA is the cost reduction in the data storage under the DA solution. As we discuss below, the cost of storing data on Filecoin is significantly cheaper than storing data on Ethereum. Given current Ether/USD prices, it costs over 3 million USD to write 1 GB of calldata to Ethereum, only to be pruned after 21 days. This calldata expense can contribute to over half of the transaction cost of an Ethereum-based rollup. However, 1 GB of storage on Filecoin costs less than .0002 USD per month. Securing DA at this or any similar price would bring transaction costs down for users and contribute to the performance and scalability of Web3.
Economic Security
In Filecoin, collateral is required to make storage space available. This collateral is slashed when a provider fails to honor its deals or uphold network guarantees. A storage provider that fails to provide services faces losing both its posted collateral and any profit that would have been earned from providing storage.
Incentive Alignment
Many of Filecoin’s protocol incentives align with the goals of DA. Filecoin provides disincentives for malicious or lazy behavior: storage providers must actively provide proofs of storage during consensus in the form of Proof-of-Replicas and Proof-of-Spacetime, continuously proving that the storage exists without honest majority assumptions. Failure of a storage provider to provide proof results in stake slashing, and removal from consensus, among other penalties. Current DA solutions lack incentive for nodes to perform DAS, relying on ad-hoc altruistic behavior for proof of DA.
Programmability
The ability to customize data deals also makes a DSN an attractive platform for DA. Data deals can have varying durations, allowing users of a DSN-based DA to pay for only the DA that they need. Fault tolerance can also be tuned by setting the number of copies that are to be stored throughout the network. Further customization is supported via smart contracts on Filecoin (called Actors), which are executed on the FEVM. This leads to Filecoin’s growing ecosystem of DApps, from compute-over-storage solutions such as Bacalhau to DeFi and liquid staking solutions such as Glif. Retriev makes use of Filecoin Actors to provide incentive-aligned retrieval with permissioned referees. Filecoin’s programmability can be used to tailor DA requirements needed for different solutions, so that platforms that rely on DA are not paying for more DA than they need.
Challenges to a DSN-Based DA Architecture
In our investigation, we have identified significant challenges that need to be overcome before a DA service can be built on a DSN. As we now talk about the feasibility of implementation, we will use Filecoin as our main focus of the discussion.
Proof Latency
The cryptographic proofs that ensure the integrity of deals and stored data on Filecoin take time to prove. When data is committed to the network, it is partitioned into 32 gigabyte sectors and “sealed.” The sealing of data is the foundation of both the Proof-of-Replication (PoRep), which proves that a storage provider is storing one or more uniquecopies of the data, and Proof-of-Spacetime (PoST), which proves that a storage provider stored a unique copy continuously throughout the duration of the storage deal. Sealing has to be computationally expensive to ensure that storage providers aren’t sealing data on demand to undermine the required PoReP. When the protocol presents the periodic challenge to a storage provider to provide proof of unique and continuous storage, sealing has to safely take longer than the response window so that a storage provider can’t falsify proofs or replicas on the fly. For this reason, it can take providers approximately three hours to seal a sector of data.
Storage Threshold
Because of the computational expense of the sealing operation, the sector size of the data being sealed has to be economically worthwhile. The price of storage has to justify the cost of sealing to the storage provider, and likewise, the resulting cost of data being stored has to be low enough at scale (in this case, for an approximately 32GB chunk) for a client to want to store data on Filecoin. Although smaller sectors could be sealed, this would drive up the price of storage to compensate storage providers. To get around this, data aggregators collect smaller pieces of data from users to be committed to Filecoin as a chunk close to 32 GB. Data aggregators commit to user’s data via a Proof-of-Data-Segment-Inclusion (PoDSI), which guarantees the inclusion of a user’s data in a sector, and a sub-piece CID (pCID), which the user will be able to use to retrieve the data from the network.
Consensus Constraints
Filecoin’s consensus mechanism, Expected Consensus, has a block time of 30 seconds and finality within hours, which may improve in the near future (see FIP-0086 for fast finality on Filecoin). This is generally too slow to support the transaction throughput needed for a Layer 2 relying on DA for transaction data. Filecoin’s block time is lower-bounded by storage provider hardware; the lower the block time, the more difficult it is for storage providers to generate and provide proofs of storage, and the more storage providers will be falsely penalized for missing the proving window for the proper storage of data. To overcome this, InterPlanetary Consensus (IPC) subnets can be leveraged to take advantage of faster consensus times. IPC uses Tendermint-like consensus and DRAND for randomness: in the case that DRAND is the bottleneck, we would be able to achieve a 3-second block-time with an IPC subnet. In the case of a Tendermint bottleneck, PoCs such as Narwhal have achieved blocktimes in the hundreds of milliseconds.
Retrieval Speed
The final barrier-to-build is retrieval. From the constraints above, we can deduce that Filecoin is suitable for cold or lukewarm storage. However, the DA data is hot and needs to support performant applications. Incentive-aligned retrieval is difficult in Filecoin; data needs to be unsealed before it is served to clients, which adds latency. Currently, rapid retrieval is done via SLAs or the storage of un-sealed data alongside sealed sectors, neither of which can be relied on in the architecture of a secure and permissionless application on Filecoin. Especially with Retriev proving that retrieval can be guaranteed via the FVM, incentive-aligned rapid retrieval on Filecoin remains an area to be further explored.
Cost Analysis
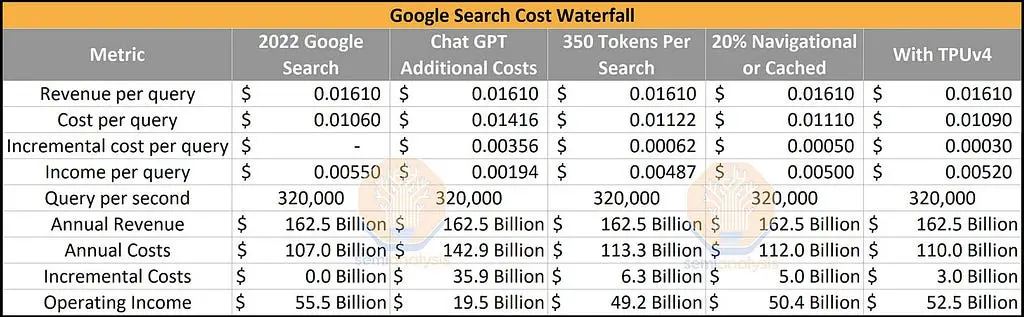
In this section, we consider the cost that comes from these design considerations. We show the cost of storing 32GB as Ethereum calldata, Celestia blobdata, EigenDA blobdata, and as a sector on Filecoin using near-current market prices.
The analysis highlights the price of Ethereum calldata: 100 million USD for 32 GB of data. This price showcases the cost of security behind Ethereum’s consensus, and is subject to the volatility of Ether and gas prices. The Dencun upgrade, which introduced Proto-Danksharding (EIP-4844), introduced blob transactions with a target of 3 blobs per block of approximately 125 KB each, and variable gas blob pricing to maintain the target amount of blobs per block. This upgrade cut the cost of Ethereum DA by ⅕: 20 million USD for 32 GB of blob data.
Celestia and EigenDA provide significant improvements: 8,000 and 26,000 USD for 32 GB of data, respectively. Both are subject to the volatility of market prices and reflect to some extent the cost of consensus securing their data: Celestia with its native TIA token, and EigenDA with Ether.
In all of the above cases, the data stored is not permanent. Ethereum calldata is stored for 3 weeks, with blobs stored for 18 days. EigenDA stores blobs for a default of 14 days. As of the current Celestia implementation, blob data is stored indefinitely by archival nodes but only sampled by light nodes for a maximum of 30 days.
The final two tables are direct comparisons between Filecoin and current DA solutions. Cost equivalence first lists the cost of a single byte of data on the given platform. The amount of Filecoin bytes that can be stored for the same amount of time for the same cost is then shown.
This shows that Filecoin is orders of magnitude cheaper than current DA solutions, costing fractions of a cent to store the same amount of data for the same amount of time. Unlike Ethereum nodes and that of other DA solutions, Filecoin’s nodes are optimized to provide storage services, and its proof system allows nodes to prove storage, rather than replicate storage across every node in the network. Without accounting for the economics of storage providers (such as the energy cost to seal data), it shows that the basic overhead of the storage process on Filecoin is negligible. This shows a market opportunity in the millions of USD per gigabyte compared to Ethereum for a system that can provide secure and performant DA services on Filecoin.
Throughput
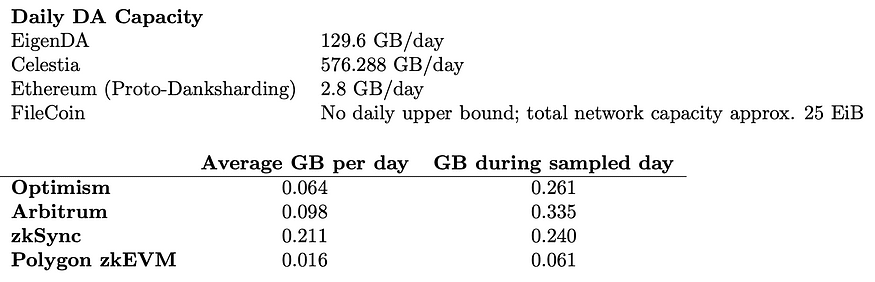
Below, we consider the capacity of DA solutions and the demand that is generated by major layer 2 rollups.
Because Filecoin’s blockchain is organized in tipsets with multiple blocks at every block-height, the number of deals that can be done is not restricted by consensus or block size. The strict data constraint of Filecoin is that of its network-wide storage capacity, not what is allowed via consensus.
For daily DA demand, we pull data from Rollups DA and Execution from Terry Chung and Wei Dai, which includes a daily average across 30 days and a singular sampled day. This allows us to consider average demand while not overlooking aberrations from the average (for example, Optimism’s demand on 8/15/2023 of approximately 261,000,000 bytes was over 4x its 30 day average of 64,000,000 bytes).
From this selection, we see that despite the opportunity of lower DA cost, we would need a dramatic increase in DA demand to make efficient use of the 32 GB sector size of Filecoin. Although sealing 32 GB sectors with less than 32 GB of data would be a waste of resources, we could do so while still reaping a cost advantage.
Architecture
In this section, we consider the technical architecture that can be achieved if we were to build this today. We will consider this architecture in the context of arbitrary L2 applications and an L1 chain that the L2 is serving. Since this solution is an external DA solution, like that of Celestia and EigenDA, we do not consider Filecoin as example L1.
Components
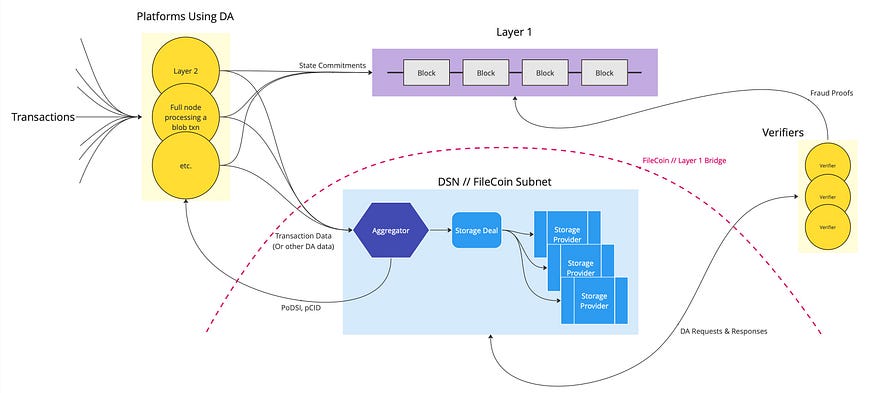
Even at a high-level, a DA on Filecoin will make use of many different features of the Filecoin ecosystem.
Transactions: Downstream users make transactions on a platform that requires DA. This could be an L2.
Platforms Using DA: These are the platforms that use DA as a service. This could be an L2 which posts transaction data to the Filecoin DA and commitments to an L1, such as Ethereum.
Layer 1: This is any L1 that contains commitments pointing to data on the DA solution. This could be Ethereum, supporting an L2 that leverages the Filecoin DA solution.
Aggregator: The frontend of Filecoin-based DA solution is an aggregator, a centralized component which receives transaction data from L2’s and other DA clients and aggregates them into 32 GB sectors suitable for sealing. Although a simple proof-of-concept would include a centralized aggregator, platforms using the DA solution could also run their own aggregator,for example as a sidecar to an L2 sequencer. The centralization of the aggregator can be seen as similar to that of an L2 sequencer or EigenDA’s disperser. Once the aggregator has compiled a payload near 32GB, it makes a storage deal with storage providers to store the data. Clients are given a guarantee that their data will be included in the sector in the form of a PoDSI (Proof of Data Segment Inclusion), and a pCID to identify their data once it is on the network. This pCID is what would be included in the state commitments on the L1 to reference supporting transaction data.
Verifiers: Verifiers request the data from the storage providers to ensure the integrity of state commitments and build fraud proofs, which are committed to the L1 in the case of provable fraud.
Storage Deal: Once the aggregator has compiled a payload near 32GB, the aggregator makes a storage deal with storage providers to store the data.
Posting blobs (Put): To initiate a put, a DA client will submit their blob containing transaction data to the aggregator. This can be done in an off-chain manner, or an on-chain manner via an on-chain aggregator oracle. To confirm receipt of the blob, the aggregator returns a PoDSI to the client to prove that their blob is included in the aggregated sector that will be committed to the subnet. A pCID (sub-piece Content IDentifier) is also returned. This is what the client and any other interested party will use to reference the blob once it is being served on Filecoin.
Data deals would appear on-chain within minutes of the deal being made. The largest barrier to latency is the sealing time, which can take 3 hours. This means that although the deal has been made, and the client can be confident that the data will appear in the network, the data cannot be guaranteed to be queryable until the sealing process is complete. The Lotus client has a fast-retrieval feature in which an unsealed copy of the data is stored alongside the sealed copy that may be able to be served as soon as the unsealed data is transferred to the data storage provider, as long as a retrieval deal does not depend on the proof of sealed data to appear on the network. However, this functionality is at the discretion of the data provider, and is not cryptographically guaranteed as part of the protocol. If a fast-retrieval guarantee is to be provided, there would need to be changes to consensus and dis/incentive mechanisms in place to enforce it.
Retrieving blobs (Get): Retrieval is similar to a put operation. A retrieval deal needs to be made, which will appear on-chain within minutes. Retrieval latency will depend on the terms of the deal and whether an unsealed copy of data is stored for fast retrieval. In the fast retrieval case, the latency will depend on network conditions. Without fast retrieval, data will need to be unsealed before being served to the client, which takes the same amount of time as sealing, on the order of 3 hours. Thus without optimizations we have a maximum round-trip of 6 hours, major improvement in data serving would need to be made before this becomes a viable system for DA or fraud proofs.
Proof of DA: proof of DA can be considered in two steps; via the PoDSI that is given when the data is committed to the aggregator while the deal is being made and then the continued commitment of PoRep and PoST that storage providers provide via Filecoin’s consensus mechanism. As discussed above, the PoRep and PoST give scheduled and provable guarantees of data custody and persistence.
This solution will make heavy use of bridging, as any client that relies on DA (regardless of the construction of proofs) will need to be able to interact with Filecoin. In the case of the pCID included in the state transition that is posted to the L1, a verifier can make an initial check to make sure that a bogus pCID wasn’t committed. There are several ways that this could be done, for example, via an oracle that posts Filecoin data on the L1 or via verifiers that verifies the existence of a data deal or sector that corresponds to the pCID. Likewise, the verification of validity or fraud proofs that get posted to the L1 may need to make use of a bridge to be convinced of a proof. Current available bridges are Axelar and Celer.
Security Analysis
Filecoin’s integrity is enforced through the slashing of collateral. Collateral can be slashed in two cases: storage faults or consensus faults. A storage fault corresponds to a storage provider not being able to provide proof of stored data (either PoRep or PoST), which would correlate to a lack of data availability in our model. A consensus fault corresponds to malicious action in consensus, the protocol that manages the transaction ledger from which the FEVM is abstracted.
A Sector Fault refers to the penalty incurred from the failure to post proof of continuous storage. Storage providers are allowed a one-day grace period during which a penalty is not incurred for faulty storage. After 42 days from a sector becoming faulty, the sector is terminated. Incurred fees are burnt.
A Sector Termination occurs after a sector has been faulty for 42 days or a storage provider purposefully terminates a deal. Termination fees are equivalent to the maximum amount that a sector has earned up to termination, with an upper bound of 90 days’ worth of earning. Unpaid deal fees are returned to the client. Incurred fees are burnt.
Storage Market Actor Slashing occurs in the event of a terminated deal. This is the slashing of the collateral that the storage provider puts up behind the deal.
The security provided by Filecoin is very different from that of other blockchains. Whereas blockchain data is typically secured via consensus, Filecoin’s consensus only secures the transaction ledger, not the data referred to by the transaction. The data that is stored on Filecoin has only enough security to incentive-align storage providers to provide storage. This means that the data stored on Filecoin is secured via fault penalties and business incentives such as reputation with clients. In other words, a data fault on a blockchain is equivalent to a breach of consensus, and breaks the safety of the chain or its notion of the validity of transactions. Filecoin is designed to be fault tolerant when it comes to data storage, and therefore only uses its consensus to secure its dealbook and deal-related activities. The cost of a storage miner not fulfilling its data deal has a maximum of 90 days worth of storage reward in penalties, and the loss of the collateral put up by the miner to secure the deal.
Therefore, the cost of a data withholding attack being launched from Filecoin providers simply the opportunity cost a retrieval deal. Data retrieval on Filecoin relies on the storage miner being incentivized by a fee paid for by the client. However, there is no negative impact to a miner for not responding to a data retrieval request. To mitigate the risk of a single storage miner ignoring or refusing data retrieval deals, data on Filecoin can be stored by multiple miners.
Since the economic security behind the data being stored on Filecoin is considerably less than that of blockchain based solutions, the prevention of data manipulation must also be considered. Data manipulation is protected via Filecoin’s proof system. Data is referred to via CIDs, through which data corruption is immediately detectable. A provider therefore cannot serve corrupt data, as it is easy to verify whether the fetched data matches the requested CID. Data providers cannot store corrupted data in the place of uncorrupted data. Upon the receipt of client data, providers must provide proof of a correctly sealed data sector to initiate the data deal (check this). Therefore, a storage deal cannot be started with corrupt data. During the lifetime of the storage deal, PoSTs are provided to prove custody (recall that this proves both custody of the sealed data sector and custody since the last PoST). Since the PoST is reliant on the sealed sector at the time of proof generation, a corrupt sector would result in a bogus PoST, resulting in a sector failure. Therefore, a storage provider can neither store nor serve corrupted data, cannot claim reward for services provided for uncorrupted data, and cannot avoid being penalized for tampering with a client’s data.
Security can be strengthened through increasing the collateral committed by the storage provider to the Storage Market Actor, which is currently decided by the storage provider and the client. If we assume that this was sufficiently high enough (for example, the same stake as an Ethereum validator) to incentivize a provider not to default, we can think of what is left to secure (even though this would be extremely capital-inefficient, as this stake would be needed to secure each transaction blob or sector with aggregated blobs). Now, a data provider could choose to make data unavailable for maximums of 41-day chunks before the storage deal is terminated by the Storage Market Actor. Assuming a shorter data deal, we could assume that the data can be made unavailable until the last day of the deal. In the absence of coordinated malicious actors, this can be mitigated via replication on multiple storage providers so that the data can continue being served.
We can consider the cost of an attacker overriding consensus to either accept a bogus proof or rewrite ledger history to remove a deal from the orderbook without penalizing the responsible storage provider. It is worth noting however that in the case of such a safety violation, an attacker would be able to manipulate Filecoin’s ledger however they want. In order for an attacker to commit such an attack, they would need at least a majority stake in the Filecoin chain. Stake is related to storage provided to the network; with a current 25 EiB (10¹⁶ bytes) of data securing the Filecoin chain, at least 12.5 EiB would be needed for a malicious actor to offer its own chain that would win the fork-choice rule. This is further mitigated by slashing related to consensus faults, for which the penalty is the loss of all pledged collateral and block rewards and all suspension from participation in consensus.
Aside: Withholding attacks on other DA solutions Although the above shows that Filecoin is lacking in protecting data from withholding attacks, it is not alone.
Ethereum: In general, the only way to guarantee that a request to the Ethereum network is answered is to run a full node. Full nodes have no requirements to fulfill data retrieval requests outside of consensus — and therefore. Constructs such as PeerDAS introduce a peer scoring system for a node’s responses to data retrieval in which a node with a low enough score (essentially a DA reputation) could be isolated from the network.
Celestia: Even though Celestia has much stronger security per-byte against withholding attacks in comparison to our Filecoin construction, the only way to take advantage of this security is to host your own full node. Requests to Celestia infrastructure that are not owned and operated in-house can be censored without penalty.
EigenDA: Similar to Celestia, any service can run an EigenDA Operator node to ensure retrieval of their own data. As such, any out protocol data retrieval request can be censored. Also note that EigenDA has a centralized and trusted dispenser in charge of data encoding, KZG commitment, and data dispersal, similar to our aggregator.
Retrieval Security
Retrievability is necessary for DA. Ideally, market forces motivate economically rational miners to accept retrieval deals, and compete with other miners to keep prices for clients low. It is assumed that this is enough for data providers to provide retrieval services, however given the importance of DA, it is reasonable to require more security.
Retrieval is currently not guaranteed via the economic security stipulated above. This is because it is cryptographically difficult to prove that data wasn’t received by a client (in the case where a client needs to refute a storage miner’s claim of sending data) in a trust-minimized manner. A protocol-native retrieval guarantee would be required in order for retrieval to be secured through the Filecoin’s economic security. With minimal changes to the protocol, this means that retrieval would need to be associated with a sector fault or deal termination. Retriev is a proof-of-concept which was able to provide data retrieval guarantees by using trusted “referees” to mediate data retrieval disputes.
Aside: Retrieval on other DA solutions As can be seen above, Filecoin lacks the protocol-native retrieval guarantees necessary to keep storage (or retrieval providers) from acting selfishly. In the case of Ethereum and Celestia, the only way to guarantee that data from the protocol can be read is to self-host a full node, or trust a SLA from an infrastructure provider. It is not trivial to guarantee retrieval as a Filecoin storage provider; the analogous setting in Filecoin would be to become a storage provider (requiring significant infrastructure cost) and successfully accept the same storage deal as a storage provider that was posted as a user, at which point one would be paying themselves to provide storage to themselves.
Latency Analysis
Latency on Filecoin is determined by several factors, such as network, topology, storage mining client configuration, and hardware capabilities. We provide a theoretical analysis which discusses these factors, and the performance that can be expected by our construct.
Due to the design of Filecoin’s proof system and lack of retrieval incentives, Filecoin is not optimized to provide high-performance round trip latency from the initial posting of data to the initial retrieval of data. High performance retrieval on Filecoin is an active area of research that is constantly changing as storage providers increase their capabilities and as Filecoin introduces new features. We define a “round trip” as the time from the submission of a data deal to the the earliest moment the data submitted to Filecoin can be downloaded.
Block Time In Filecoin’s Expected Consensus, data deals can be included within the block-time of 30 seconds. 1 hour is the typical time for confirmation of sensitive on-chain data (such as coin transfers).
Data Processing Data processing time varies widely between storage providers and configurations. The sealing process is designed to take 3 hours with standard storage mining hardware. Miners often outperform this 3 hour threshold via special client configurations, parallelization, and investing in more capable hardware. This variation also affects the duration of sector un-sealing, which can be circumvented altogether by quick retrieval options in Filecoin client implementations such as Lotus. The quick retrieval setting stores an unsealed copy of data alongside sealed data, significantly speeding up retrieval time. Based on this, we can assume a worst-case delay of three hours from the acceptance of a data deal to when the data is available on-chain.
Conclusion and Future Directions
This article explores building a DA by leveraging an existing DSN, Filecoin. We consider the requirements of a DA with respect to its role as a critical element of scaling infrastructure in Ethereum. We consider building on top of Filecoin for the viability of DA on a DSN, and use it to consider the opportunities that a solution on Filecoin would provide to the Ethereum ecosystem, or any that would benefit from a cost-effective DA layer.
Filecoin proves that a DSN can dramatically improve the efficiency of data storage in a distributed, blockchain-based system, with a proven saving of 100 million USD per 32 GB written at current market prices. Even though the demand for DA is not yet high enough to fill 32 GB sectors, the cost advantage of a DA still holds if empty sectors are sealed. Although current latency of storage and retrieval on Filecoin is not appropriate for the hot storage needs, storage miner-specific implementations can provide reasonable performance with data being available in under 3 hours.
The increased trust in Filecoin storage providers can be tuned via variable collateral, such as in EigenDA. Filecoin extends this tunabel security to allow for a number of replicas to be stored across the network, adding tunable byzantine tolerance. Guaranteed and performant data retrieval would need to be solved in order to robustly deter data withholding attacks, however like any other solution, the only way to truly guarantee retrievability is to self-host a node or trust infrastructure providers.
We see opportunities for DA in the further development of PoDSI, which could be used (alongside Filecoin’s current proofs) in place of DAS to guarantee data inclusion in a larger sealed sector. Depending on how this looks, this may make slow turnaround of data tolerable, as fraud proofs could be posted in a window of 1 day to 1 week, while DA could be guaranteed on demand. PoDSIs are still new and under heavy development, and so we make no implication yet on what an efficient PoDSI could look like, or the machinery needed to build a system around it. As there are solutions for compute on top of Filecoin data, the idea of a solution that computes a PoDSI on sealed or unsealed data may not be out of the realm of near-future possibilities.
As both the field of DA and Filecoin grows, new combinations of solutions and enabling technologies may enable new proof of concepts. As Solana’s integration with the Filecoin network shows, DSNs hold potential as a scaling technology. The cost of data storage on Filecoin provides an open opportunity with a large window of optimization. Although the challenges discussed in this article are presented in the context of enabling DA, their eventual solution will open a plethora of new tools and systems to be built beyond DA.
¹ Although this isn’t the construction of Filecoin, it is useful for those who are unfamiliar with programmable decentralized storage.
For more research pieces from Fenbushi Capital, check out their Medium page here.
To stay updated on the latest Filecoin happenings, follow the @Filecointldr handle.
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
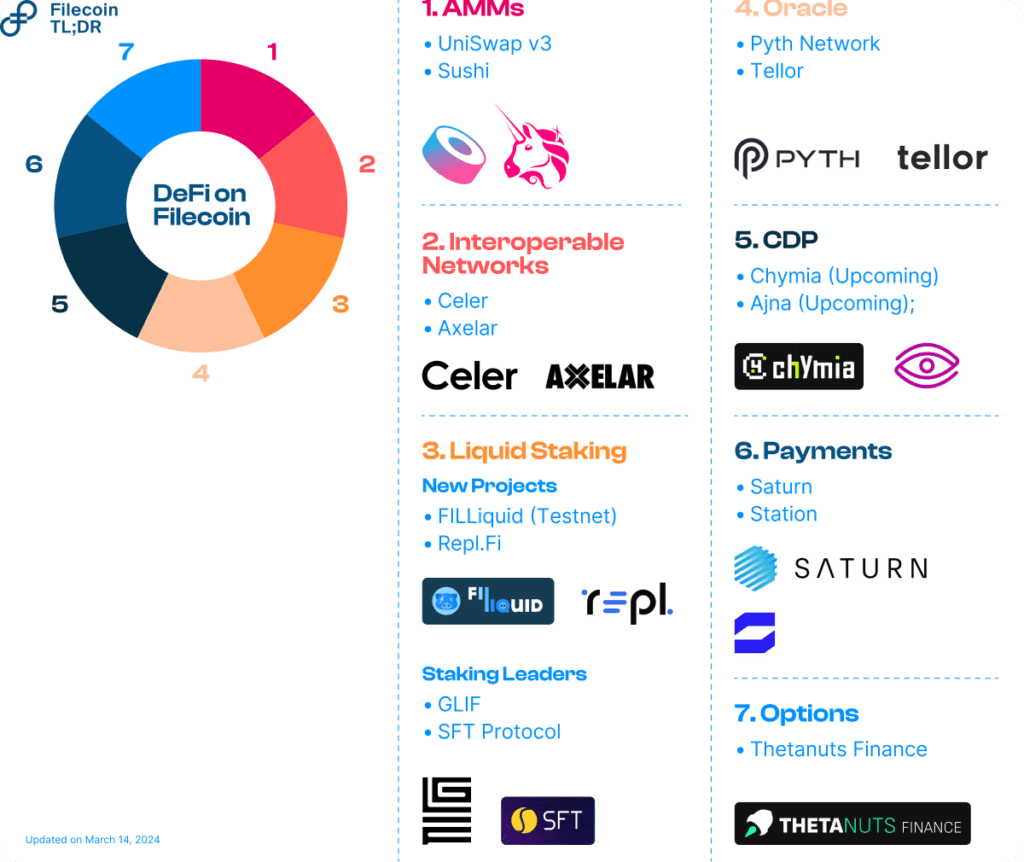
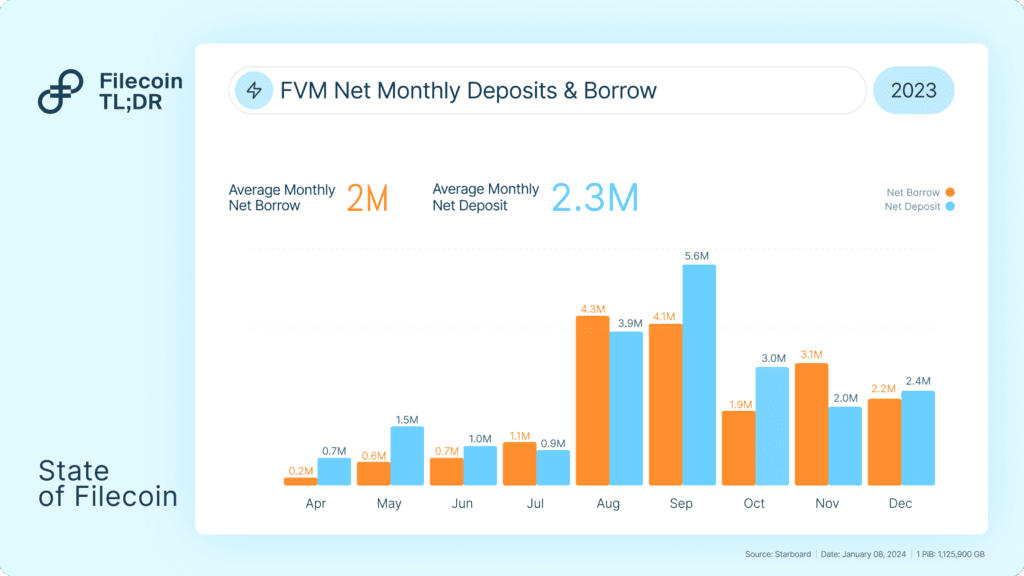
The Filecoin community celebrated the first anniversary of the Filecoin Virtual Machine (FVM) launch on March 14, 2024. The FVM has brought programmability to Filecoin’s verifiable storage and opened up a unique DeFi ecosystem anchored around improving on-chain collateral markets. Liquid Staking, for example, as a subset of Filecoin DeFi, has hit over $500 million in TVL. As the network grows, several critical infrastructures across AMMs, Bridges, Oracles, and Collateral Debt Positions (CDPs) are coming together to propel DeFi expansion in 2024.
In this blog post, let’s take a look at the latest DeFi projects launched on top of FVM and provide a view into future areas of activity.
DeFi Developments on FVM
Automated Market Makers
Automated Market Makers (AMMs) connect Filecoin with other Web3 ecosystems, enabling on-chain swaps, deeper liquidity, and fresh LP opportunities.
Decentralized Exchanges: ✅
Recently, leading Decentralized Exchanges Uniswap v3 (via Oku.trade) and Sushi integrated with Filecoin by deploying on the FVM. Oku Trade’s interface enables Uniswap users to easily exchange assets and provide liquidity on Filecoin. With this, FVM developers can effortlessly access bridged USDC and ETH assets natively on the Filecoin network, broadening Filecoin’s reach. As a foundational DeFi primitive, DEXes also opens the floodgates for non-native applications to leverage Filecoin’s robust storage and compute hardware.
Interoperability Networks
Bridges: ✅
Bridges help bring liquidity into DEXs and AMMs on FVM. For developers building on FVM, Bridges connects Filecoin’s verifiable data with tokens, users, and applications on any chain, ensuring maximum composability for DeFi protocols. For this purpose, messaging, and token bridging solutions by Axelar and Celer were added to the Filecoin network immediately post-FVM launch.
Today, AMMs Uniswap v3 and Sushi along with several other DeFi applications are natively bridged to Filecoin with the help of cross-chain infrastructure enabled by Axelar and Celer.
Liquid Staking
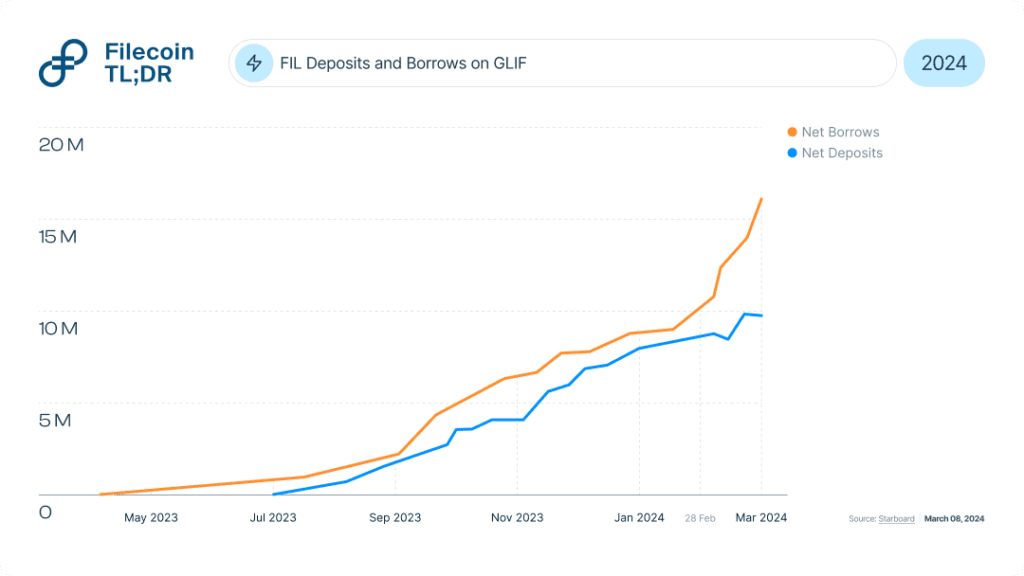
Liquid Staking protocols have been the prime mover within Filecoin DeFi. They’ve played a vital role in growing and improving on-chain collateral markets. Today, nearly 17% of the total locked collateral (approx. 30 million FIL) by storage providers comes from FVM-based protocols such as GLIF (52%), SFT Protocol (10%), Repl (9%) and the rest (29%). These protocols have increased capital access to storage providers while simultaneously enabling better yield access to token holders. Read more to learn how Filecoin staking works.
GLIF Points: 🔜
GLIF, the leading protocol on Filecoin, has a TVL of over $250 million. To put this into context, this surpasses the largest Liquid Staking protocols on L1 chains like Avalanche. As of writing this (March 06, 2024), 32% of all FIL stakes into GLIF liquidity pools were deposited shortly after its announcement to launch GLIF points (on Feb. 28, 2024), a likely precursor to a governance token.
Typically, to participate in the rewards program, GLIF users will have to deposit FIL and mint GLIF’s native token, iFIL. Similarly, the SFT protocollaunched a points program in 2023 based on its governance token to incentivize community participation.
Overall, we look forward to how the gameplay of points, popular among DApps in Web3 ecosystems, will act as a catalyst to decentralize governance and incentivize participation for Filecoin’s DeFi DApps.
New Staking Models: 👀
The influx of protocols experimenting with new models to inject liquidity into the ecosystem hasn’t slowed down. Two projects worth mentioning are Repl and FILLiquid.
Repl.fiintroduces the concept of “repledging.” Under repledging, SP’s pledged FIL are tokenized into pFIL, Repl’s native token, and used for other purposes including earning rewards. Repleding essentially increases the utility of locked assets thereby reducing opportunity costs for SPs. In just a few months after launch, Repl’s TVL has soared past $30 million.
FILLiquid, currently on testnet, models the business of FIL lending for SPs on algorithm-based fixed fees instead of traditional interest rates. The separation of payouts from the duration of deposits is expected to nudge long-term pledging and borrowing activities from token holders and SPs respectively, saving costs and increasing efficiency.
Price Oracles
Oracles, services that feed external data to smart contracts, are critical blockchain infrastructure essential for DeFi applications to grow and interact with the real world.
Pyth Network: ✅
Pyth recently launched its Price Feeds on the FVM. The integration allows FVM developers to access more than 400 real-time market data feeds while exploring opportunities to build on top of Filecoin’s storage layer. DeFi apps benefit from Pyth’s low-latency, high-fidelity financial data coming directly from global institutional participants such as exchanges, market makers, and trading firms.
Filecoin is also supported by Tellor, an optimistic oracle that gives FVM-based applications access to price feed data.
Collateralized Debt Positions
As DeFi activity on Filecoin is climbing, Collateralized Debt Positions (CDPs) will add more dimensions for other decentralized applications to build on FVM.
Chymia.Finance: 🔜
Chymia is an upcoming DeFi protocol on FVM. With a growing number of Liquid Staking Tokens (LST) on Filecoin, CDPs will extend the utility of locked tokens by generating stablecoins. Through Chymia, holders of LST can generate higher yields while using it as collateral for deeper liquidity.
Ajna: 🔜
Ajna is a noncustodial, peer-to-pool, permissionless lending, borrowing, and trading system requiring no governance or external price feed to function. As a result, any ERC20 on the FVM will be able to set up its own borrow or lend pools, making it easier for new developers to build a utility for their protocols.
Payments
Adjacent to storage offering on Filecoin, the FVM allows developers to bind DeFi payments to real-world primitives on the network. Built intuitively, Filecoin’s core economic flows enable paid services to settle on-chain. Station and Saturn are two notable Filecoin services to have successfully leveraged FVM for payments.
Filecoin Station: ✅
Station is a downloadable desktop application that uses idle computing resources on Station’s DePIN network to run small jobs. Participants in the network are rewarded with FIL earnings. Currently, Station operates the Spark and the Voyager modules, both aimed at improving retrievability on the network. In February, roughly 1,900 Station operators were rewarded with FIL for their participation.
Filecoin Saturn: ✅
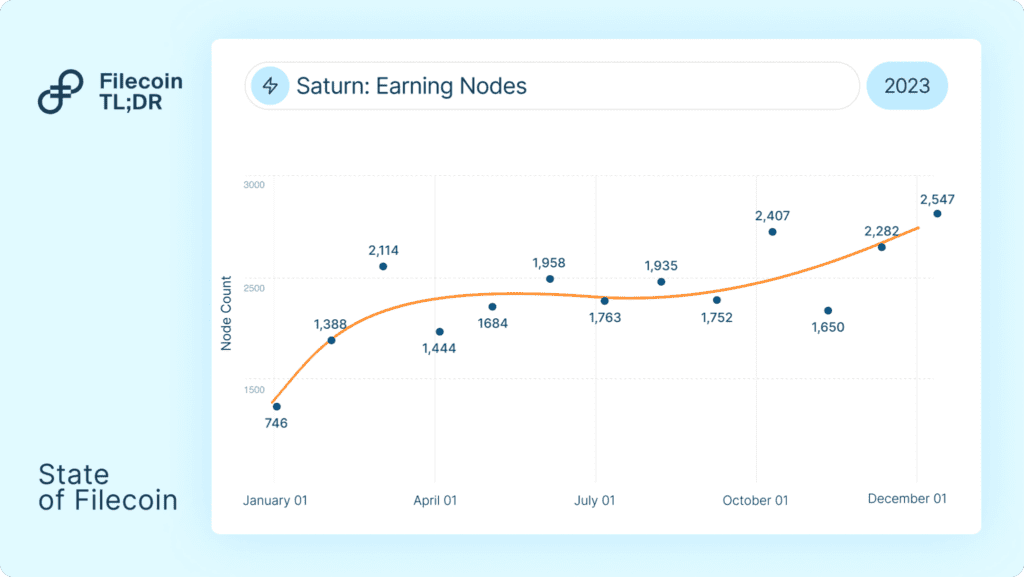
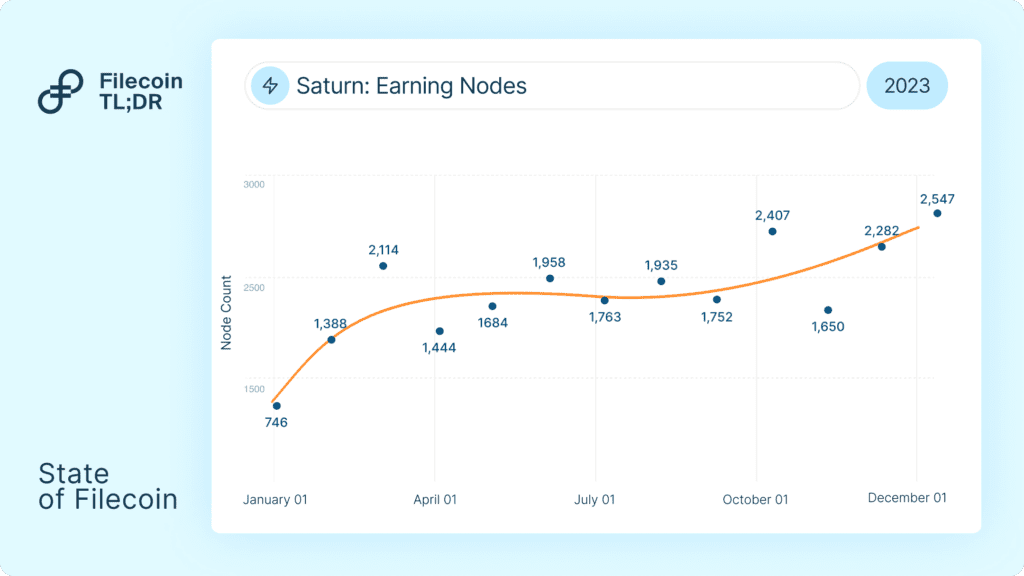
Saturn, a decentralized CDN network built on Filecoin, also leverages FVM for disbursing FIL payments to retrieval nodes on the network. In 2023, Saturn averaged over 2,000 earning nodes (retrieval providers on the network receiving FIL) for their services.
Decentralized Options
With growing liquidity, options are yet another emerging product in DeFi. Options facilitate the buying or selling of assets at a predetermined price on a future date, giving token holders protection against price volatility and an opportunity to speculate on market moves.
Thetanuts:✅
Currently, Thetanuts Finance, a decentralized on-chain options protocol supports Filecoin. The platform allows FIL holders to earn yield on their holdings via the covered call strategy. Thetanuts FIL-covered call vaults are cash-settled and work on a bi-weekly tenor.
Wallets
To use dApps on the FVM, users would be required to hold FIL in a f410 or 0x type wallet address. Over time, many Web3 wallets such as MetaMask, FoxWallet, and Brave have started supporting 0x/f410 addresses. MetaMask also supports Ledger. With this, it is possible to hold funds in a Ledger wallet and interact with FVM directly.
In addition, exchanges like Binance natively supporting the FEVM drastically reduce complexities for FVM builders. To learn more about the most recent wallet upgrades, visit the Filecoin TLDR webpage.
What’s Next?
The obvious near-term impact of various integrations across AMMs, Bridges, and CDPs is a fresh influx of liquidity into the Filecoin ecosystem. Liquidity begets deeper liquidity with an increase in the number and diversity of DeFi protocols on Filecoin. DeFi’s growing economy clubbed with more services coming on-chain and utilizing FVM for payments will overall increase the revenue and utility of the network. We expect this strong DeFi traction to scale Filecoin as an L1 ecosystem, with core services of storage and compute becoming the backbone of the decentralized internet.
To stay updated on the latest Filecoin happenings, follow the @Filecointldr handle.
Many thanks to HQ Han and Jonathan Victor for reviewing and providing valuable insights and to all the ecosystem partners and teams for their timely input.
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
2023 marked significant shifts in technology and adoption for the Filecoin network. From the launch of the Filecoin Virtual Machine, to other developments across Retrievals and Compute, 2023 lay the foundation for Filecoin’s continued expansion. This blogpost will provide a summary of the notable milestones the Filecoin ecosystem reached in 2023, and in the later portion, growth drivers to watch for 2024.
TL;DR
2023 Retrospective:
Storage: Active deals reached 1,800 PiB, and storage utilization grew to 20%
FVM: FVM launch in March 2023 enabled FIL Lending (Staking) which supplied 11% of total collateral locked by Storage Providers; TVL broke USD 200M
Retrievals: Retrievability of Filecoin data improved, alongside notable releases from Saturn (3,000+ nodes, sub 60ms TTFB) and Station
Compute, AI and DePIN networks: Synergistic growth of Filecoin together with physical resource & compute networks
Web2 Enterprise Data Storage: Led by strengthened offerings by teams such as Banyan, Seal Storage, and Steeldome
Continued DeFi growth: DEXes, Oracles, CDPs, spurred by service revenue coming on-chain
2023 Retrospective
To recap, Filecoin enables open services for data, built on top of IPFS. While Filecoin initially focused on storage, its vision includes the infrastructure to store, distribute, and transform data. The State & Direction of Filecoin, Summarized blog post shared an initial framework for Filecoin’s key components. This framework will serve as an anchor for discussing 2023’s traction.
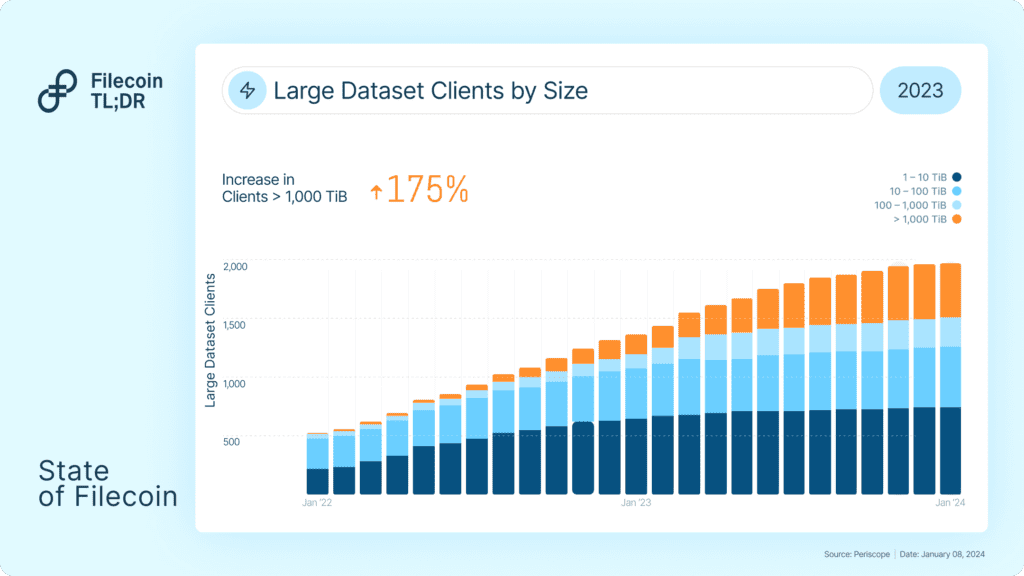
1) Storage Markets: Active storage deals reached 1,800 PiB with storage utilization of 20%
In 2023, Filecoin’s stored data volume grew dramatically to 1,800 PiB, marking a 3.8x increase from the start of the year. Storage utilization grew to 20% from 3%. Currently, Filecoin represents 99% market share of total data stored across decentralized storage protocols (Filecoin, Storj, Sia, and Arweave).
Growth in Active Storage Deals was driven by two factors:
1) Storing data was easier in 2023. Continued development across on-ramps such as Singularity.Storage, NFT.Storage, and Web3.Storage increased Web3 adoption. Singularity alone onboarded 180 plus clients and 270 PiB of data. This growth was enabled by advances in its S3 compatibility, data preparation, and deal making.
2) Large dataset clients grew exponentially in 2023. Over 1,800 large dataset clients onboarded datasets by the end of 2023, from an initial base of 500 plus clients. 37% of these clients onboarded datasets exceeding 100 TiB in storage size.
2) Retrievals: Greater reliability for Filecoin Retrievals, alongside releases from Saturn & Station
Filecoin’s retrieval capabilities were bolstered by improvements both in its tooling and offerings. Several teams, such as Titan, Banyan, Saturn and Station, are laying the groundwork for new use cases to be anchored into the Filecoin economy, including decentralized CDNs and hot storage.
Saturn: A Decentralized CDN
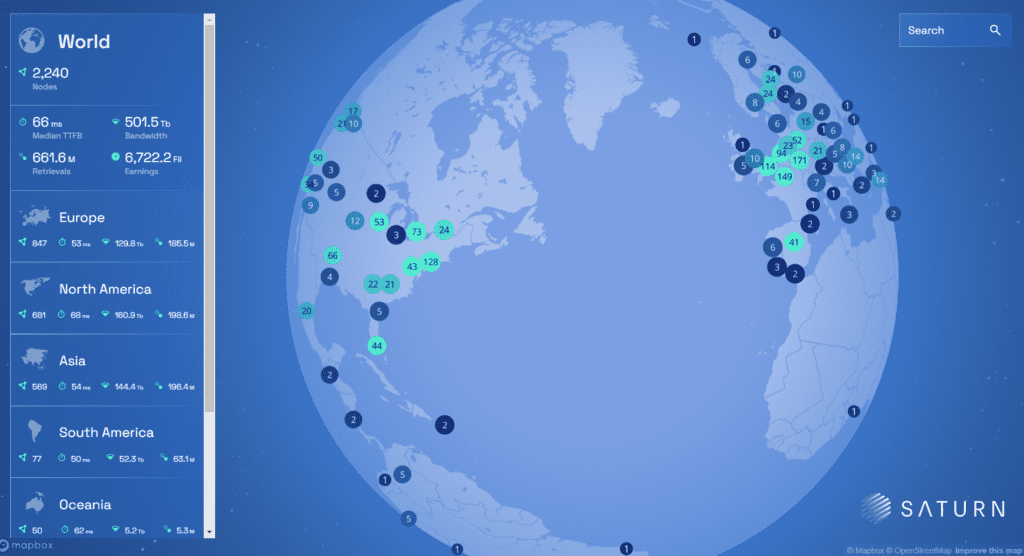
Saturn is a decentralized CDN network built on Filecoin, that seeks to address the need for application-level retrievals. The Saturn network currently has over 3,000 nodes distributed across the globe, enabling low-latency content regardless of location.
Distribution of Nodes: 35% in North America, 34% in Europe, 24% in Asia, 7% RoW Source: Saturn Explorer as of January 08, 2024
Across 2023, Saturn reduced its effective Time-to-First-Byte (median TTFB) to 60 milliseconds. This makes Saturn the fastest dCDN for content-addressable data, with TTFB remaining consistent across all geographies. Saturn was also capable of supporting 400 million retrieval requests on its busiest day of the year.
At the end of 2023, Saturn launched a private beta for customers (clients include Solana-based NFT platform Metaplex).
Station: A Deploy Target for Protocols (Enabling Spark Retrieval Checks)
Station, a desktop app for Filecoin, was launched in July 2023. Station is a deployment target for other protocols allowing DePIN networks, DA layers, and others to run on a distributed network of providers.
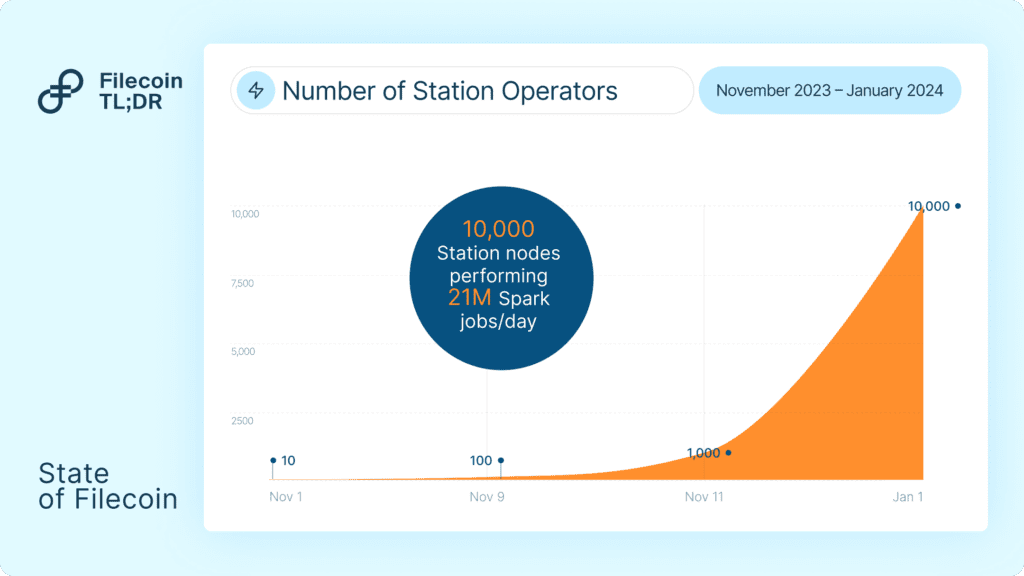
Station’s first module, Spark, is a protocol for performing retrieval checks on Storage Providers (SPs). Spark helps establish a reputational base for SP data retrievability, and supports teams looking to provide a hot storage cache for Filecoin. Since launch in Nov 2023, Spark has grown to 21 million daily jobs on 10,000 active nodes as of January 2024.
3) Filecoin Virtual Machine: The FVM launch introduced a new class of use cases for the Filecoin Network. Early DeFi adoption broke $200 million in TVL.
The Filecoin Virtual Machine (FVM) launched in March 2023 with the EVM being the first supported VM deployed on top. FVM brought Ethereum-style smart contracts to Filecoin, broadening the slate of services anchoring into Filecoin’s block space. Two areas of early adoption have been in liquid staking services (led by GLIF and other DeFi protocols) and micropayments via the FVM.
Liquid Staking
One of the core economic loops in the Filecoin economy is the process of pledging, where SPs put up collateral to secure capacity and data on the network. Prior to the FVM, borrowed Filecoin collateral was sourced through managed offerings from operators like Darma Capital, Anchorage, and CoinList. Post-FVM, roughly a dozen staking protocols have launched to grow Filecoin’s on-chain capital markets.
In aggregate, FVM-based protocols supply almost 11% of the total locked collateral (approx. 19 million FIL) on the network, giving yield access to token holders, and increasing the access to capital for hundreds of Filecoin SPs. From Filecoin’s collateral markets alone, the ecosystem has broken past 200 million in TVL.
Payments
Adjacent to the core storage offering on Filecoin, new services are being built that anchor into Filecoin’s block space. As mentioned in the Retrieval Markets section, two notable services (Station and Saturn) have actually started leveraging FVM for payments in 2023.
To date, Station users have completed 161 million jobs with more than 400 addresses receiving FIL rewards. Saturn averaged over 2,000 earning nodes in 2023 with 448,905 FIL disbursed to date.
4) Compute: Traction for Decentralized Compute Networks
Filecoin’s design enables compute networks to run synergistically on Filecoin’s Storage Providers. Sharing hardware with compute networks is also valuable to the Filecoin network: (1) sharing allows Filecoin to offer the cheapest storage by running side-by-side with compute operations, and (2) it brings additional revenue streams into the Filecoin economy.
Two key developments made running compute jobs on Filecoin nodes:
Sealing-as-a-service: Sealing-as-a-service is the process by which Storage Providers (SPs) can outsource production of sealed sectors to third-party marketplaces. This gives SPs greater flexibility in operations and reduces costs of sector production. One marketplace, Web3mine, has thousands of machines participating in its protocol offering cost savings to SPs of up to 70%. On top of the cost savings, the infrastructure built may also eventually benefit SPs by allowing them to leverage their GPUs for synergistic workloads (e.g. compute jobs)
Reduced Onboarding Costs:Supranational shipped proof optimizations reducing sealing server cost by 90% and overall cost of storage by 40%
On top of these developments, 2023 saw emerging compute protocols building in the Filecoin ecosystem. Two notable examples:
Distributed compute platform Bacalhau demonstrated real-world utility among Web2 and DeSci clients. Most recently, the U.S. Navy chose Bacalhau to assist them in deploying AI capabilities in undersea operations. Bacalhau is a platform agnostic compute platform intended to run on Web3 and Web2 infrastructure alike. Launched in November 2022, Bacalhau’s public network surpassed 1.5 million jobs and in some cases slashed compute costs by up to 99%
Source: Bacalhau
Up-and-coming compute networks likeIo.net allow ML engineers to access a distributed network of GPUs at a fractional cost of individual cloud providers. Io.net recently incorporated 1,500 GPUs from Filecoin SPs — positioning Filecoin providers to offer their services to Io.net’s customer base. Io.net has over 7,400 users since its launch in November 2023, serving 15,000 hours of compute to users.
2024 will be a critical growth year for Filecoin as groundwork laid in 2023 comes to fruition. Native improvements to storage markets, greater speed of retrievals, new levels of customizability & scalability brought by FVM and Interplanetary Consensus (IPC), all expand the universe of use cases that Filecoin can address.
In a Web3 climate where there is substantial attention on DePIN (and the tying of real world services with Web3 capabilities) these changes will be critical building blocks for even better services. Here are three themes to look for in 2024:
1) Synergies with Compute, AI and other DePIN networks
In 2024, foundational improvements to the network will substantially improve Filecoin’s ability to compose with other ecosystems.
Fast finality allows better cross-network interactions with app chains in other ecosystems (e.g. Cosmos, Ethereum, Solana).
Customizable subnets allow for novel types of networks to form on top of Filecoin such as general purpose compute subnets (e.g. Fluence) and storage pools (e.g. Seal Storage).
Hot storage allows for broader use case support including serving data assets for physical resource networks (e.g. WeatherXM/Tableland), caching data for compute networks (e.g. Bacalhau), and more.
This is all scratching the surface. As the Web3 space and DePIN category grows, Filecoin is well positioned to support new communities that form given its 9 EiB of network capacity and flexibility. There exists a sizable opportunity within physical resource networks producing high amounts of data, such as Hivemapper (over 100M km mapped), and Helium (1 million hotspots globally). Compute networks are also a likely growth area, given the backdrop of a GPU shortage (particularly for AI purposes) in traditional cloud markets.
Source: Messari
2) Focused Growth in Web2 Enterprise Data Storage
Web2 enterprise storage is a unique challenge for decentralized networks – requirements from these customers are not easily supported by most networks. Typical requirements from enterprise clients can include end-to-end encryption, certification for data centers, fast retrievals, access controls, S3 compatibility, and data provenance/compliance. Crucially, these requirements tend to differ across segments and verticals, which means that a level of adaptability is required. Filecoin’s architecture enables it to layer on support for the features these customers need.
A few teams worth keeping an eye on:
Banyan: Banyan simplifies how enterprise clients integrate with decentralized infrastructure by bundling hot storage, end-to-end encryption, and access controls, on top of a pool of high-performing storage providers. With the Filecoin network, Banyan provides content-addressable storage, which it plans to complement with hot storage proofs by utilizing FVM. This implementation makes Banyan compatible not only for enterprise, but DePIN and compute networks.
Seal: Seal has established itself as one of the best storage onramps in the Filecoin ecosystem, and is responsible for onboarding several key clients onto the network, such as UC Berkeley, Starling Labs, the Atlas Experiment, and the Casper Network. The team has been one of the driving forces in enterprise adoption to date, and most recently has achieved SOC 2 Compliance. In 2024, they plan on launching a subnet to enable a market for enterprise deals. On the back of their enterprise deal flow, they are positioned to bring petabytes of data into the network over the coming year via their new market.
Steeldome: Steeldome offers enterprise clients seeking data archival, backup and recovery with an alternative that is cost-competitive, efficiently deployed and scalable. It does so by combining Filecoin in its stack with Web2 technologies, allowing a fuller feature set to complement Filecoin’s cost-effective and secure archival storage. The Steeldome team has succeeded in onboarding clients across insurance, manufacturing, and media. In 2024, they plan to continue that trajectory, while offering a managed service for Storage Providers.
3) Greater On-chain DeFi activity
There is likely to be continued activity in the on-chain economy with an increase in the number and type of DeFi protocols on Filecoin.
The first protocols will increase service revenues (from Storage, to Retrievals, and Compute) coming on-chain. As previously described, more services are coming online in the Filecoin network, and are utilizing FVM for payments (e.g. Saturn, Station).
Key releases in 2023, including SushiSwap going live in Nov 2023, and the UniSwap community’s approval of integrating on FVM will lead to more diverse DeFi services coming on-chain. This will include CDPs (Collateralized Debt Positions), and Price Oracles (e.g. Pyth), among others.
Final Thoughts
In 2024, the Filecoin network will experience greater adoption, particularly by Compute, AI and DePIN networks, as well as targeted enterprise verticals. This adoption brings on-chain service revenue and supports the growth of DeFi activity beyond collateral markets. Continued improvements on storage markets, retrievability driven by hot storage proofs and CDN networks, as well as releases by FVM and IPC will enable the teams building on Filecoin to drive this next stage of growth.
To stay updated on the latest in DePIN and the Filecoin ecosystem, follow the @Filecointldr handle.
This blogpost is co-authored by Savan Chokkalingam and Nathaniel Kok on behalf of FilecoinTLDR. Many thanks to HQ Han and Jonathan Victor for reviewing and providing valuable insights and to all the ecosystem partners and teams for their timely input.
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
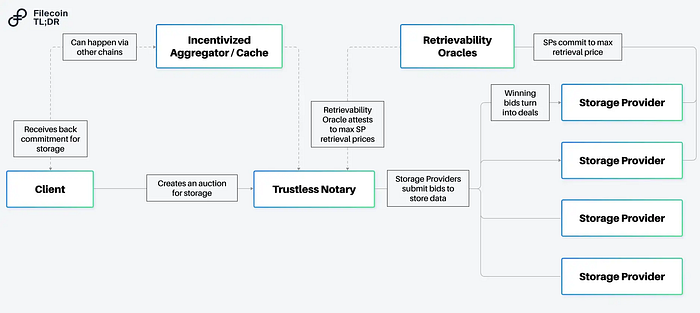
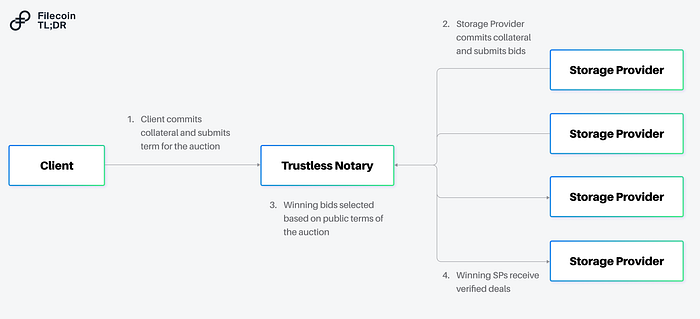
Filecoin’s larger roadmap aims to turn cloud services into permissionless markets on which any provider can offer their services. The network started with Storage markets, with the Mainnet launch in October 2022. More recently, the Filecoin Virtual Machine (FVM) was introduced to bring smart contract functionality onto the network. This allows for user programmability around key services on the Filecoin network: which includes Large-scale Storage, and soon, Retrievals.
In this post, we dive into the Retrieval markets that Filecoin is developing and one of its lighthouse projects. We will cover the following topics:
Filecoin’s Retrieval Markets and the Retrieval Markets Working Group (RMWG)
Content Delivery Networks (CDNs) and the role of Project Saturn
Saturn’s approach to a decentralized CDN and its traction to date
What’s next for Saturn
Filecoin’s Retrieval Markets and the RMWG
As covered earlier in our previous post, Filecoin seeks to build open services for data, which consists of three main pillars (Storage, Retrieval, and Compute-over-Data). Storage has been a key emphasis for Filecoin from 2020 to 2022 — it has emerged as the largest decentralized storage network to date, with over 1,170 PiB of data stored, and 200,000+ users ranging from Opensea to the Internet Archive. The remaining pillars of Retrieval and Compute-over-Data have been in development since 2022, with working groups (open for any individual or entity to join) organized around building these markets. The working groups encourage modularity and often consist of different teams that tackle different pieces of the puzzle.
Key components of Filecoin’s roadmap for open data services
The Retrieval Market Working Group (RMWG) is centered around building a decentralized CDN (Content Delivery Network) for the Filecoin ecosystem. Over 15 teams (such as Magmo, Ken Labs, Protocol Labs, and more) are contributing to tackling technical challenges in the space, from enabling ultra-fast payments to data transfer protocol enhancements to crypto-economic models for data retrieval. The following are building blocks the RMWG has been organizing itself around since H1 2022 and is built off an envisioned retrieval flow that can interact freely with Filecoin’s storage markets.
Building blocks of a functional retrieval markets identified by the RMWG
Even in its R&D stage, projects in the RMWG are already serving 160 million daily retrieval requests and more than 2 PB of data per month. Collectively, these projects will seek to enable a decentralized CDN that can serve not just the web3 space, but the web2 market as well.
CDNs and the role of Project Saturn
Content delivery networks are a key part of the Internet’s infrastructure. Groups of servers work together to provide fast delivery of internet content, from static web pages to YouTube videos. Incumbent CDN providers include players such as Cloudflare, Akamai, and Fastfly. Businesses pay for these services instead of the end-user, which means that service consistency, coverage, and pricing are critical.
Content Delivery Networks today are highly centralized and dominated by big players
The CDN market today is highly centralized and dominated by a few big players. Only 7 CDN providers serve over 80% of market needs. This brings about sizable concentration risk in the event of network failures (e.g. CloudFlare outage in 2022), and higher latencies in regions far remote from the closest data centers (e.g. Africa).
A distributed model of smaller CDNs in various regions could effectively solve these problems, but economies of scale have prevented smaller, distributed CDNs from challenging incumbent providers (capital outlay could reach up to billions per year). Delivering web content better than incumbent providers will open up a significant commercial opportunity. The global CDN market size accounts for US 20Bn in 2022 and is expected to reach around 100Bn by 2032 (not counting new web3-based use cases such as NFTs). This is where Project Saturn comes in.
A web3 CDN can potentially overcome this challenge by allowing anyone to contribute resources for content retrieval (provided they fulfill minimum criteria) in a network. This shifts the burden from a single company to thousands (or more) of companies supporting the network, reducing barriers to entry. This is where Project Saturn comes in. Project Saturn is a decentralized CDN network built on Filecoin, that seeks to enable reliable, performant, and economic retrieval of content on the Internet. It is one of the key projects in the RMWG, with a public launch in November 2022. Saturn seeks to achieve the following:
Democratize the CDN market, by allowing anyone to serve as a Saturn node operator in return for crypto-incentives. Nodes can join in a permissionless manner, allowing for multiple companies or individuals to contribute towards a retrieval network (think franchising), which leads to a wider and more distributed footprint
Performant retrievals, with under 100ms TTFB, high network bandwidth, and low latency across all geographies, owing to a high density of nodes being distributed across each continent. While this does not exist today, it can potentially be achieved given a wider geographic distribution of nodes
No single point of failure unlike traditional CDN networks
Data integrity and authenticity by leveraging content-addressability. Project Saturn is the only decentralized CDN that is natively compatible with content-addressing
Saturn approach and traction to date (Aug 2023)
The data below is accurate as of August 2023, unless otherwise stated. Data for number of Active Nodes are accurate as of November 2023, owing to a upgrade in October 2023 that removed multi-noding behavior in the network, while keeping TTFB performance stable.
While Saturn’s ambition is to serve as a credible alternative to traditional CDN networks, its near-term goal is to effectively fulfill the billions of requests received each week for content-addressed data on Filecoin and IPFS. This is currently being fulfilled by IPFS Gateway, which serves as a key benchmark for Saturn as it improves its network capacity and performance.
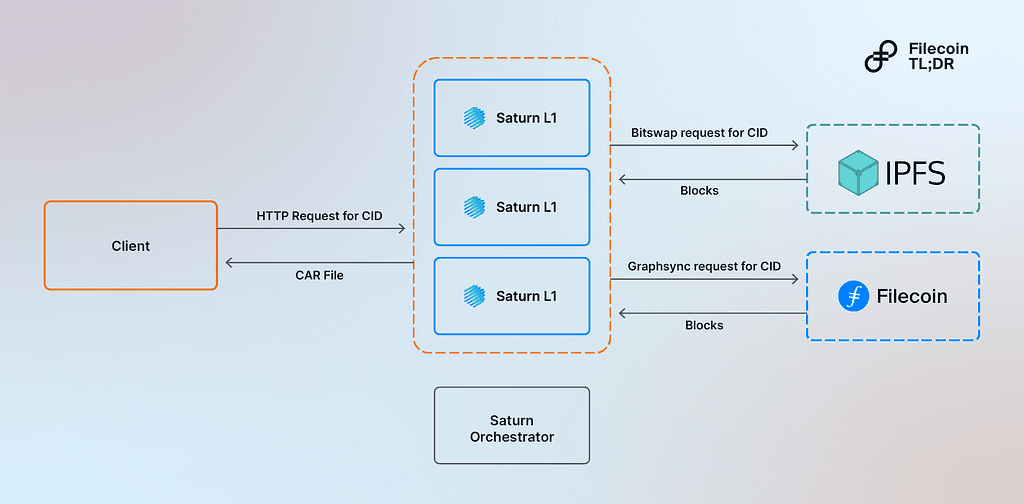
Flow chart for how network actors in Saturn enable retrievals from Filecoin and IPFS
Saturn’s approach involves four main network actors in enabling retrievals from Filecoin and IPFS:
Node operators offer their hardware and resources to the Saturn network by running Saturn nodes in different geo-locations around the world. They are rewarded based on how many bytes they serve to clients over each payment epoch. Saturn nodes join the network by registering with the Saturn Orchestrator. The network of Saturn L1s provides a huge geographically distributed cache of content-addressed data for Saturn clients
Saturn Orchestrator manages the membership of node operators in the Saturn Network and facilitates the payment process to these nodes. This is a key function in democratizing data retrievals while ensuring that qualified participants enter the market. Over time, the aim is for the orchestrator to run entirely on theFilecoin Virtual Machine (FVM)
Clients: Network users make requests for content from the Saturn network. The Client is the device used to make the request. Clients make HTTP requests to the Saturn network and get back CAR files, allowing clients to verify the file incrementally. When a Saturn L1 doesn’t have a file in its cache, it “cache-misses” to wherever the file is stored in either the IPFS Network or the Filecoin network, and returns it to the client
Customers use the Saturn Network as a CDN to accelerate their content to their users. Saturn customers can accelerate their content to a large number of Saturn nodes around the world to create a performant experience for end users
Significant developments have been made on Project Saturn to date. Following its public launch in November 2022, Saturn now has 80ms Time-to-first-byte (TTFB) at the 50th percentile, serves 30% of mirrored traffic from IPFS.io via the Bifrost Gateway, and has launched a verifiable node reward payout system on FVM.
It also has made significant headway in developing a network that is geographically diverse, capable of handling high-volume requests, and able to deliver content in a performant manner (low time-to-first byte). Since its public launch (just 8 months), Saturn has achieved:
Over 2,000 global points of presence (across 59 countries)
Capacity to serve 478 Million requests each day (in July 2023)
80 milliseconds time-to-first-byte (TTFB) for IPFS content
1) Over 2,200 retrieval providers worldwide (comparably distributed to traditional CDN providers)
Over 2,200 retrieval providers are currently on Saturn contributing to network bandwidth. This is a strong 11.8% MoM (month-on-month) growth, starting with only 662 nodes at the end of 2022. As a point of comparison, Filecoin’s storage markets grew by 21% MoM in its first 6 months, with approximately 3,500 storage providers on the network today (the largest in the web3 storage space)
This is comparably distributed to traditional CDN providers today. Akamai, the largest CDN globally, with a 35% market share, also has over 4,000 points of presence globally, while the next closest player (Alibaba) has only an estimated 2,800 points of presence (with the majority in China).
This speed of growth attests to the accessibility of serving as a retrieval provider on the Saturn network. It takes only 4 terabytes (TB) of storage and Saturn’s open-source software to run a Saturn CDN node (considerably less resource-intensive than being a storage provider on Filecoin). Saturn will allow more individuals to participate in Filecoin’s decentralized markets for data services.
Source: Saturn Explorer Nov 2023 (Explore Project Saturn’s live representation of nodes here)
Participation across geographies remains diverse: with the most nodes in Europe (800+), followed by North America (600+), and Asia (500+). Median TTFB remains consistently low across all continents, with Europe, Asia, Oceania, and South America experiencing sub-100 ms TTFB.
Distribution of these nodes is important, as it allows for the lowest possible distance between clients and nodes, translating to low latency for end-users (overcoming the speed of light problem experienced with traditional CDN providers). Saturn’s permissionless and crypto-incentivized attributes allow for a more ‘elastic’ supply to match with fast demand growth in developing regions like Asia and Africa, which are currently experiencing those latency issues today.
2) Saturn served an average of ~10.3 Billion requests monthly across 2023
Saturn has a network capacity of around 25+ terabits per second (approximately 10% of the network capacity of Cloudflare). An average of 10.3 Billion requests are served monthly across 2023, with 3.7 Million Gigabytes of monthly bandwidth served. Over 478 million daily requests were being handled as of the end of July 2023, which is close to 50% of IPFS Gateway’s daily requests in the same time frame. Despite its progress thus far, there remains room for stabilization in Saturn’s network capacity.
Source: Project Saturn data
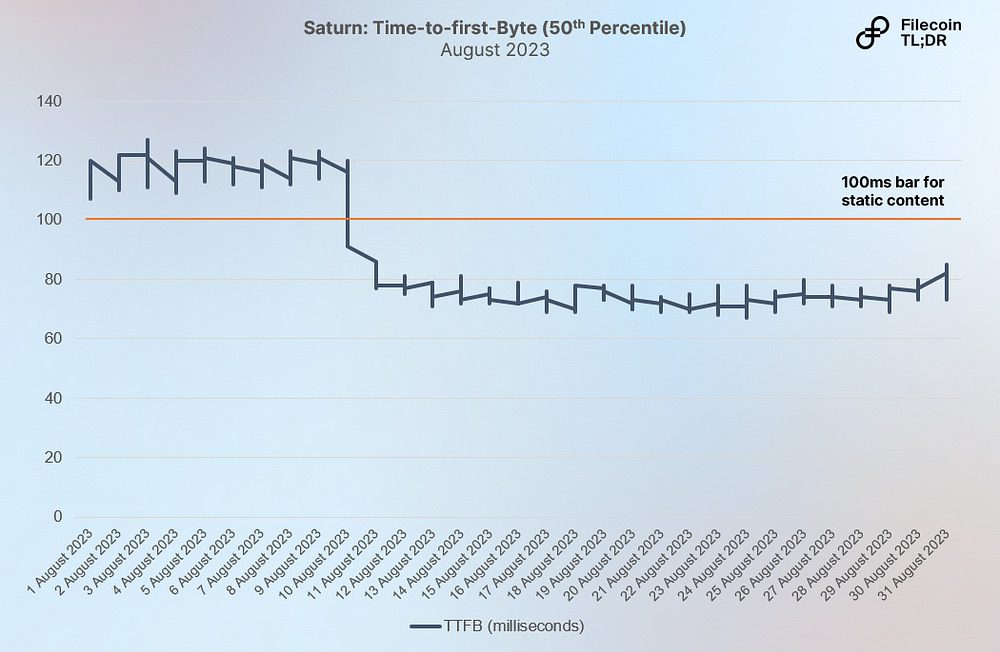
3) Time-to-first-Byte is already under 80 milliseconds
Speed is an area where Saturn has shown significant results; the median TTFB (time-to-first-byte) is already under 80 milliseconds. Typically, a good TTFB lies below 100 ms for static content, and 200–500 ms for dynamic content. Saturn today is already the fastest content-addressable CDN globally with 80 ms TTFB and has further headroom for improvement as the network continues to become denser. Aside from Saturn, there also exist parallel developments to drive improved retrieval performance in the Filecoin network. This includes projects such as Rhea, which is seeking to optimize IPFS Gateway performance.
Source: Project Saturn data
What’s next for Saturn
Since its public launch, Saturn has achieved significant progress as an open-source, community-run CDN network. Moving forward, the team looks to continue pushing towards better TTFB speeds, while improving performance correctness and latency. Towards the end of 2023, Saturn looks to achieve further milestones. These include serving 100% of IPFS.io traffic, implementing metering and billing on the customer demand side, and launching a web app to enable customer self-onboarding who want to accelerate content with Saturn.
Upcoming milestones in Project Saturn’s roadmap
You can keep up to date with Project Saturn, and other projects within the RMWG here. Data in this post is accurate as of 31st August 2023 unless otherwise stated.
Many thanks to the amazing HQ Han, Jonathan Victor, Alexander Kintsler, and the Project Saturn team for their input in publishing this piece.
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
Editor’s Note: This blog is a repost of original content from IOSG Ventures. IOSG Ventures is a community-friendly and research-driven early-stage venture firm. This blog post represents the independent views of the author, who has given permission for re-publication.
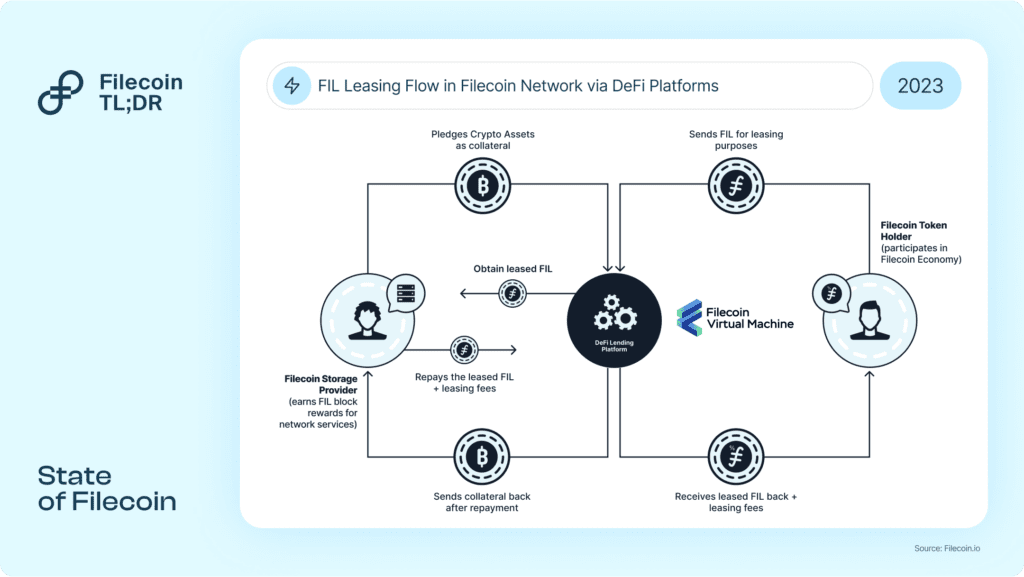
The programmable layer on FIL, the FVM, allows for trustless marketplaces to be built
This calls for a need for a marketplace that currently exists off-chain, i.e. FIL borrowing to be brought on-chain, where FIL token holders lease their FIL to Storage Providers (which some call “miners”) who borrow FIL from the pool(s)
FIL borrowing is essentially taking cash forward on the future block rewards accrued by the Storage Providers, and this makes FIL block rewards from data storage more capital-efficient
There are obvious trade-offs to be made between centralization-capital efficiency- and security in protocol design
The market size for borrowing FIL is reducing over time but the introduction of stablecoins, etc. Can unlock unique projects to be built on top of these protocols
The launch of a programmability layer on a seasoned blockchain generally comes with a lot of excitement. The launch of Stacks (STX) on the Bitcoin blockchain brought a new paradigm of thinking amongst the community built around it.
A very similar narrative happened with the launch of the FVM on Filecoin. The robust Filecoin community now has to see its vision through a completely different lens. A lot of open problems that the ecosystem had could now be addressed. Creating trustless marketplaces via programmability was a key piece of the puzzle.
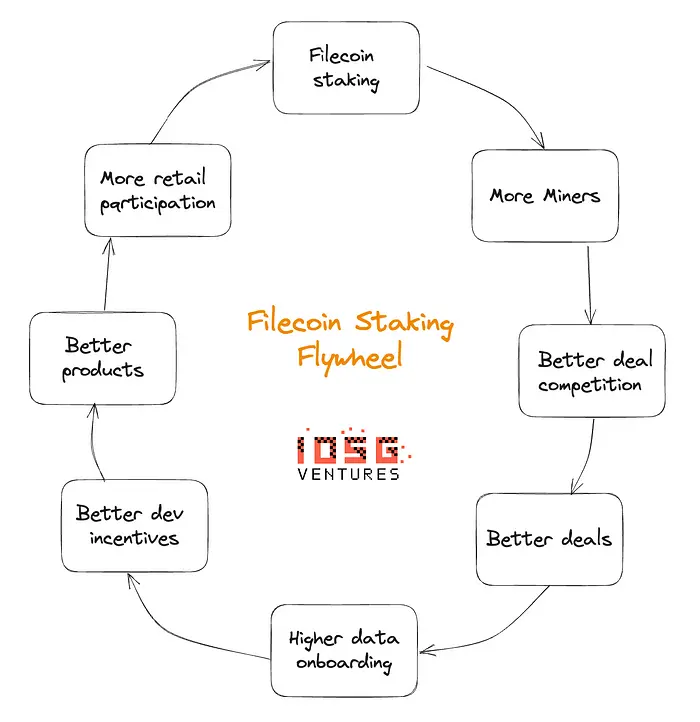
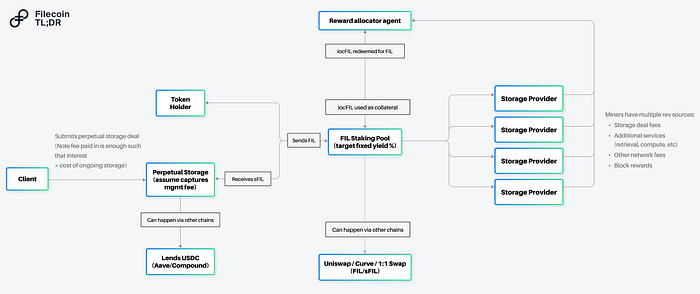
Liquid staking on Filecoin was the first “Request-for-build” from the Filecoin ecosystem during the launch of FVM and was given high importance. To understand why this is, let us first understand how the economics of Filecoin work.
How Filecoin Incentives Work
Unlike an Ethereum validator, there is no one-time staking in Filecoin. Every time a Storage Provider (SP) provides services, they need to put up a pledge amount in FIL. This pledge is required to seal the sectors and store the sealed sector in the SP. Such a structure ensures that the SP is going to store data for their clients for the period of the deal that they agree to, in exchange for rewards. Rewards are distributed via PoSt (Proof of Space-Time), where the SPs are rewarded for proving that they have the right client data stored.
SPs are selected via a leader selection mechanism called DRAND. DRAND chooses the leader with some initial requirements and also the % of raw byte power of the network controlled by the SPs.
SPs will have to keep ramping up raw byte power (RBP) to be chosen as the leader to “mine” a block and receive incentives. This helps the SP subsidize their storage costs.
Although there are many more factors that govern the supply rate of these incentives, the baseline is that for storage providers/miners, to maximize their bottom line will have to try to maximize RBP and onboard (and renew) more deals.
This creates a positive loop for the Filecoin network
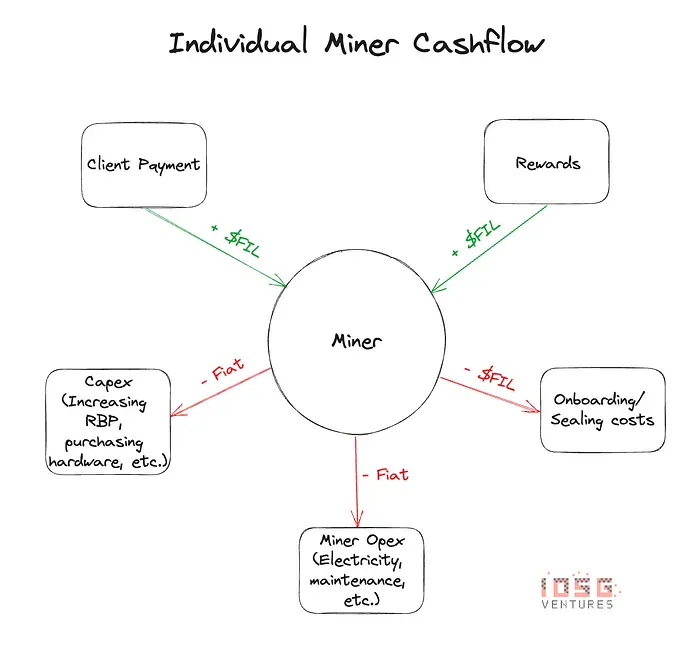
Economics of a Storage Provider
When an SP receives block rewards, these rewards are not liquid. Only 25% of the rewards are liquid, and the remaining 75% of the block rewards vest linearly over 180 days (~ 6 months). This poses a problem for SPs. The rewards, which are supposed to be an SP’s operating income, are now delayed payments for as long as the SP onboards/renews deals.
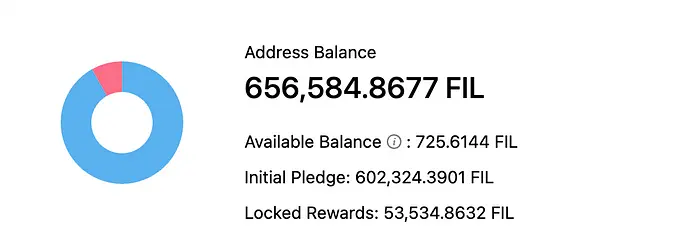
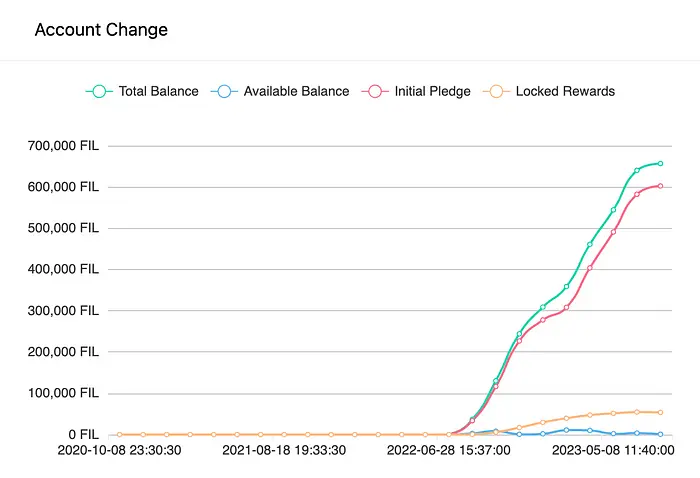
Let us look at the SP balance of the top miner in the network (as of 6th August 2023)
When you look at the graph, one can see that only about 1% of the rewards (or operating income) of the SP is actually liquid. If this SP now wants to either:
Pay for operating income
Upgrade hardware
Pay for maintenance
Or onboard/ renew deals
The SP will have to either borrow fiat currency or borrow FIL from third parties just to make up for these “delayed” payments.
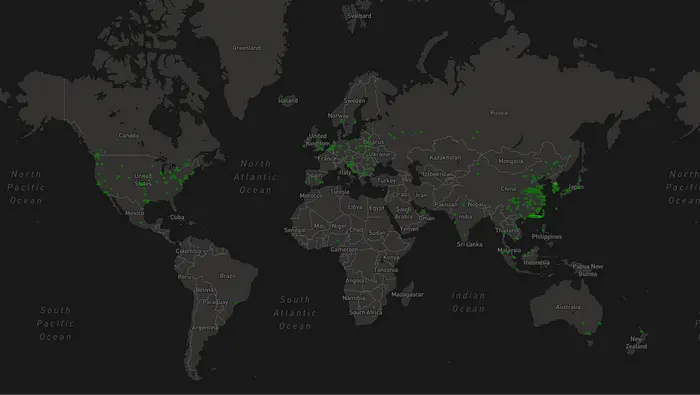
At the moment many storage providers (miners) in the network rely on CeFi lenders such as DARMA Capital, Coinlist, and a few others. As these are loan products, storage providers will have to go through KYC and a strict audit process to be able to borrow FIL. When we look at the map below, we can see a very high concentration of Filecoin SPs in Asia, and with centralized providers being mostly in the West, it is very hard for them to underwrite FIL loans to Asian miners with favorable terms, and most Asian miners/ SPs don’t have access to such providers.
This becomes a hindrance for new SPs to come in and participate in the system, and existing SPs can scale their business only as much as the total FIL pool size of these CeFi lenders
So why not just borrow fiat currency from a bank? With FIL being a volatile asset, it will pose additional capital management challenges for SPs who borrow.
To solve this problem, there needs to be a marketplace for FIL lenders (who could be holders of FIL) and FIL borrowers (SPs)
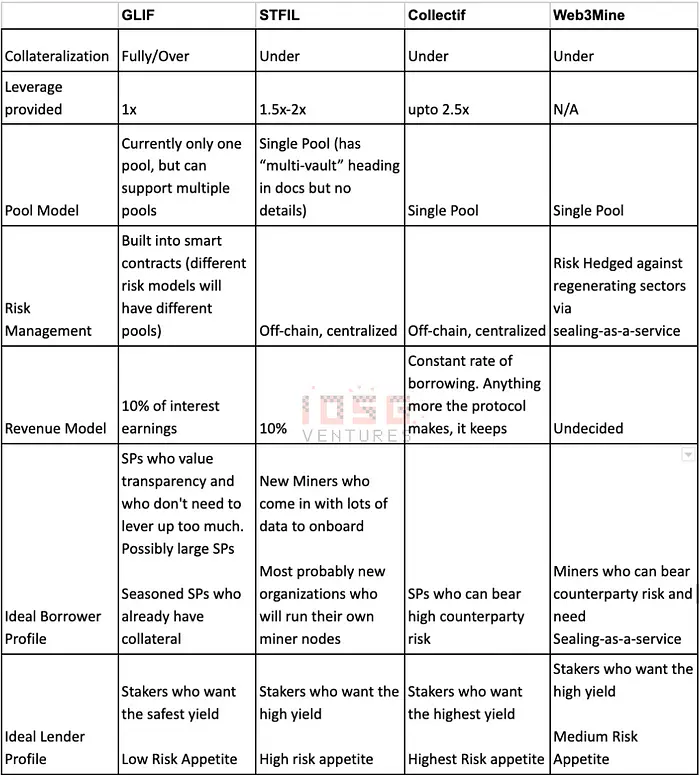
Filecoin Staking
With the launch of the FVM, this marketplace idea can come to fruition. FIL lenders/stakers can now put their FIL to work and SPs can borrow from this pool (either in a permissioned or permissionless manner) all governed by smart contracts.
There are many players in the ecosystem who are already building this and waiting to launch in the coming months.
More than calling such marketplaces staking protocols, it is a lot closer to a lending protocol by the nature of this business.
Some base features of such a FIL lending product would be:
Lenders deposit idle FIL and receive a “liquid staking” token
Borrowers (SPs) can borrow from the pool against collateral that exists in the SP actor (Essentially Initial Pledge + Locked Rewards)
Borrowers will make interest payments every week, or any specified time period, by signing over the “OwnerID” of the SP to a smart contract
Lenders receive the interest (minus protocol fees) as APY either via a rebase token or a value accrual token
Different liquid staking protocols have different schools of thought when it comes to borrowing:
Over/ Fully collateralized vs. Undercollateralized
In Over-collateralized or fully collateralized models, the debt-to-equity ratio is always going to be less than or equal to 100%. This means that if my SP balance is say 1000 FIL, I can only borrow up to 1000 FIL (depending on the protocol rules as well). This can easily be coded into smart contracts and default risk is built in. This allows for greater transparency and also security to the stakers (lenders). Another advantage of such a model is that it allows for permissionless borrowing as well. This is where the product blocks more like Aave/ Compound rather than a Lido or RocketPool.
In an uncollateralized model, the lenders are bearing risk while the risk is being managed by the protocol. In such a model, risk modeling is complex math that cannot be baked into smart contracts, and needs to be off-chain which sacrifices transparency. But, since there is leverage involved, it makes the system a lot more capital-efficient for the borrower. The more permissionless a leveraged system will get, the more risk the lenders bear and this would call for a very robust and dynamic risk management model that is run by the protocol developers
The trade-offs being made are:
Capital efficiency vs. staker risk
Capital efficiency vs. transparency
Lender risk vs. borrower entry to the system
Single Pool vs Multi-Pool
Protocols can also opt to build a multi-pool model where lenders can choose to stake FIL in different pools with different risk parameters. This allows for risk to be managed on-chain, but liquidity will be fragmented. In a single-pool model, risk will have to be maintained off-chain. Overall the trade-offs will still remain the same as the ones mentioned above.
Trade-off: Liquidity fragmentation vs Risk management transparency
Risks
In an overcollateralized model, even if the miner gets slashed multiple times, as soon as the Debt-to-equity ratio hits 100% the miner will get liquidated and the stakers will be comparatively safe
In an undercollateralized model, the borrowers can be penalized for failing to prove sectors. There are many more faults in failing to prove data storage rather faults in the consensus itself. This is more common in Filecoin than in other general-purpose blockchains because there is an actual commodity that is being stored from an off-chain entity. This will affect the collateral value and lever the borrower more. Liquidation thresholds will have to be set very carefully in such a model.
What about Ethereum Staking/Lending protocols entering the market?
In the Filecoin ecosystem, unlike the Ethereum ecosystem, the nodes (Miners/Validators/SPs) are responsible for much more than general uptime. They are supposed to market themselves to be chosen as SPs, and regularly upgrade their hardware to support more storage, seal, store, maintain, and retrieve data. Filecoin storage and reward mining for SPs is a full-time job.
Unlike an Ethereum validator, there is no one-time staking in Filecoin. Every time an SP provides storage to a client, they need to put up a pledge. This pledge is required to seal the sectors and store the sealed sector in the SP. Storage provision on Filecoin is a very capital-intensive process and this discourages many new SPs from participating in the network and existing SPs from staying and contributing to the network.
Since the participants on the borrow side are SPs only it is also going to be intensive for newcomers in the Filecoin ecosystem to bootstrap borrower trust.
The mechanics of Filecoin alone don’t allow Ethereum staking or even lending protocols to deploy easily on the FVM.
Economics of the Protocol
Is there enough FIL in the market to supply for lending?
As of August 6th, 2023, there are about 264.2 million FIL circulating that are not committed as sector pledges or rewards that are to be released. This can be counted as the total amount of FIL that can be staked by the lenders into the pool
While FIL borrowing is essential to SPs, what are they actually borrowing? They are taking a forward payment on their locked-up rewards in an overcollateralized model, and in the undercollateralized model, they are taking a forward payment on future rewards.
Looking at the graphs above, we can see that the total locked rewards are about 223M FIL, and the supply can match the demand. The demand-to-supply ratio is almost 84%. This shows even power dynamics on either side, and either side cannot squeeze the other on interest rates/ APY.
What does the future look like?
Estimating the market for future demand of FIL for borrowing is essentially the amount of FIL that will be released in the future as rewards.
The good folks at Messari ran a simulation of FIL circulating supply with a 3-year and a 50-year forecast using different cases.
According to the top left graph, considering a conservative scenario where there is low onboarding of data and only 10% of the total deals are renewed, the new reward emissions over 3 years are close to around 100M FIL and in an aggressive scenario where there is a high amount of data onboarding and 70% of existing deals renewed, the extra rewards come to about 200M FIL
So one can expect a market size of somewhere between 100M — 200M FIL over the next 3 years. At the current price of FIL (Aug 6th), which is $4.16, there could be a borrowing TAM of about $400M — $800M. This could be counted as the TAM of the product’s borrow side.
On the supply side, in the conservative estimate, there can be about 300M FIL that will be emitted, and in a more aggressive scenario, the circulating supply is simulated to be around the same as it is today. Why? It is because if more deals are being onboarded and renewed, there will be a lot more FIL locked-in sector pledges.
In the more aggressive scenario, the demand is going to outweigh the supply and the interest charged can be higher in this competitive market.
Where I think this can go
Amongst the different designs, there need not be a winner-takes-all type of model. Intuitively, the long-term winner (by TVL) is generally the protocol that is built most safely. Very much like Lido in the Ethereum ecosystem. I for one am biased towards safer structures more than optimizing for 2–3% more yield, and I think FIL whales would also prioritize capital safety over a slightly higher yield.
This is after considering the amount of penalties miners pay for not being able to prove space-time.
From the borrower (SP) end, the SP could borrow from different protocols for different purposes. If the SP already has a lot of collateral and doesn’t need to lever up to pay for opex, then the safer, overcollateralized model will work better, since it is safer. Whereas if I am a newer SP with a lot of sectors to be pledged I would borrow with leverage from an undercollateralized pool.
After studying the above models, we can see:
Staking in Filecoin is important to bridge the supply and demand for FIL in the ecosystem. The FVM has recently been released allowing for a lending marketplace to exist. Although the problem is real, the FVM release was probably too late for most FIL staking/lending protocols as the pie (mining rewards) is decreasing over time making it a niche market.
However, a few fascinating use cases can emerge on top of these staking protocols. With the introduction of stablecoins, the rewards can be taken as cash forwards. Something similar to what Alkimiya is building on Ethereum. This can result in the injection of new capital into the Filecoin ecosystem and also increase the TVL in these protocols.
Ethereum’s and Filecoin’s tech is different, their miners are different, their developers are different, their apps are different, and hence their communities. And for staking in particular, with every miner being “non-fungible” bootstrapping the demand side becomes a BD exercise and the success of it is directly proportional to the protocol’s reputation in the community.
Filecoin staking is a critical solution that needs to be built to get more SPs in the system, for retail to put their capital to work, create greater economic incentives as an ecosystem to attract more developers, and build useful products to build a positive flywheel. To know more beyond staking in the Filecoin ecosystem and the criticality of the FVM you can read this previous piece we published.
There are many more open problems to be solved in the Filecoin ecosystem, but we are positive that the Filecoin Ecosystem is working in the right direction to achieve its vision of storing humanity’s data in an efficient system.
Editor’s Note: This article draws heavily from David Aronchick’s presentation at the Filecoin Unleashed Paris 2023. David is the CEO of Expanso and former head of Compute-over-data at Protocol Labs which is responsible for the launch of the Bacalhau project. This blog post represents the independent view of the creator of the original content, who has given permission for this re-publication.
The world will store more than 175 zettabytes of data by 2025, according to IDC. That’s a lot of data, precisely 175 trillion 1GB USB sticks. Most of this data will be generated between 2020 and 2025, with an estimated compound annual growth of 61%.
The rapidly growing data sphere broadly poses two major challenges today:
Moving data is slow and expensive. If you attempted to download 175 zettabytes at current bandwidth, it would take you roughly 1.8 billion years.
Compliance is hard. There are hundreds of data-related governances worldwide which makes compliance across jurisdictions an impossible task.
The combined result of poor network growth and regulatory constraints is that nearly 68% of enterprise data is unused. That’s precisely why moving compute resources to where the data is stored (broadly referred to as compute-over-data) rather than moving data to the place of computation becomes all the more important, something which compute-over-data (CoD) platforms like Bacalhau are working on.
In the upcoming sections, we will briefly cover:
How organizations are currently handling data today
Propose alternative solutions based on compute-over-data
There are three main ways in which organizations are navigating the challenges of data processing today — none of which are ideal.
Using Centralized Systems
The most common approach is to lean on centralized systems for large-scale data processing. We often see enterprises use a combination of compute frameworks — Adobe Spark, Hadoop, Databricks, Kubernetes, Kafka, Ray, and more — forming a network of clustered systems that are attached to a centralized API server. However, such systems fall short of effectively addressing network irregularities and other regulatory concerns around data mobility.
This is partly responsible for companies coughing up billions of dollars in governance fines and penalties for data breaches.
Building It Themselves
An alternative approach is for developers to build custom orchestration systems that possess the awareness and robustness the organizations need. This is a novel approach but such systems are often exposed to risks of failure by an over-reliance on a few individuals to maintain and run the system.
Doing Nothing
Surprisingly, more often than not, organizations do nothing with their data. A single city, for example, may collect several petabytes of data from CCTV recordings a day and only view them on local machines. The city does not archive or process these recordings because of the enormous costs involved.
Building Truly Decentralized Compute
There are 2 main solutions to the data processing pain points.
Solution 1: Build on top of open-source compute-over-data platforms.
Solution 1: Open Source Compute Over Data Platforms
Instead of using a custom orchestration system as specified earlier, developers can use an open-source decentralized data platform for computation. Because it is open source and extensible, companies can build just the components they need. This setup caters to multi-cloud, multi-compute, non-data-center scenarios with the ability to navigate complex regulatory landscapes. Importantly, access to open-source communities makes the system less vulnerable to breakdowns as maintenance is no longer dependent on one or a few developers.
Solution 2: Build on top of decentralized data protocols.
With the help of advanced computational projects like Bacalhau and Lilypad, developers can go a step further and build systems not just on top of open-source data platforms as mentioned in Solution 1, but on truly decentralized data protocols like the Filecoin network.
Solution 2: Decentralized Compute Over Data Protocols
What this means is that organizations can leverage decentralized protocols that understand how to orchestrate and describe user problems in a much more granular way and thereby unlock a universe of compute right next to where data is generated and stored. This switchover from data centers to decentralized protocols can be carried out ideally with very few changes to the data scientists’ experience.
Decentralization is About Maximizing Choices
By deploying on decentralized protocols like the Filecoin network, the vision is that clients can access hundreds (or thousands) of machines spread across geographies on the same network, following the same protocol rules as the rest. This essentially unlocks a sea of options for data scientists as they can request the network to:
Select a dataset from anywhere in the world
Comply with any governance structures, be it HIPAA, GDPR, or FISMA.
The concept of maximizing choices brings us to what’s called “Juan’s triangle,” a term coined after Protocol Labs’ founder Juan Benet for his explanation of why different use cases will have (in the future) different decentralized compute networks backing them.
Juan’s triangle explains that compute networks often have to trade off between 3 things: privacy, verifiability, and performance. The traditional one-size-fits-all approach for every use case is hard to apply. Rather, the modular nature of decentralized protocols enables different decentralized networks (or sub-networks) that fulfill different user requirements — be it privacy, verifiability, or performance. Eventually, it is up to us to optimize for what we think is important. Many service providers across the spectrum (shown in boxes within the triangle) fill these gaps and make decentralized compute a reality.
In summary, data processing is a complex problem that begs out-of-the-box solutions. Utilizing open-source compute-over-data platforms as an alternative to traditional centralized systems is a good first step. Ultimately, deploying on decentralized protocols like the Filecoin network unlocks a universe of compute with the freedom to plug and play computational resources based on individual user requirements, something that is crucial in the age of Big Data and AI.
Follow the CoD working group for all the latest updates on decentralized compute platforms. To learn more about recent developments in the Filecoin ecosystem, tune into our blog and follow us on social media at TL;DR, Bacalhau, Lilypad, Expanso, and COD WG.
This blog post is contributed to Filecoin TL;DR by a guest writer. Catrina is an Investment Partner at Portal Ventures.
Until recently, startups led the way in technological innovation due to their speed, agility, entrepreneurial culture, and freedom from organizational inertia. However, this is no longer the case in the rapidly growing era of AI. So far, big tech incumbents like Microsoft-owned OpenAI, Nvidia, Google, and even Meta have dominated breakthrough AI products.
What happened? Why are the “Goliaths” winning over the “Davids” this time around? Startups can write great code, but they are often too hindered to compete with big tech incumbents due to several challenges:
Compute costs remain prohibitively high
AI has a reverse salient problem: a lack of necessary guardrails impedes innovation due to fear and uncertainty around societal ramifications
AI is a black box
The data “moat” of scaled players (big tech) creates a barrier to entry for emerging competitors
So, what does this have to do with blockchain technology, and where does it intersect with AI? While not a silver bullet, DePIN (Decentralized Physical Infrastructure Networks) in Web3 unlocks new possibilities for solving the aforementioned challenges. In this blog post, I will explain how AI can be enhanced with the technologies behind DePIN across four dimensions:
Reduction of infrastructure costs
Verification of creatorship and humanity
Infusion of Democracy & Transparency in AI
Installation of incentives for data contribution
In the context of this article,
“web3” is defined as the next generation of the internet where blockchain technology is an integral part, along with other existing technologies
“blockchain” refers to the decentralized and distributed ledger technology
“crypto” refers to the use of tokens as a mechanism for incentivizing and decentralizing
Reduction of infra cost (compute and storage)
Every wave of technological innovation has been unleashed by something costly becoming cheap enough to waste
The importance of infra affordability (in AI’s case, the hardware costs to compute, deliver, and store data) is highlighted by Carlota Perez’s Technological Revolution framework, which proposed that every technological breakthrough comes with two phases:
The Installation stage is characterized by heavy VC investments, infrastructure setup, and a “push” go-to-market (GTM) approach, as customers are unclear on the value proposition of the new technology.
The Deployment stage is characterized by a proliferation of infrastructure supply that lowers the barrier for new entrants and a “pull” GTM approach, implying a strong product-market fit from customers’ hunger for more yet-to-be-built products.
With definitive evidence of ChatGPT’s product-market fit and massive customer demand, one might think that AI has entered its deployment phase. However, there is still one piece missingstill: an excess supply of infrastructure that makes it cheap enough for price-sensitive startups to build on and experiment with.
Problem
The current market dynamic in the physical infrastructure space is largely a vertically integrated oligopoly, with companies such as AWS, GCP, Azure, Nvidia, Cloudflare, and Akamai enjoying high margins. For example, AWS has an estimated 61% gross margin on commoditized computing hardware.
Compute costs are prohibitively high for new entrants in AI, especially in LLM.
Version two of Bloom will likely cost $10M to train & retrain
If ChatGPT were deployed into Google Search, it would result in $36B reduction in operating income for Google, a massive transfer of profitability from the software platform (Google) to the hardware provider (Nvidia)
DePIN networks such as Filecoin (the pioneer of DePIN since 2014 focused on amassing internet-scale hardware for decentralized data storage), Bacalhau, Gensyn.ai, Render Network, and ExaBits (the coordination layers to match the demand for CPU/GPU with supply) can deliver 75% — 90%+ cost savings in infra costs via below three levers
1. Pushing up the supply curveto create a more competitive marketplace
DePIN democratizes access for hardware suppliers to become service providers. It introduces competition to these incumbents by creating a marketplace for anyone to join the network as a “miner,” contributing their CPU/GPU or storage power in exchange for financial rewards.
While companies like AWS undoubtedly enjoy a 17-year head start in UI, operational excellence, and vertical integration, DePIN unlocks a new customer segment that was previously out-priced by centralized providers. Similar to how eBay does not compete directly with Bloomingdale but rather introduces more affordable alternatives to meet similar demand, DePIN networks do not replace centralized providers but rather aim to serve a more price-sensitive segment of users.
2. Balancing the economy of these markets with crypto-economic design
DePIN creates a subsidizing mechanism to bootstrap hardware providers’ participation in the network, thus lowering the costs to end users. To understand how let’s first compare the costs & revenue of storage providers in web2 vs. web3 using AWS and Filecoin.
Lower fees for clients: DePIN networks create competitive marketplaces that introduce Bertrand-style competition resulting in lower fees for clients. In contrast, AWS EC2 needs a mid-50% margin and 31% overall margin to sustain operations, plus
Token incentives/block rewards are emitted from DePIN networks as a new revenue source. In the context of Filecoin, hosting more real data translates to earning more block rewards (tokens) for storage providers. Consequently, storage providers are motivated to attract more clients and win more deals to maximize revenue. The token structures of several emerging compute DePIN networks are still under wraps, but will likely follow a similar pattern. Examples of such networks include:
Bacalhau: a coordination layer to bring computing to where data is stored without moving massive amounts of data
exaBITS: a decentralized computing network for AI and computationally intensive applications
Gensyn.ai: a compute protocol for deep learning models
3. Reducing overhead costs
Benefits of DePIN networks like Bacalhau and exaBITS, and IPFS/content-addressed storage include:
Creating usability from latent data: there is a significant amount of untapped data due to the high bandwidth costs of transferring large datasets. For instance, sports stadiums generate vast amounts of event data that is currently unused. DePIN projects unlock the usability of such latent data by processing data on-site and only transmitting meaningful output.
Reducing OPEX costs such as data input, transport, and import/export by ingesting data locally.
Minimizing manual processes to share sensitive data: for example, if hospitals A and B need to combine respective sensitive patient data for analysis, they can use Bacalhau to coordinate GPU power to directly process sensitive data on-premise instead of going through the cumbersome administrative process to handle PII (Personal Identifiable Information) exchange with counterparties.
Removing the need to recompute foundational datasets: IPFS/content-addressed storage has built-in properties that deduplicate, trace lineage, and verify data. Here’s a further read on the functional and cost efficiencies brought about by IPFS.
Summary by AI: AI needs DePIN for affordable infrastructure, which is currently dominated by vertically integrated oligopolies. DePIN networks like Filecoin, Bacalhau, Render Network, and ExaBits can deliver cost savings of 75%-90%+ by democratizing access to hardware suppliers and introducing competition, balancing the economy of markets with cryptoeconomic design, and reducing overhead costs.
Verification of Creatorship & Humanity
Problem
According to a recent poll, 50% of A.I. scientists agree that there is at least a 10% chance of A.I. leading to the destruction of the human race.
This is a sobering thought. A.I. has already caused societal chaos for which we currently lack regulatory or technological guardrails — the so-called “reverse salient.”
To get a taste of what this means, check out this Twitter clip featuring podcaster Joe Rogan debating the movie Ratatouille with conservative commentator Ben Shapiro in an AI-generated video.
Unfortunately, the societal ramifications of AI go much deeper than just fake podcast debates & images:
The 2024 presidential election cycle will be among the first where a deep fake AI-generated political campaign becomes indistinguishable from the real one
The voice clone of Biden criticizing transgender women
A group of artists filed a class-action lawsuit against Midjourney and Stability AI for unauthorized use of artists’ work to train AI imagery that infringed on those artists’ trademarks & threatened their livelihood
A deepfake AI-generated soundtrack, “Heart on My Sleeve” featuring The Weeknd and Drake, went viral before being taken down by the streaming service. Such controversy around copyright violation is a harbinger of the complications that can arise when a new technology enters the mainstream consciousness before the necessary rules are in place. In other words, it is a Reverse Salient problem.
What if we can do better in web3 by putting some guardrails on AI?
Solution
Proof of Humanity and Creatorship with cryptographic proof of origination on-chain
This is where we can actually use Blockchain for its technology — as a distributed ledger of immutable records that contain tamper-proof history on-chain. This makes it possible to verify the authenticity of digital content by checking its cryptographic proof.
Proof of Creatorship & Humanity with Digital Signature
To prevent deep fakes, cryptographic proof can be generated using a digital signature that is unique to the original creator of the content. This signature can be created using a private key, which is only known to the creator, and can be verified using a public key that is available to everyone. By attaching this signature to the content, it becomes possible to prove that the content was created by the original creator — whether they are human or AI — and authorized/unauthorized changes to this content.
Proof of Authenticity with IPFS & Merkle Tree
IPFS is a decentralized protocol that uses content addressing and Merkle trees to reference large datasets. To prove changes to a file’s content, a Merkle proof is generated, which is a list of hashes that shows a specific data chunk in the Merkle tree. With every change, a new hash is generated and updated in the Merkle tree, providing proof of file modification.
A pushback against such a cryptographic solution may be incentive alignment: after all, catching a deep fake generator doesn’t generate as much financial gain as it reduces the negative societal externality. The responsibility will likely fall on major media distribution platforms like Twitter, Meta, Google, etc. to flag, which they are already doing. So why do we need Blockchain for this?
The answer is that these cryptographic signatures and proof of authenticity are much more effective, verifiable, and deterministic. Today, the process to detect deep fakes is largely through machine learning algorithms (such as the “Deepfake Detection Challenge”of Meta, “Asymmetric Numeral Systems” (ANS) of Google, and c2pa) to recognize patterns and anomalies in visual content, which is not only inaccurate at times but also falling behind the increasingly sophisticated deep fakes. Often, human reviewer intervention is required to assess authenticity, which is not only inefficient but also costly.
Imagine a world where each piece of content has its cryptographic signature so that everyone will be able to verifiably prove the origin of creation and flag manipulation or falsification — a brave new one.
Summary by AI: AI poses a significant threat to society, with deep fakes and unauthorized use of content being major concerns. Web3 technologies, such as Proof of Creatorship with Digital Signature and Proof of Authenticity with IPFS and Merkle Tree, can provide guardrails for AI by verifying the authenticity of digital content and preventing unauthorized changes.
Infusion of Democracy in AI
Problem
Today, AI is a black box comprised of proprietary data + proprietary algorithms. Such closed-door nature of Big Tech’s LLM precludes the possibility of what I call an “AI Democracy,” where every developer or even user should be able to contribute both algorithms and data to an LLM model, and in term receive a fraction of the future profits from the model (as discussed here).
AI Democracy = visibility(the ability to see the data & algorithm input into the model)
contribution(the ability to contribute data or algorithm to the model).
Solution
AI Democracy aims to make generative AI models accessible for, relevant to, and owned by everyone. The below table is a comparison illustrating what is possible today vs. What will be possible, enabled by blockchain technology in Web3.
Today:
For consumers:
One-way recipient of the LLM output
Little control over the use of their personal data
For developers:
Little composability possible
Little reproducibility because there’s no traceability of the ETL performed on the data
Single-source data contribution within the confine of the owner organization
Close sourced only accessible through API for a charge
80% of data scientists’ time is wasted on performing low-level data cleansing work because of the lack of verifiability to share data output
What blockchain will enable
For consumers:
Users can provide feedback (e.g. on bias, content moderation, granular feedback on output) as input into continuous fine-tuning
Users can opt to contribute their data for potential profits from model monetization
For developers:
Decentralized data curation layer: crowdsource tedious & time-consuming data preparation processes such as data labeling
Visibility & ability to compose & fine-tune algorithms with verifiable & built-on lineage (meaning they can see a tamper-proof history of all changes in the past)
The sovereignty of both data (enabled by content-addressing/IPFS) and algorithm(e.g. Urbitenables peer-to-peer composability and portability of data & algorithm)
Accelerated innovation in LLM from the outpour of variants from the base open-source models
Reproducibility of training data output via Blockchain’s immutable record of past ETL operations & queries (e.g. Kamu)
One might argue that there’s a middle ground of Web2 open source platforms, but it’s still far from optimal for reasons discussed in this blog post by exaBITS.
Summary by AI: The closed-door nature of Big Tech’s LLM precludes the possibility of an “AI Democracy,” where every developer or user should be able to contribute both algorithms and data to an LLM model, and in turn receive a fraction of the future profits from the model. AI should be accessible for, relevant to, and owned by everyone. Blockchain networks will enable users to provide feedback, contribute data for potential profits from model monetization, and enable developers to have visibility and the ability to compose and fine-tune algorithms with verifiability and built-on lineage. The sovereignty of both data and algorithm will be enabled by web3 innovations such as content-addressing/IPFS and Urbit. Reproducibility of training data output via Blockchain’s immutable record of past ETL operations and queries will also be possible.
Installation of Incentives for Data Contribution
Problem
Today, the most valuable consumer data is proprietary to big tech platforms as an integral business moat. The tech giants have little incentive to ever share that data with outside parties.
What about getting such data directly from data originators/users? Why can’t we make data a public good by contributing our data and open-source it for talented data scientists to use?
Simply put, there’s no incentive or coordination mechanism for that. The tasks of maintaining data and performing ETL (extract, transform & load) incur significant overhead costs. In fact, data storage alone will become a $777 billion industry by 2030, not even counting computing costs. Why would someone take on the data plumbing work and costs for nothing in return?
Case in point, OpenAI started off as open-source and non-profit but struggled with monetization to cover its costs. Eventually, in 2019, it had to take the capital injection from Microsoft and close off its algorithm from the public. In 2024, OpenAI is expected to generate $1 billion in revenue.
Solution
Web3 introduces a new mechanism called dataDAO that facilitates the redistribution of revenue from the AI model owners to data contributors, creating an incentive layer for crowd-sourced data contribution. Due to length constraints, I won’t elaborate further, but below are two related pieces.
In conclusion, DePIN is an exciting new category that offers an alternative fuel in hardware to power today’s renaissance of innovations in web3 and AI. Although big tech companies have dominated the AI industry, there is potential for emerging players to compete by leveraging blockchain technologies: DePIN networks lower the barrier to entry in compute costs; blockchain’s verifiable & decentralized properties make true open IA possible; innovative mechanisms, such as dataDAOs, incentivize data contribution; and the immutable and tamper-proof property of Blockchain provides proof of creatorship to address concerns regarding the negative societal impact of AI.
Editor’s Note: This blogpost is a repost of the original content published on 7 June 2023, by Luffistotle from Zee Prime Capital. Zee Prime Capital is a VC firm investing in programmable assets and early-stage founders globally. They call themselves a totally supercool and chilled VC (we tend to agree) investing in programmable assets, collaborative intelligence and other buzzwords. Luffistotle is an Investor at Zee Prime Capital. This blogpost represents the independent view of the author, who has given permission for this re-publication.
Table of Contents
History of P2P
Decentralized Storage Network Landscape
FVM
Permanent Storage
Web 3’s First Commercial Market
Consequences of Composability
Storage is a critical part of any computing stack. Without this fundamental element, nothing is possible. Through the continued advancement of computational resources, a great deal of excess and underutilized storage has been created. Distributed Storage Networks (DSNs) offer a way to coordinate and utilize these latent resources and turn them into productive assets. These networks have the potential to bring the first real commerce vertical into Web 3 ecosystems.
History of P2P
The history of real Peer-to-peer file sharing began to hit the mainstream with the advent of Napster. While there were early methods of sharing files on the internet before this, the mainstream finally joined with the sharing of MP3 files that Napster brought. From this initial starting point, the distributed systems world exploded with activity. The centralization within Napster’s model (for indexing) made it easy to shut down given its legal transgressions, however, it laid the foundation for more robust methods of file sharing.
The Gnutella Protocol followed this trailblazing and had many different effective front-ends leveraging the network in different ways. As a more decentralized version of the napstereqsue query network, it was much more robust to censorship. Even in its day, it experienced censorship. AOL had acquired the developing company Nullsoft, and quickly realized the potential, shutting distribution down almost immediately. However, it had already made it outside and was quickly reverse-engineered. Bearshare, Limewire, and Frostwire are likely the most notable of these front-end applications you may have encountered. Where it ultimately failed was the bandwidth requirements (a deeply limited resource at the time) combined with the lack of liveness and content guarantees.
Remember this? If not do not worry, it has been reborn as an NFT marketplace…
What came next was Bittorrent. This presented a level-up due to the two-sided nature of the protocol and its ability to maintain Distributed Hash Tables (DHTs). DHTs are important because they serve as a decentralized version of a ledger that stores the locations of files and is available for lookup by other participating nodes in the network.
After the advent of Bitcoin and blockchains, people started thinking big about how this novel coordination mechanism could be used to tie together networks of latent unused resources and commodities. What followed soon after was the development of DSNs.
Something that would perhaps surprise many people, is that the history of tokens and P2P networks goes back much farther than the existence of bitcoin and blockchains. What pioneers of these networks realized very quickly was a couple of the following points:
Monetizing a useful protocol you have built is difficult as a result of forking. Even if you monetize a front end and serve ads or utilize other forms of monetization, a fork will likely undercut you.
Not all usage is created equal. In the case of Gnutella, 70% of users did not share files and 50% of requests were for files hosted by the top 1% of hosts.
Power laws.
How does one remedy these problems? For BitTorrent it is seeding ratios (download/upload ratio), for others, it was the introduction of primitive token systems. Most often called credits or points they were allocated to incentivize good behavior (that promotes the health of the protocol) and stewardship of the network (like regulating content in the form of trust ratings). For a deeper dive into the broader history of all of this, I highly recommend these (now deleted, available via web archive) articles by John Backus:
Interestingly a DSN was part of the original vision for Ethereum. The “holy trinity” as it was called was meant to provide the necessary suite of tools for the world computer to flourish. Legend has it, that it was Gavin Wood’s idea for the concept of Swarm as the storage layer for Ethereum with Whisper as the messaging layer.
Mainstream DSNs followed and the rest is history.
Decentralized Storage Network Landscape
The decentralized storage landscape is most interesting because of the huge disparity between the size of the leader (Filecoin) and the other more nascent storage networks. While many people think of the storage landscape as two giants of Filecoin and Arweave, it would likely surprise most people that Arweave is the 4th largest by usage, behind Storj and Sia (although Sia seems to be declining in usage). And while we can readily question how legitimate the FIL data stored is, even if we handicapped it by say 90%, FIL usage is still ~400x Arweave.
What can we infer from this?
There is clear dominance in the market right now, but the continuity of this is dependent on the usefulness of these storage resources. The DSNs all roughly use the same architecture, node operators have a bunch of unused storage assets (hard drives), and they can pledge these to the network, mine blocks, and earn miner rewards for storing data. While the approaches to pricing and permanence may differ, the most important will be how easy and affordable retrieval and computation of the stored data is.
Fig 1. Storage Networks by Capacity and Usage
N.B:
Arweave Capacity is not directly measurable; instead, node operators are always incentivized to have sufficient buffer and to increase supply to meet demand. How big is the buffer? Given the immeasurability of it, we can not know.
Swarm’s actual network usage is impossible to tell, we can only look at how much storage has been paid for already. Whether it is used is unknown.
While this is the table of live projects, there are other DSNs in the works. These include ETH Storage, Maidsafe, and others.
FVM
Before going further it is probably worth noting that Filecoin has recently launched the Filecoin Ethereum Virtual Machine (FEVM). The FVM is a WASM VM that can support many different other runtimes on top via hypervisor. For instance, this recently launched FEVM is an Ethereum Virtual Machine runtime on top of the FVM/FIL network. The reason this is worth highlighting is that it facilitates the explosion of activity concerning smart contracts (i.e. stuff) on top of FIL. Before the March launch, there were 11 active smart contracts on FIL, following the FVM launch this has exploded. It benefits from composability in the form of leveraging all the work done in solidity to build out new businesses on top of FIL. This means innovations like quasi-liquid staking type primitives from teams like GLIF, and the various additional financialization of these markets you can build on top of such a platform. We believe this will accelerate storage providers because of the increases in capital efficiency (SPs need FIL to actively mine/seal storage deals). This differs from typical LSDs as there is an element of assessing the credit risk of the individual storage providers.
Permanent Storage
I believe Arweave gets the most airtime on this front, it has a flashy tagline that appeals to the deepest desires of Web 3 Participants:
Permanent Storage.
But what does this mean? It is an extremely desirable property, but in reality, execution is everything. Ultimately execution comes down to sustainability and cost for the end users. Arweave’s model is based on a pay-once, store forever (200 years upfront + deflation of storage value assumption) model. This kind of pricing model works well in a deflationary pricing environment of the underlying asset, as there is a constant goodwill accrual (i.e. old deals subsidize new deals) however the inverse is true in inflationary environments. History tells us this shouldn’t be an issue as the cost of computer storage has more or less been down only since inception but hard drive cost alone is not the whole picture.
Arweave creates permanent storage via the incentives of the Succinct Proof of Random Access (SPoRA) algorithm which incentivizes miners to store all the data and prove they can randomly produce a historical block. Doing so gives them a higher probability of being selected to create the next block (and earn the corresponding rewards).
While this model does a good job of getting node runners to want to store all of the data, it does not mean it is guaranteed to happen. Even if you set super high redundancy and use conservative heuristics to decide the parameters of the model, you can never get rid of this underlying risk of loss.
Source: Twitter
Fundamentally the only way to truly execute permanent storage would be to deterministically force somebody (everybody?) to and throw them in the gulag when they screw up. How do you properly incentivize personal responsibility such that you can achieve this? There is nothing wrong with the heuristic approach, but we need to identify the optimal way to achieve and price permanent storage.
All of this is a long-winded way of getting to the point of asking what level of security we deem acceptable for permanent storage, and then we can think about that pricing over a given time frame. In reality, consumer preferences will fall along the spectrum of replication (permanence), and thus they should be able to decide what this level is and receive the corresponding pricing.
In traditional investing literature and research, there is infamous knowledge about how the benefits of diversification work on the overall risk of a portfolio. While adding stocks initially brings risk reduction to your portfolio, very quickly the diversification benefits of adding stock become more or less not valuable.
I believe the pricing of storage over and above some default standard of replication on the DSN should follow a similar curve but for cost and security of the storage with an increasing amount of replication.
For the future, I am most excited about what more DSNs with easily accessible smart contracting can bring to the market for permanent storage. I think overall consumers will benefit the most from this as the market opens up this spectrum of permanence.
For instance, in the chart above we can think of the area in green as the area of experimentation. It may be possible to achieve exponential decreases in the cost of that storage with minimal changes to the number of replications and level of permanence.
Additional ways of constructing permanence could come from replication across different storage networks rather than just within a single network. These kinds of routes are more ambitious but naturally lead to more differentiated levels of permanence. The biggest question here would be is there some kind of “permanence-free lunch” we could achieve by spreading it across DSNs in the same way we diversify market risk across a portfolio of publicly traded equities?
The answer could be yes, but it depends on node provider overlap and other complex factors. It could also be constructed via forms of insurance, possibly by node runners subjecting themselves to higher levels of slashing conditions in exchange for these assurances. Maintaining such a system would also be extremely complex as multiple codebases and coordination between them are required. Nonetheless, we look forward to this design scape expanding significantly and forwarding the general idea of permanent storage for our industry.
Web 3’s First Commercial Market
Matti tweeted recently about the promise of storage as the use case to bring Web 3 some real commerce. I believe this is likely.
I was having a conversation recently with a team from a layer one where I told them it is their moral imperative to fill their blockspace as stewards of the L1, but even more than this, it is to do this with economic activity. The industry often forgets the second part of its name.
The whole currency part.
Any protocol that launches a token that would not like to be down only is asking for some kind of economic activity to be conducted in that currency. For layer 1s it’s their native token, processing payments (executing computation) and charging a gas fee for doing so. The more economic activity happening, the more gas is used, and the more demand for their token. This is the crypto-economic model. For other protocols, it is likely some kind of middleware SaaS service.
What makes this model most interesting is when it is paired with some kind of commercial good, in the case of classical L1s it is computation. The problem with this is that as it pertains to something like financial transactions, having variable pricing on the execution is a horrible UX. The cost of execution should be the least important part of a financial transaction such as a swap.
What becomes difficult is filling this blockspace with economic activity in the face of this bad UX. While scaling solutions are on the way that will help stabilize this (I highly recommend this whitepaper on Interplanetary Consensus warning PDF), the flooded market of layer 1s makes it difficult to find enough activity for a given one.
This problem is much more addressable when you pair this computational capacity with some kind of additional commercial good. In the case of DSNs, this is storage. The economic activity of data being stored and the related elements such as financing and securitization of these storage providers is an immediate filler.
But this storage also needs to be a functional solution for traditional businesses to use. Particularly those who deal with regulations around how their data is stored. This most commonly comes in the form of auditing standards, geographical restrictions, and making the UX simple enough to use.
We’ve discussed Banyan before in our Middleware Thesis part 2, but their product is a fantastic step in the right direction on this front. Working with node operators in a DSN to secure SOC certifications for the storage being provided while offering a simple UX to facilitate the upload of your files.
But this alone is not enough.
The content stored also needs to be easily accessible with efficient retrieval markets. One thing we are very excited about at Zee Prime is the promise of creating a Content Distribution Network (CDN) on top of a DSN. A CDN is a tool to cache content close to the users and deliver improved latency when retrieving the content.
We believe this is the next critical component to making DSNs widely adaptable as this allows videos to load quickly (think building decentralized Netflix, Youtube, TikTok, etc.). One proxy to this space is our portfolio company Glitter, which focuses on indexing DSNs. This is important because it is a critical piece of infrastructure to improve the efficiency of retrieval markets and facilitate these more exciting use cases.
The potential for these kinds of products excites us as they have demonstrated PMF with high demand in Web 2. Despite this adoption, many face frictions that could benefit from leveraging the permissionless nature of Web 3 solutions.
Consequences of Composability
Interestingly, we think some of the best alpha on DSNs is hiding in plain sight. In these two pieces by Jnthnvctr he shares some great ideas on how these markets will evolve and the products that will come (on the Filecoin side):
One of the most interesting takeaways is the potential for pairing off-chain computation in addition to storage and on-chain computation. This is because of the natural computational needs of providing storage resources in the first place. This natural pairing can add commercial activity to flow through the DSN while opening up new use cases.
The launch of the FEVM makes many of these level-ups possible and will make the storage space much more interesting and competitive. For founders searching for new products to build, there is even a resource of all the products Protocol Labs is requesting people to build with potential grants available.
In Web 2 we learned that data has a kind of gravitational pull, where companies that collected/created a lot of it can reap the rewards and were accordingly incentivized to close it off in such a way to protect that.
If our dreams of user-controlled data solutions become mainstream, we can ask ourselves how the point where this value accrual happens changes. While users become primary beneficiaries, receiving cash flows in exchange for their data, no doubt monetization tools that unlock this potential also benefit, but where and how this data is stored and accessed also changes dramatically. Naturally, this kind of data can sit on DSNs which benefit from the usage of this data via robust query markets. This is a shift from exploitation toward flow.
What comes after could be extremely exciting.
When we think about the future of decentralized storage, it is fun to consider how it might interact with operating systems of the future like Urbit. For those unfamiliar, Urbit is a kind of personal server built with open-source software that allows you to participate in a peer-to-peer network. A true decentralized OS to do self-hosting and interact with the internet is a P2P way.
If the future plays out the way Urbit maximalists might hope, decentralized storage solutions undoubtedly become a critical piece of the individual stack. One can easily imagine hosting all their user-related data encrypted on one of the DSNs and coordinating actions via their Urbit OS. Further to this, we could expect further integrations with the rest of Web 3 and Urbit, especially with projects such as Uqbar Network, which brings smart contracting to your Nook environment.
These are the consequences of composability, the slow burn continues to build up exponentially until it delivers something really exciting. What feels like thumb twaddling becomes a revolution, an alternative path towards existing in a hyper-connected world. While Urbit might not be the end solution on this front (it has its criticisms), what it does show us is how these pieces can come together to open up a new river of exploration.
This blog post explains what Filecoin’s Virtual Machine (FVM) is, why it matters, and how one might evaluate and prioritize the opportunities it unlocks.
First, we will explain what the Filecoin Virtual Machine is and how Filecoin becoming programmable lays the foundation for composable products and services in the Filecoin economy.
Secondly, we introduce a framework to categorize the universe of potential FVM-powered use cases into distinct opportunity areas. This section discusses specific opportunities unlocked by the FVM and how venture investors, developers, storage providers and other stakeholders may evaluate and prioritize them.
In the third section, we explore how, by commoditizing cloud services and by allowing anyone to create and monetize products and services around data, the FVM stands to fully unleash and augment the full potential of a trillion dollar open data economy.
We conclude by discussing what has energized many hundreds of teams to start building on the FVM, and by providing information on how you can stay up to date on all things FVM.
1. The FVM brings user programmability to Filecoin creating a watershed moment for innovation
Filecoin’s larger roadmap aims to turn the services of the cloud into permissionless markets on which any provider can offer their services. The launch of smart contracts (also known as ‘actors’) on FVM on March 14 2023 is a critical component of this larger vision as FVM allows for user programmability around the key services of the Filecoin network: Large-scale Storage, Retrieval, and Compute over data.
What’s exciting about FVM is the ability for any developer¹ to deploy smart contracts on the network. One may compare this to the moment that phones became programmable: The ability to write and install apps significantly augmented what people could do with phones and allowed the devices to go far beyond the capabilities of their pre-installed, hard-coded software. It was a watershed moment for innovation.
Similar dynamics stand to unfold when Filecoin becomes programmable by anyone through FVM. Since Filecoin’s storage market is currently the primary service anchored into the Filecoin blockchain today, the first big unlock will likely be programming around the state of Filecoin’s storage deals. Specifically, anyone will be able to (within certain limits) write software on what, how, when and by/for whom data is stored via Filecoin, the world’s largest open access storage network.
The FVM is a state machine that allows users to program around the state of the Filecoin blockchain
While the FVM does not directly interact with the data stored on the Filecoin network (just its metadata!), it will enable automation of storage and related services (e.g. off-chain data indexers, oracles) and settlement of value. This automation unlocks many new use cases. Illustratively, find a few select opportunities (Perpetual Storage, DataDAOs, Filecoin staking) that arise from assembling the different building blocks that the FVM provides access to below.
The FVM enables the settlement of value as well as building smart contracts that can interact with the metadata of services anchoring into the Filecoin blockchain (e.g., storage)
These illustrative recipes for use cases can be endlessly re-combined with each other and other components (e.g., developer tooling, end-user interfaces etc.). Additionally, they may eventually also leverage other building blocks of the Filecoin economy which anchor into the same blockspace (e.g., retrieval of and computation on content-addressed data) as well as those of other economies (e.g., via cross-chain bridges or oracles). These combinations will result in the emergence of ever more sophisticated services.
2. How we see the use cases unlocked by the FVM
The use cases unlocked by the FVM are loosely grouped into the following opportunity areas:
Data onboarding & management: e.g., tools automating storage deal-making to unlock use cases like perpetual storage
Data curation & monetization: e.g., tools facilitating the collective creation, curation and monetization of valuable datasets
Decentralized finance: e.g., to provide access to collateral for the thousands of storage providers offering services on the network and to create new opportunities for token-holders to participate more actively in the Filecoin economy
Network participant discovery and analytics: e.g., storage provider reputation services or data retrievability oracles that create differentiation opportunities and may enhance the reliability of the decentralized cloud for its users
Integration, interoperability and other services: e.g., cross-chain bridges to integrate with other economies or NFT-standards with built-in storage guarantees, developer tooling and more
It is important to note that due to the recombinant nature of FVM-powered use cases and web3 in more broadly, businesses may cut across several of these opportunity areas.
The use cases unlocked by the FVM can be loosely grouped into five opportunity areas, each unlocking sizable markets
One of the unique advantages of FVM-powered services starting up in the Filecoin economy is access to a large number of storage providers seeking to boost their profitability. In February 2023, storage providers on the Filecoin network had collectively locked up 130M+ FIL in collateral to secure their commitments to keeping the network and their clients’ data safe.
Additionally, storage providers have collectively invested millions of dollars to stand up the data centers that provide many exabytes of capacity. Partly due to the absence of DeFi solutions, access to collateral and other financing is relatively difficult today.² As a result, services that lower these costs and reduce complexity for storage providers and/or unlock new revenue streams represent sizable addressable markets. This advantage is also a distinguishing dynamic that makes Filecoin a differentiated L1.
To lower cost, DeFi lending services may provide cheaper access to capital (which is required for collateralizing storage deals) by using storage provider reputation scores to improve underwriting or by using smart contracts to enforce repayment (e.g., by using future block rewards as collateral) directly to those lenders that made them possible. Such services³ also stand to benefit from being able to tap into the large number of token-holders — many of which are eager to participate in the Filecoin economy more actively.⁴ Furthermore, data on-boarding and management services may lower costs for storage providers by lowering storage client acquisition costs (e.g., via deal aggregators) and/or by reducing the overhead of being a Filecoin storage provider (e.g., by modularizing the operations).
FVM-powered services may also increase SP revenue by enabling data access or encryption solutions (e.g., Medusa, Fission, Lit or Lighthouse) which make Filecoin solutions viable for new customer segments, by giving SPs more opportunities to differentiate (e.g., via reputation or compliance-certification tools), increasing the duration of storage deals (potentially in perpetuity) and allocating Fil+ datacap more efficiently.
Cross-chain bridges and messaging to other (web3) ecosystems which facilitate the importing and exporting of services to and from the Filecoin economy also represent large opportunities for growth — both in utility for the Filecoin network (and thus in demand for Filecoin blockspace) and for increasing utility for web3 overall. In the near term, developers may also capitalize on opportunities around the tooling that makes building the services outlined above more feasible.
Collectively, these opportunities represent markets with hundreds of millions of dollars in revenue potential. Different considerations will inform how the stakeholders may prioritize the development of each opportunity area. Additionally, stakeholders may strategically sequence the development of different opportunity areas to maximize impact. The below framework provides an overview of potential dimensions that one may use to assess opportunities unlocked by the FVM.
Different considerations, such as the ones provided in this non-exhaustive list, will inform how stakeholders may prioritize and sequence the development of use cases in different opportunity areas
3. Empowering more people to create and capture value around data to unleash the full potential of an open data economy
Importantly, Web3 and Filecoin, and the FVM specifically, will continue to commoditize the services of the cloud and allow for better value attribution in the data economy. This section explains why this commoditization is needed and how it opens up access to the data economy and augments the ways in which value can be created, captured, and more equitably shared.
Let the data economy be defined broadly as covering businesses around data analytics and transformation (e.g., software for encryption, transcoding and more), data access and monetization (e.g., on-demand streaming services), the financial services facilitating transactions between market participants as well as the sale of hardware required to power these businesses.
Today, the core tenets underpinning this data economy (i.e., cloud storage and compute, content-delivery networks and more) are dominated by a few large companies. These organizations are successfully leveraging economies of scale to moat their businesses. The resulting dominance of a few large players has not only created central points of failure, but also stifled innovation and kept prices artificially high.
Web3, Filecoin, and the FVM stand to challenge these dominant players: The composability and power of crypto-economic incentives allowed the Filecoin community to rapidly bootstrap into existence an ever-expanding and competitively priced network of storage providers. Filecoin’s open access storage network is already the world’s largest of its kind, its capacity eclipsing even some publicly traded centralized storage providers. As Filecoin moves closer to its vision, infrastructure anchoring into the Filecoin network will also commoditize the services around content-delivery (e.g., via Filecoin Saturn) and compute over data (e.g., via Bacalhau).
Secondly, in today’s data economy value creation often stems from collectively generated datasets (think: users creating content for social networks and other signaling interest for that content), the capture of that value is largely privatized in today’s data economy. This is due to the fact that well-functioning mechanisms that would let data originators participate directly in the capture of value around datasets that they collectively create did not successfully emerge in web2. Instead, the most effective in monetizing collectively created datasets turned out to be advertising.
Web3 tech is, however, structurally better positioned to trace and retroactively reward contributors (even for data points with small marginal value) by using its decentralized ledgers. With the FVM, specifically, any number of unaffiliated parties could use the Filecoin token (or a FVM-powered L2 abstraction thereof) to form an incentivized collective around the creation, preservation and monetization of datasets (that otherwise may never emerge):
Imagine individuals monetizing their contributions to the training data of an AI model or to a social graph
Or researchers using the proceeds of selling access to a database of bacterial pathogens (which may be used to inform antibiotic diagnostics or improve drug discovery) to finance the continued curation and maintenance of said database
Or an ever-expanding encyclopedia rewarding its most active contributors directly as opposed to letting the value flow through an intermediary foundation
As projects like these emerge, the ability to capture value will likely depend to an ever greater degree on having access to proprietary datasets. Additionally, the open nature and the composability of such services also allows users to preserve their agency to exit, remain loyalto, or voice their concerns about data-centric services. This agency preservation will force institutions to think about dataset privacy and sharing in more sophisticated ways than “just trust us”. It may also result in allowing users that own their data to keep a (larger) share.
In summary, the trends around commoditization and better value attribution fueled by FVM and Filecoin will not only lead to fiercer competition and more pressure to innovate across all sectors of the data economy, but also solidify Filecoin’s position as the Layer-1 blockchain uniquely poised to power this open data economy.
Conclusion: FVM creates fertile ground for accelerated growth of the Filecoin ecosystem
FVM stands to unlock the development of applications, markets and organizations that will eclipse the scale and breadth of services offered by centralized cloud providers.
This potential has energized the community tremendously: Weeks before the official launch of the FVM, there are hundreds of teams building with the FVM on the testnet. Additionally, FVM-specific hackathons (e.g., Spacewarp) leading up to the launch of the FVM saw the highest registration numbers for a Filecoin-exclusive hackathon ever.
The Filecoin community continues to foster a radically recombinant ecosystem that accelerates the best ideas. FVM is highly cross-compatible thus catalyzing the adoption of Web3 technologies alongside and in partnership with other ecosystems and L1 blockchains.
Similar to how a computer may support multiple operating systems, Filecoin’s Virtual Machine will support multiple runtimes. The first runtime to launch will be the Filecoin Ethereum Virtual Machine (FEVM). This eases the ramp-up for EVM developers who can leverage tried and tested developer tooling infrastructure and port over existing EVM-based smart contracts.
These all are compelling reasons to build with the FVM. If you are interested in following along on what teams are building with the FVM, check out this non-exhaustive list. Also, review the Space Warp initiative to learn more about the program leading up to the launch of Filecoin’s Virtual Machine, including FVM-specific hackathons, grants, community leaderboards and acceleration programs. To familiarize with the technical details around the FVM consider visiting fvm.filecoin.io or watching oneofthemany videos introducing the technology.
Disclaimer: Personal views and not reflective of my employer nor should be treated as “official”. This information is intended to be used for informational purposes only. It is not investment advice. Although we try to ensure all information is accurate and up to date, occasionally unintended errors and misprints may occur.
[1]: Before March 14, the Filecoin Virtual Machine powered only so-called ‘native actors’. These built-in actors powered Filecoin’s core logic (e.g., computing and posting the proofs necessary to on-board and continuously verify storage onto the network) thus enabling storage deals and enforcing good behavior by the storage providers. Amending the functionality of these native actors requires the involvement of many stakeholders in the Filecoin community via the Filecoin Improvement Proposal (FIP) process. The complexity of this process limited the freedom to experiment, develop and deploy new functionalities on the Filecoin network.
[2]: The absence of better opportunities to more optimally allocate FIL in the Filecoin economy, may explain why the locking rate of Filecoin (38%) is lower than that of many other Layer-1 blockchains (often >60%)
As we’ve written about previously, Filecoin is building an economy of open data services. While today, Filecoin’s economy is primarily oriented around storage services, as other services (retrieval, compute) come online, the utility of the Filecoin network will compound as they all anchor in and can be triggeredfrom the same block space.
The Filecoin Virtual Machine (FVM) allows us to compose these services together, along with other on-chain services (e.g. financial services), to create more sophisticated offerings. This is similar to how the composability in Defi enables the construction of key financial markets services in a permissionless manner (e.g. auto investment capabilities (Yearn) which builds on liquidity pools like Curve and lending protocols like Compound). The FVM is an important milestone for Filecoin, as it allows anyone to build protocols to improve the Filecoin network and build valuable services for other participants. Smart contracts on Filecoin are unique in that they pair web3 offerings with real world services like storage and compute, provided by an open market.
In this blogpost, we’ll unpack a sample use case and its supporting components for the FVM, how these services might compose together, and the potential business opportunities behind them. One of the neat artifacts of what the FVM enables is for modularity between solutions, meaning components built for one protocol can be reused for others. While designing these solutions, hopefully builders (potentially you!) keep this in mind to maximize the customer set.
This is only a subset of the opportunities that the broader Filecoin community has put forward here, but the aim is to show how these services might intertwine and how the Filecoin economy might evolve.
Note: Over time, it’s likely that a number of these services will migrate to subnets via Interplanetary Consensus — but for this blogpost we want to paint a more detailed picture of what the Filecoin economy might look like early on.
The rest of the blog is laid out as follows:
Motivating Use Case – Perpetual Storage
Managing Flows of Data – Aggregator / Caching Nodes – Trustless Notaries – Retrievability Oracles
Perpetual storage is a useful jumping point — as it motivates a number of the other services (both infrastructure and economic) in the network. Permanent storage (which we’ve argued previously is a subset of perpetual storage) is a market valued at ~$300 million.
The basic goal of perpetual storage is straightforward: enable users to specify terms for how their datasets should be stored (e.g. ensure there are always at least 10 copies of this data on the network) — without having to run additional infrastructure to manage repair or renewal of deals. As long as the funds exist to pay for storage services, the perpetual storage protocol should automatically incentivize the repair and restoration of any under-replicated dataset to meet the specified terms.
This tweet thread shares a mental model for how one might create and fund such a contract. In the simplest form, you can boil down a perpetual storage contract to a minimum set of requirements <cid, number of copies, USDC, FIL, rules for an auction>, and the primitives to verify proper execution. Filecoin’s proofs are critical — as they can tell us when data is under-replicated and allow us to trigger auctions to bring replication back to a minimum threshold.
In order to build the above, a number of services are required. While one protocol could try and solve for all the services required in a monolithic architecture, modular solutions would allow for re-use in other protocols. Below we’ll cover some of the middleware services that might exist to help enable the full end-to-end flow.
Managing the Flow of Data
A sample flow for how data may move across the Filecoin economy.
Aggregator / Caching Nodes
In our perpetual storage protocol, the client specifies some data that should be replicated. This leads to an interesting UX question — in many cases, users don’t want to have to wait for storage proofs to land on-chain to know the data will be stored and replicated. Instead, users might prefer to have their data persisted by an incentivized actor with guarantees that all other services will occur, similar to the role that data on-ramps play (like Estuary and NFT.Storage).
Note: One of the nice things about content addressing is that relying on incentivized actors is totally optional! Users wait for their data to land on-chain themselves if they’d like — or send their data to an incentivized network (as described here) that manages this onboarding process for them.
One solution to this UX question might be to design a protocol for an incentivized IPFS nodes operating with weaker storage guarantees to act as incentivized caches. These nodes might lock some collateral (to ensure good behavior, enact penalties if services are not rendered properly), and when data is submitted return a commitment to store the data Filecoin according to the specified requirements of the client. This commitment might include a merkle proof (showing the client’s data was included inside of a larger set of data that might be stored in aggregate), a max block height by which the deal would start, etc.
Revenue Model:One neat feature of this design for aggregator services is they can take small microtransactions on service on both sides — a small fee from clients (pricing the temporary storage costs, compute for aggregation, bandwidth costs, etc), and potentially an onboarding bounty from an auction protocol (an example described in the Trustless Notaries section below).
Trustless Notaries (Auction Protocols)
To actually make the deal on Filecoin, we might want to automate the process of using Filecoin Plus. Filecoin has two types of storage deals — verified deals and unverified deals. Verified deals refer to storage deals done via the Filecoin Plus program, and are advantageous for data clients as it leverages Filecoin’s network incentives to help reduce the cost of storage.
Today, Filecoin Plus uses DataCap (allocated by Notaries) to help imbue individual clients with the ability to store fixed amounts of data on the network. Notaries help add a layer of social trust to publicly verify that clients are authentic and prevent sybils from malicious actors. This works when clients are human — but it leaves an open question on how one can verify non-human (e.g. smart contract!) actors.
One solution would be to design a trustless notary. A trustless notary is a smart contract, where it would be economically irrational to attempt to sybil the deal-making process.
A basic flow of how a trustless notary interact with clients and storage providers.
What might this look like? A trustless notary might be an on-chain auction, where all participants (clients, storage providers) are required to lock some collateral (proportional to the onboarding rate) to participate. When the auction is run, storage providers can submit valid bids (even negative ones!) accommodating the requirements of the client. By running an auction via a smart contract — everyone can verify that the winning bidder(s) came from a transparent process. Economic collateral (both from the clients and storage providers) can be used to disincentivize malicious actors and ensure closed auctions result in on-chain deals. The auction process might also allow for more sophisticated negotiations between a prospective client and storage provider — not just on the terms of the deal, but on the structure of the payment as well. A client looking to control costs might offer a payment in fiat (to cover a storage provider’s opex) along with a loan in Filecoin (and in return expect a large share of the resulting block rewards).
Revenue Model: For running the auction, the notary maintainer might collect some portion of fees for the deal clearing, collect a fee on locked collateral (e.g. if staked FIL is used as the collateral some slice of the yield), or some combination of both. One nice artifact about running a transparent auction is it can also allow for negative prices for storage (which can be used to fund an insurance fund for datasets, bounties for teams that help onboard new clients, distributed to tokenholders who participate in governance of the trustless notary, etc).
Note: Trustless notaries (if designed correctly) have a distinct advantage of being permissionless — where they can support any number of use cases that might not want humans in the loop (e.g. ETL pipelines that want to automatically store derivative datasets). Today, 393 PiB of data have been stored via verified deals.
In our perpetual storage use case, we’d likely want to be able to leverage the trustless notary to trigger the deal renewals and auctions any time a dataset is under replicated. On the first iteration, this means that storage providers might grab the data out of the caching nodes and on subsequent iterations from other storage providers who have copies of the data.
Retrievability Oracles
For both the deals struck by the trustless notaries, as well as for the caching done by the aggregators — we need to ensure data is properly transferred and protect clients against price gouging. One solution to this problem are retrievability oracles.
Retrievability oracles are consortiums that allow a storage provider to commit to a maximum retrieval price for the data stored. The basic mechanism is as follows:
When striking a deal with a client, a storage provider additionally can commit to retrieval terms.
In doing so, the storage provider locks collateral with the retrievability oracle along with relevant commitment (e.g. max price to charge per GiB for some duration).
In normal operation, the client and the storage provider continue to store and retrieve data as normal.
In the event the storage provider refuses to serve data (against whatever terms previously agreed), the client can appeal to the retrievability oracle who can request the data from the storage provider. → If the storage provider serves the data to the oracle, the data is forwarded to the client. → If the storage provider doesn’t serve the data, the storage provider is slashed.
Revenue Model: For running the retrieval oracles, the consortium may collect fees (either from storage providers for using the service, fees for accepting different forms of collateral, yield from staked collateral, or perhaps upon retrieval of data on behalf of the client).
By including a retrievability oracle in this loop, we can ensure incentives exist to proper transfer of data at the relevant points of the lifecycle of our perpetual storage protocol.
Building the Economic Loop
With all of the above, we’ve effectively created incentivized versions of the relevant components for the dataflows. Now with this out of the way, it’s worthwhile to focus on the economic flows and how we can ensure that our perpetual storage protocol can fully fund the operations above.
A sample view on the economic flows for enabling perpetual storage. Note other DeFi primitives might help mitigate risk and volatility (e.g. options, perpetuals)
Aside from the initial onboarding costs, the remainder of the costs will come down to storage and repairs. While there are many approaches to calculating the upfront “price”, a conservative strategy will likely involve the perpetual storage protocol generating revenue in the same currencies (fiat, Filecoin) as the liabilities incurred due to storage (i.e the all-in costs of storage). This approach relies on the fact that storage on Filecoin has two types of (fairly predictable) expenses:
The Filecoin portion (the cost of a loan in FIL, the FIL required to send messages over the network) and
The fiat portion (the cost of the harddrive, running the proofs, electricity)
A perpetual storage protocol that builds an endowment in the same mix of currencies as its liabilities can ensure that its costs are fully covered despite the volatility of a single token (as might be the case if the endowment was backed by a single currency). In addition, by putting the capital to work and generating yield, the upfront cost for the client can be reduced.
Staking
To generate yield in Filecoin, the natural place to focus would be on the base protocol of Filecoin itself. Storage providers are required to lock FIL as collateral in order to onboard capacity, and by running Filecoin’s consensus, they earn a return in the form of block rewards and transaction fees. The collateral requirements for the now ~4,000 storage providers on the Filecoin network create a high demand to borrow the FIL token. FIL staking would allow a holder of Filecoin to lend FIL — locking their capital with a storage provider and receiving yield by sharing in the rewards of the storage provider.
Today, programs exist with companies like Anchorage, Darma, and Coinlist to deploy Filecoin with some storage providers, but these programs can service only a subset of the storage providers and don’t support protocols (such as our perpetual storage protocol) that might be looking to generate yield.
Staking protocols can uniquely solve this problem — allowing for permissionless aggregation (allowing smart contracts to generate yield), and deployment of Filecoin to all storage providers directly on-chain. Similar to Lido or Rocketpool in Ethereum, these protocols could also create tokenized representations of the yield bearing versions of Filecoin — further allowing these tokenized representations to be used as collateral in other services (e.g. the trustless notary, retrievability oracles listed above).
Revenue Model: Staking protocols can monetize in a number of ways — including taking a percentage of the yield generated from deployed assets.
Note: Today, roughly 34% of the circulating supply of Filecoin is locked as collateral, less than half of some proof of stake networks (e.g. 69% for Solana, 71% for Cardano).
Cross Chain Messaging
The other portion of the storage costs (the fiat denominated portion) will need to generate yield — and while it makes sense that some of these solutions might be deployed on the FVM, it’s worth discussing the areas where DeFi in other ecosystems might be used to fund operations on Filecoin.
Cross chain messaging could connect the Filecoin economy to other ecosystems allowing perpetual storage protocols to create pools for their non-Filecoin assets (e.g. USDC) on other networks. This would allow these protocols to generate yield on stablecoins in deeper markets (e.g. Ethereum) and bridge back portions as needed to Filecoin when renewing deals. Perpetual storage protocols can offer differentiated sources of recurring demand for these lending protocols, as they likely will have a much more stable profile in terms of their deployment capital given their cost structure — similar to pension funds in the traditional economy.
Given an early source of demand for many perpetual storage protocols include communal data assets (e.g. NFTs, DeSci datasets) which primarily involve on-chain entities, it’s likely that over time we’ll see steady demand for these cross chain services. For cross chain messaging protocols, this offers a unique opportunity to capture value between the “trade” of these different economies — as services are rendered on either side.
Automated Market Makers (AMMs)
One last component worth mentioning in the value flow for our perpetual storage protocol is a need for AMMs. The protocols listed above offer solutions for yield generation, but at the moment of payment conversion of assets will likely need to happen (e.g. converting from a staked representation of Filecoin to Filecoin itself). This is where AMMs can help!
Outside of helping convert staked representations of Filecoin to Filecoin, AMMs can also be useful for allowing perpetual storage protocols to accept multiple types of currencies for payment (e.g. allowing ETH or SOL to be swapped into the appropriate amounts of FIL and stablecoins to fund the perpetual storage protocol). These conversions might happen on other chains as well — but similar to the traditional economy, it’s likely that over time we’ll see trade balances emerge between these economies and swaps to happen on both sides.
Conclusion
These examples are a subset of the use cases and business models that the FVM enables. While I focused on tracing the flow of data and value through the Filecoin economy, it’s worth underscoring this is just a single use case — many of these components could be re-used for other data flows as well. Given all services require remuneration, these naturally will tie to economic flows as well.
As Filecoin launches its retrieval markets and compute infrastructure, the network will support more powerful interactions — as well as creating new business opportunities to connect services to support higher order use cases. Furthermore, as more primitives are built out on the base layer of Filecoin (e.g. verifiable credentials around the greenness of storage providers, certifications for HIPAA compliance), you can imagine permutations of each of the base primitives built above allowing for more control at the user level about the service offerings they wish to consume (e.g. a perpetual storage protocol that will only allow green storage providers to participate in storing their data).The FVM dramatically increases the design space for developers looking to build on the hardware and services in the Filecoin economy — and can hopefully also provide tangible benefits for all of web3, allowing for existing protocols and services to now be connected to a broader set of use cases.Disclaimer: Personal views and not reflective of my employer nor should be treated as “official”. This information is intended to be used for informational purposes only. It is not investment advice. Although we try to ensure all information is accurate and up to date, occasionally unintended errors and misprints may occur.Special thanks to @duckie_han for helping shape this.