As we’ve written about previously, Filecoin is building an economy of open data services. While today, Filecoin’s economy is primarily oriented around storage services, as other services (retrieval, compute) come online, the utility of the Filecoin network will compound as they all anchor in and can be triggered from the same block space.
The Filecoin Virtual Machine (FVM) allows us to compose these services together, along with other on-chain services (e.g. financial services), to create more sophisticated offerings. This is similar to how the composability in Defi enables the construction of key financial markets services in a permissionless manner (e.g. auto investment capabilities (Yearn) which builds on liquidity pools like Curve and lending protocols like Compound). The FVM is an important milestone for Filecoin, as it allows anyone to build protocols to improve the Filecoin network and build valuable services for other participants. Smart contracts on Filecoin are unique in that they pair web3 offerings with real world services like storage and compute, provided by an open market.
In this blogpost, we’ll unpack a sample use case and its supporting components for the FVM, how these services might compose together, and the potential business opportunities behind them. One of the neat artifacts of what the FVM enables is for modularity between solutions, meaning components built for one protocol can be reused for others. While designing these solutions, hopefully builders (potentially you!) keep this in mind to maximize the customer set.
This is only a subset of the opportunities that the broader Filecoin community has put forward here, but the aim is to show how these services might intertwine and how the Filecoin economy might evolve.
Note: Over time, it’s likely that a number of these services will migrate to subnets via Interplanetary Consensus — but for this blogpost we want to paint a more detailed picture of what the Filecoin economy might look like early on.
The rest of the blog is laid out as follows:
- Motivating Use Case
– Perpetual Storage
- Managing Flows of Data
– Aggregator / Caching Nodes
– Trustless Notaries
– Retrievability Oracles
- Managing Flows of Funds
– Staking
– Cross Chain Messaging
– Automated Market Makers (AMMs)
Motivating Use Case
Perpetual Storage
Perpetual storage is a useful jumping point — as it motivates a number of the other services (both infrastructure and economic) in the network. Permanent storage (which we’ve argued previously is a subset of perpetual storage) is a market valued at ~$300 million.
The basic goal of perpetual storage is straightforward: enable users to specify terms for how their datasets should be stored (e.g. ensure there are always at least 10 copies of this data on the network) — without having to run additional infrastructure to manage repair or renewal of deals. As long as the funds exist to pay for storage services, the perpetual storage protocol should automatically incentivize the repair and restoration of any under-replicated dataset to meet the specified terms.
This tweet thread shares a mental model for how one might create and fund such a contract. In the simplest form, you can boil down a perpetual storage contract to a minimum set of requirements <cid, number of copies, USDC, FIL, rules for an auction>, and the primitives to verify proper execution. Filecoin’s proofs are critical — as they can tell us when data is under-replicated and allow us to trigger auctions to bring replication back to a minimum threshold.
In order to build the above, a number of services are required. While one protocol could try and solve for all the services required in a monolithic architecture, modular solutions would allow for re-use in other protocols. Below we’ll cover some of the middleware services that might exist to help enable the full end-to-end flow.
Managing the Flow of Data
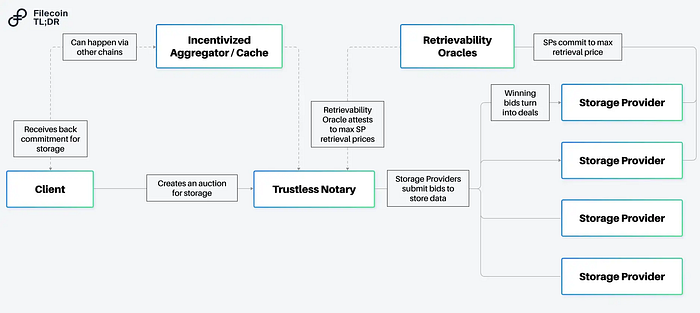
Aggregator / Caching Nodes
In our perpetual storage protocol, the client specifies some data that should be replicated. This leads to an interesting UX question — in many cases, users don’t want to have to wait for storage proofs to land on-chain to know the data will be stored and replicated. Instead, users might prefer to have their data persisted by an incentivized actor with guarantees that all other services will occur, similar to the role that data on-ramps play (like Estuary and NFT.Storage).
Note: One of the nice things about content addressing is that relying on incentivized actors is totally optional! Users wait for their data to land on-chain themselves if they’d like — or send their data to an incentivized network (as described here) that manages this onboarding process for them.
One solution to this UX question might be to design a protocol for an incentivized IPFS nodes operating with weaker storage guarantees to act as incentivized caches. These nodes might lock some collateral (to ensure good behavior, enact penalties if services are not rendered properly), and when data is submitted return a commitment to store the data Filecoin according to the specified requirements of the client. This commitment might include a merkle proof (showing the client’s data was included inside of a larger set of data that might be stored in aggregate), a max block height by which the deal would start, etc.
Revenue Model: One neat feature of this design for aggregator services is they can take small microtransactions on service on both sides — a small fee from clients (pricing the temporary storage costs, compute for aggregation, bandwidth costs, etc), and potentially an onboarding bounty from an auction protocol (an example described in the Trustless Notaries section below).
Trustless Notaries (Auction Protocols)
To actually make the deal on Filecoin, we might want to automate the process of using Filecoin Plus. Filecoin has two types of storage deals — verified deals and unverified deals. Verified deals refer to storage deals done via the Filecoin Plus program, and are advantageous for data clients as it leverages Filecoin’s network incentives to help reduce the cost of storage.
Today, Filecoin Plus uses DataCap (allocated by Notaries) to help imbue individual clients with the ability to store fixed amounts of data on the network. Notaries help add a layer of social trust to publicly verify that clients are authentic and prevent sybils from malicious actors. This works when clients are human — but it leaves an open question on how one can verify non-human (e.g. smart contract!) actors.
One solution would be to design a trustless notary. A trustless notary is a smart contract, where it would be economically irrational to attempt to sybil the deal-making process.
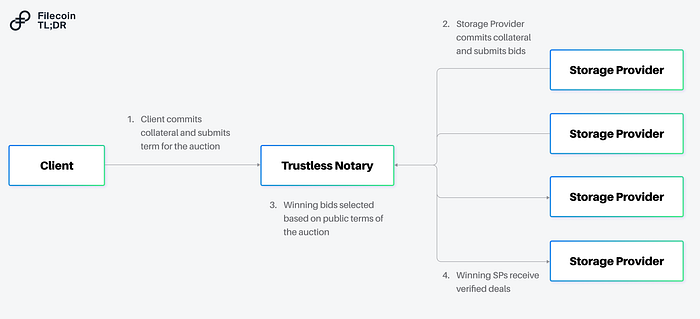
What might this look like? A trustless notary might be an on-chain auction, where all participants (clients, storage providers) are required to lock some collateral (proportional to the onboarding rate) to participate. When the auction is run, storage providers can submit valid bids (even negative ones!) accommodating the requirements of the client. By running an auction via a smart contract — everyone can verify that the winning bidder(s) came from a transparent process. Economic collateral (both from the clients and storage providers) can be used to disincentivize malicious actors and ensure closed auctions result in on-chain deals. The auction process might also allow for more sophisticated negotiations between a prospective client and storage provider — not just on the terms of the deal, but on the structure of the payment as well. A client looking to control costs might offer a payment in fiat (to cover a storage provider’s opex) along with a loan in Filecoin (and in return expect a large share of the resulting block rewards).
Revenue Model: For running the auction, the notary maintainer might collect some portion of fees for the deal clearing, collect a fee on locked collateral (e.g. if staked FIL is used as the collateral some slice of the yield), or some combination of both. One nice artifact about running a transparent auction is it can also allow for negative prices for storage (which can be used to fund an insurance fund for datasets, bounties for teams that help onboard new clients, distributed to tokenholders who participate in governance of the trustless notary, etc).
Note: Trustless notaries (if designed correctly) have a distinct advantage of being permissionless — where they can support any number of use cases that might not want humans in the loop (e.g. ETL pipelines that want to automatically store derivative datasets). Today, 393 PiB of data have been stored via verified deals.
In our perpetual storage use case, we’d likely want to be able to leverage the trustless notary to trigger the deal renewals and auctions any time a dataset is under replicated. On the first iteration, this means that storage providers might grab the data out of the caching nodes and on subsequent iterations from other storage providers who have copies of the data.
Retrievability Oracles
For both the deals struck by the trustless notaries, as well as for the caching done by the aggregators — we need to ensure data is properly transferred and protect clients against price gouging. One solution to this problem are retrievability oracles.
Retrievability oracles are consortiums that allow a storage provider to commit to a maximum retrieval price for the data stored. The basic mechanism is as follows:
- When striking a deal with a client, a storage provider additionally can commit to retrieval terms.
- In doing so, the storage provider locks collateral with the retrievability oracle along with relevant commitment (e.g. max price to charge per GiB for some duration).
- In normal operation, the client and the storage provider continue to store and retrieve data as normal.
- In the event the storage provider refuses to serve data (against whatever terms previously agreed), the client can appeal to the retrievability oracle who can request the data from the storage provider.
→ If the storage provider serves the data to the oracle, the data is forwarded to the client.
→ If the storage provider doesn’t serve the data, the storage provider is slashed.
Revenue Model: For running the retrieval oracles, the consortium may collect fees (either from storage providers for using the service, fees for accepting different forms of collateral, yield from staked collateral, or perhaps upon retrieval of data on behalf of the client).
By including a retrievability oracle in this loop, we can ensure incentives exist to proper transfer of data at the relevant points of the lifecycle of our perpetual storage protocol.
Building the Economic Loop
With all of the above, we’ve effectively created incentivized versions of the relevant components for the dataflows. Now with this out of the way, it’s worthwhile to focus on the economic flows and how we can ensure that our perpetual storage protocol can fully fund the operations above.
Aside from the initial onboarding costs, the remainder of the costs will come down to storage and repairs. While there are many approaches to calculating the upfront “price”, a conservative strategy will likely involve the perpetual storage protocol generating revenue in the same currencies (fiat, Filecoin) as the liabilities incurred due to storage (i.e the all-in costs of storage). This approach relies on the fact that storage on Filecoin has two types of (fairly predictable) expenses:
- The Filecoin portion (the cost of a loan in FIL, the FIL required to send messages over the network) and
- The fiat portion (the cost of the harddrive, running the proofs, electricity)
A perpetual storage protocol that builds an endowment in the same mix of currencies as its liabilities can ensure that its costs are fully covered despite the volatility of a single token (as might be the case if the endowment was backed by a single currency). In addition, by putting the capital to work and generating yield, the upfront cost for the client can be reduced.
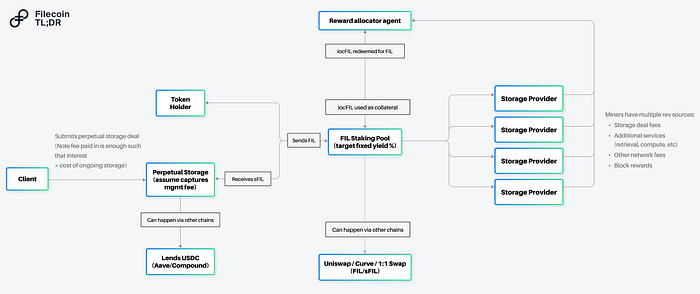
Staking
To generate yield in Filecoin, the natural place to focus would be on the base protocol of Filecoin itself. Storage providers are required to lock FIL as collateral in order to onboard capacity, and by running Filecoin’s consensus, they earn a return in the form of block rewards and transaction fees. The collateral requirements for the now ~4,000 storage providers on the Filecoin network create a high demand to borrow the FIL token. FIL staking would allow a holder of Filecoin to lend FIL — locking their capital with a storage provider and receiving yield by sharing in the rewards of the storage provider.
Today, programs exist with companies like Anchorage, Darma, and Coinlist to deploy Filecoin with some storage providers, but these programs can service only a subset of the storage providers and don’t support protocols (such as our perpetual storage protocol) that might be looking to generate yield.
Staking protocols can uniquely solve this problem — allowing for permissionless aggregation (allowing smart contracts to generate yield), and deployment of Filecoin to all storage providers directly on-chain. Similar to Lido or Rocketpool in Ethereum, these protocols could also create tokenized representations of the yield bearing versions of Filecoin — further allowing these tokenized representations to be used as collateral in other services (e.g. the trustless notary, retrievability oracles listed above).
Revenue Model: Staking protocols can monetize in a number of ways — including taking a percentage of the yield generated from deployed assets.
Note: Today, roughly 34% of the circulating supply of Filecoin is locked as collateral, less than half of some proof of stake networks (e.g. 69% for Solana, 71% for Cardano).
Cross Chain Messaging
The other portion of the storage costs (the fiat denominated portion) will need to generate yield — and while it makes sense that some of these solutions might be deployed on the FVM, it’s worth discussing the areas where DeFi in other ecosystems might be used to fund operations on Filecoin.
Cross chain messaging could connect the Filecoin economy to other ecosystems allowing perpetual storage protocols to create pools for their non-Filecoin assets (e.g. USDC) on other networks. This would allow these protocols to generate yield on stablecoins in deeper markets (e.g. Ethereum) and bridge back portions as needed to Filecoin when renewing deals. Perpetual storage protocols can offer differentiated sources of recurring demand for these lending protocols, as they likely will have a much more stable profile in terms of their deployment capital given their cost structure — similar to pension funds in the traditional economy.
Given an early source of demand for many perpetual storage protocols include communal data assets (e.g. NFTs, DeSci datasets) which primarily involve on-chain entities, it’s likely that over time we’ll see steady demand for these cross chain services. For cross chain messaging protocols, this offers a unique opportunity to capture value between the “trade” of these different economies — as services are rendered on either side.
Automated Market Makers (AMMs)
One last component worth mentioning in the value flow for our perpetual storage protocol is a need for AMMs. The protocols listed above offer solutions for yield generation, but at the moment of payment conversion of assets will likely need to happen (e.g. converting from a staked representation of Filecoin to Filecoin itself). This is where AMMs can help!
Outside of helping convert staked representations of Filecoin to Filecoin, AMMs can also be useful for allowing perpetual storage protocols to accept multiple types of currencies for payment (e.g. allowing ETH or SOL to be swapped into the appropriate amounts of FIL and stablecoins to fund the perpetual storage protocol). These conversions might happen on other chains as well — but similar to the traditional economy, it’s likely that over time we’ll see trade balances emerge between these economies and swaps to happen on both sides.
Conclusion
These examples are a subset of the use cases and business models that the FVM enables. While I focused on tracing the flow of data and value through the Filecoin economy, it’s worth underscoring this is just a single use case — many of these components could be re-used for other data flows as well. Given all services require remuneration, these naturally will tie to economic flows as well.
As Filecoin launches its retrieval markets and compute infrastructure, the network will support more powerful interactions — as well as creating new business opportunities to connect services to support higher order use cases. Furthermore, as more primitives are built out on the base layer of Filecoin (e.g. verifiable credentials around the greenness of storage providers, certifications for HIPAA compliance), you can imagine permutations of each of the base primitives built above allowing for more control at the user level about the service offerings they wish to consume (e.g. a perpetual storage protocol that will only allow green storage providers to participate in storing their data).The FVM dramatically increases the design space for developers looking to build on the hardware and services in the Filecoin economy — and can hopefully also provide tangible benefits for all of web3, allowing for existing protocols and services to now be connected to a broader set of use cases.Disclaimer: Personal views and not reflective of my employer nor should be treated as “official”. This information is intended to be used for informational purposes only. It is not investment advice. Although we try to ensure all information is accurate and up to date, occasionally unintended errors and misprints may occur.Special thanks to @duckie_han for helping shape this.