The Filecoin TL;DR team was in Istanbul for LabWeek (Protocol Labs’ annual gathering) organized in conjunction with Devconnect from Nov. 12-18. More than 65 teams participated in 40 plus events over one week to connect, collaborate, and innovate. Several critical updates were shared by teams across key components of the roadmap to unlock Filecoin’s open data economy.
This blog will cover key takeaways from LabWeek 2023 and is organized into the following 3 sections:
- InterPlanetary Consensus (IPC) and how it enables planetary-level scalability
- Filecoin’s explosive DeFi growth unlocked by Filecoin Virtual Machine
- New Filecoin projects/toolings: DeStor REST API, SPARK and Lilypad
Scalability: IPC Subnets
In his opening keynote, Protocol Labs’ founder Juan Benet laid out the network’s vision — to push humanity forward by driving breakthroughs in computing. Blockchains can help secure the internet, upgrade governance systems, and develop safe AGI among other things. But for that to happen, Web3 must scale to meet internet-level volumes, compute, and user demands.
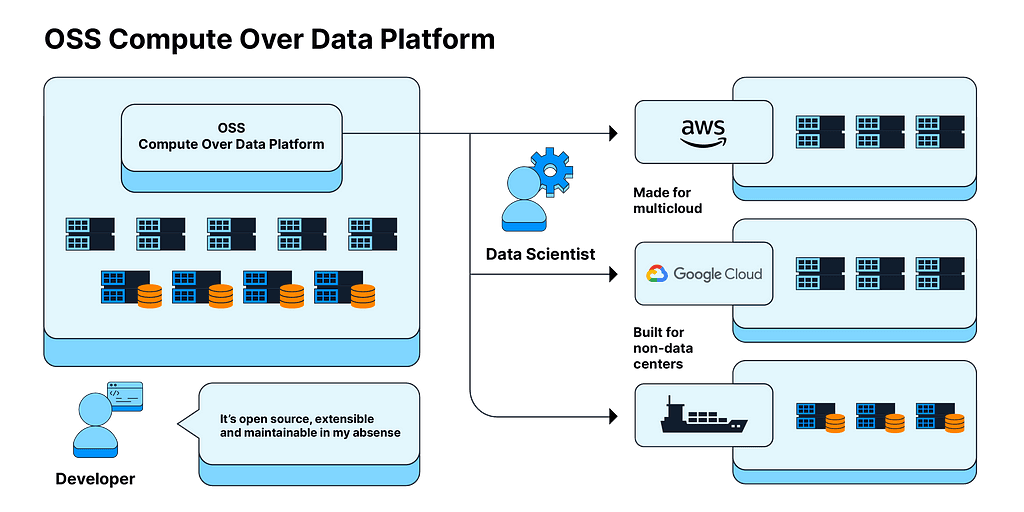
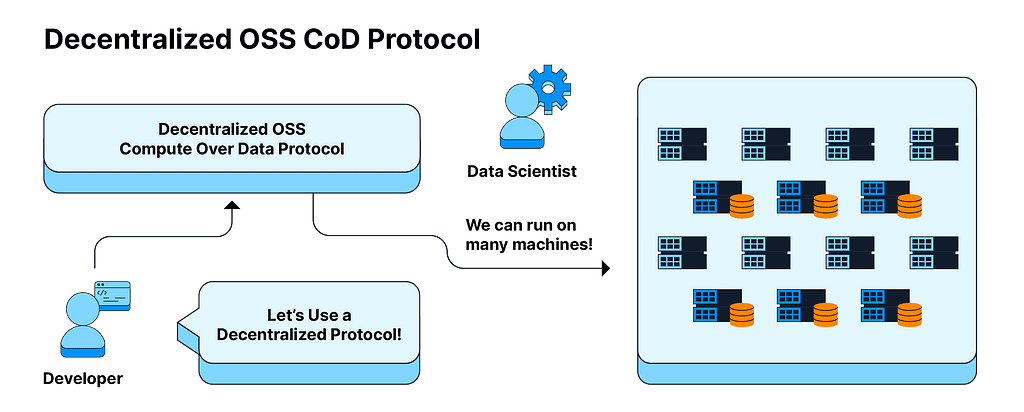
To address this challenge, Protocol Labs launched InterPlanetary Consensus (IPC) as a testnet in 2022 after 18 months of research and development. IPC aims to unlock the ability to perform millions or even billions of transactions/second on-chain and provide a frictionless developer experience. What was majorly at the developmental stage has now moved to productionizing and adoption. Some early adopters of IPC include Lilypad, Fluence, Spark, TableLand, Movespace, and The Op Games.
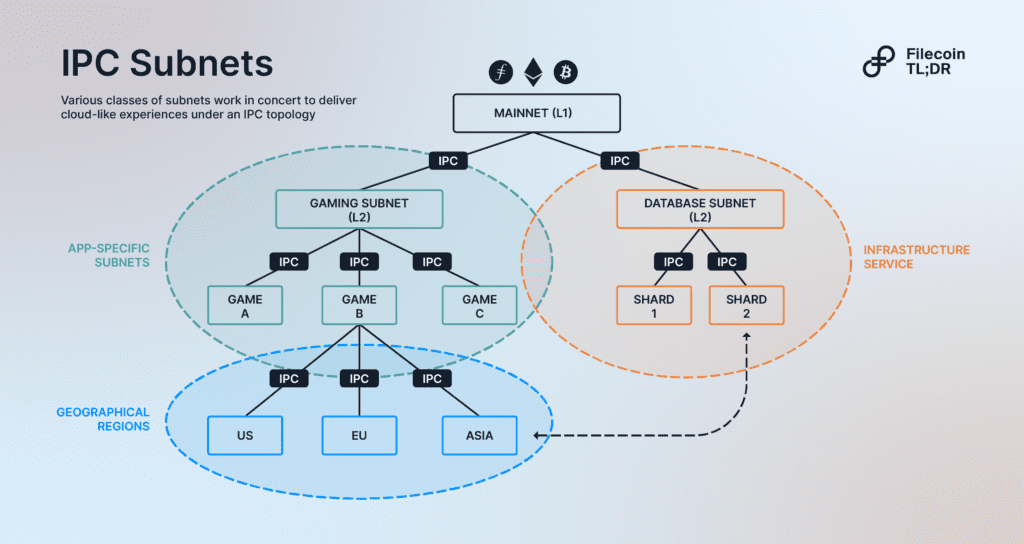
IPC provides a simple scaling model based on horizontal and vertical scaling. It revolves around the concept of subnets or recursive trees of blockchains that can spin up and close down statically, or in the future, dynamically. What’s interesting is that these subnet trees can be organized by geography, latency, privacy, and maturity, much like internet regions and data centers work today. IPC interconnects different subnets so they can message each other securely.
In essence, an IPC chain can spawn new subnets (domain, app, region, etc.) with a separate consensus algorithm while each of these child subnets depend on the parent chain to confirm transactions and inherit security features. Such a modular model brings several key advantages: Web-2 level speed (less than 1s transactions), deeply customizable runtime modules, and full EVM-compatibility with solidity tooling among other things.
Two major IPC-related launches at LabWeek23 include:
- IPC M2.5 Fenderment Release which implements IPC with Tendermint Core.
- Mycelium Calibration Testnet, an IPC subnet for devs to experiment & bootstrap quickly.
To learn more about IPC and get yourself started with subnets, refer here.
DeFi Growth Enabled by FVM
Filecoin Virtual Machine (FVM), launched in March this year, brought user programmability and smart contracts to the Filecoin network, unlocking a plethora of use cases. Today, more than 200 teams are building on FVM deploying 2,000 plus unique smart contracts, propelling Filecoin to reach top 25 chains in Total Value Locked (TVL) in just 6 months (46% MoM).
FVM’s adoption (amidst bear markets) was widely cited as a critical breakthrough for Filecoin in 2023 throughout LabWeek. Particularly, FVM plays a pivotal role in addressing a pre-existing problem in the Filecoin network. Previously, Storage Providers (SP) struggled to access large amounts of FIL needed to pledge as collateral to operate on the network which bottlenecked data storage.

DeFi protocols like Glif, stFIL, and CollectifDAO solved this problem by leveraging FVM-based smart contracts to create liquidity pools that connected token holders with SPs in need of FIL. Today, token holders have deposited nearly 17M FIL in smart contracts. Of this, 14M FIL is borrowed by over 500 SPs globally. Nearly 40% of all the FIL pledges today are borrowed from DeFi platforms unlocking a vibrant token economy for the ecosystem.
Besides staking services, the network is witnessing traction across various other dApp themes such as data storage (Lighthouse, NFT.Storage), retrieval (Saturn, FlowSheild), and Compute-over-Data networks (Bacalhau, Lilypad) bringing value into the ecosystem. More recently, DEXes such as Sushi and UniSwap announced support for Filecoin further boosting the economy.
However, what FVM has unleashed so far is just the tip of the iceberg. We can see interesting projects across new domains coming up. One such project that received the spotlight at LabWeek was Secured Finance, an FVM–based DeFi product aiming to revolutionize capital markets for digital asset investors.
Follow Starboard’s DeFi dashboard for the latest data on FVM.
New Projects & Tooling
Lab Week 2023 included many new Filecoin projects and tooling systems. Particularly, much attention went toward easing the data onboarding process, ensuring reliable retrieval and bringing compute to onboarded data.
DeStor REST API
Data onboarding and retrieval workflow on the Filecoin network is complicated. It involves too many steps with a steep learning curve compared to traditional storage systems. DeStor REST API is a collective effort from several teams in the PL network to abstract away some of these complexities. The API layer provides an intermediate library that lets MSPs build custom systems with just the complexity their clients need.
The DeStor REST API, currently a beta release, is a step closer to bringing Filecoin to existing Web2 applications. Will Scott, Research Engineer at PL, believes the tool will enable large amounts of data to be onboarded over time.
Project SPARK: SP Retrieval Checker built on Filecoin Station
With tools like Lassie, IPNI, Saturn, and Boost, the rails are in place to serve retrievals on the Filecoin network. However, the lack of incentive mechanisms for Storage Providers to perform retrieval jobs reliably is still an issue. SPARK, designed as a trustless protocol for sampling retrievals from Filecoin Storage Providers, aims to help incentivize higher performance retrievals.
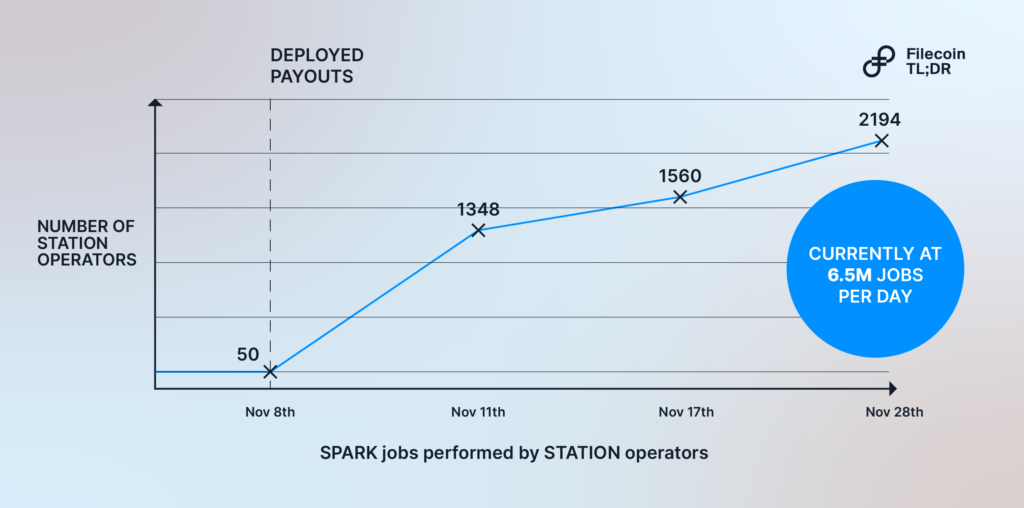
Filecoin Station, a desktop app that connects your computer’s idle resources to the Filecoin network and rewards you with FIL, allows operators to perform SPARK jobs from their Station module and earn FIL rewards. As of November 2023, Station operators have completed 149.9m SPARK jobs. You can head to Filecoin Station to contribute your computer’s spare resources and earn rewards.
Lilypad Network
Lilypad, a distributed, verifiable compute platform, dropped some key announcements during LabWeek. Lilypad is an internet-scale compute marketplace aimed at unlocking global CPUs and GPUs available on the Filecoin network and beyond by matching this idle supply to the parabolic demand for AI & ML jobs.
Currently, the Lilypad Aurora testnet is live on IPC and uses its own ERC20 (LP) for services and gas payments. You can access AI & ML jobs like Stable Diffusion and LLM inference directly from a CLI or build them into your smart contract.
Lilypad has also launched two new initiatives: the Lilypad Baklava Calibration Phase and Lilypad AI Studio. For those who want to use AI without any of the fuss, Lilypad AI Studio provides a simple social sign-in giving access to all models. If you’ve got idle GPU to spare, you can join early adopters like Holon, LabDAO, and PikNik to help calibrate the decentralized compute cloud via Baklava here.
Wrapping Up
In summary, progress in FVM, IPC and Filecoin tooling will play a major role in unlocking Phase-2 (onboard data) and Phase-3 (bring compute to data) of the Filecoin Masterplan. Overall, Lab Week 2023 has set the tone for upcoming network milestones (2024) including faster and simpler storage onramps, reliable retrieval, onboarding more paying users, and building high-value applications and compute networks.
🇨🇳 解析Filecoin 11月在伊斯坦布尔的LabWeek2023中的三大亮点
Many thanks to Nathaniel Kok, HQ Han, Jonathan Victor, and Andrew Alimbuyuguen for their support in publishing this piece.