Editor’s Note: This blogpost is a repost of the original content published on 5 March 2024, by Bidhan Roy and Marcos Villagra from Bagel. Founded in 2023 by CEO Bidhan Roy, Bagel is a machine learning and cryptography research lab building a permissionless, privacy-preserving machine learning ecosystem. This blogpost represents the independent view of these authors, whom have given their permission for this re-publication.
Trillion-dollar industries are unable to leverage their immensely valuable data for AI training and inference due to privacy concerns. The potential for AI-driven breakthroughs—genomic secrets that could cure diseases, predictive insights to eliminate supply chain waste, and chevrons of untapped energy sources—remain locked away. Privacy regulations also closely guard this valuable and sensitive information.
To propel human civilization forward in energy, healthcare, and collaboration, it is crucial to enable AI systems that train and generate inference on data while maintaining full end-to-end privacy. At Bagel, pioneering this capability is our mission. We believe accessing a fundamental resource like knowledge, for both human-driven and autonomous AI, should not entail a compromise on privacy.
We have applied and experimented with almost all the major privacy-preserving machine learning (PPML) mechanisms. Below, we share our insights, our approach, and some research breakthroughs.
And if you’re in a rush, we have a TLDR at the end.
Privacy-preserving Machine Learning (PPML)
Recent advances in academia and industry have focused on incorporating privacy mechanisms into machine learning models, highlighting a significant move towards privacy-preserving machine learning (PPML). At Bagel, we have experimented with all the major PPML techniques, particularly those post differential privacy. Our work, positioned at the intersection of AI and cryptography, draws from the cutting edge in both domains.
First, we will delve into each of these, examining their advantages and drawbacks. In subsequent posts, we will describe Bagel’s approach to data privacy, which addresses and resolves the challenges associated with the existing solutions.
Differential Privacy (DP)
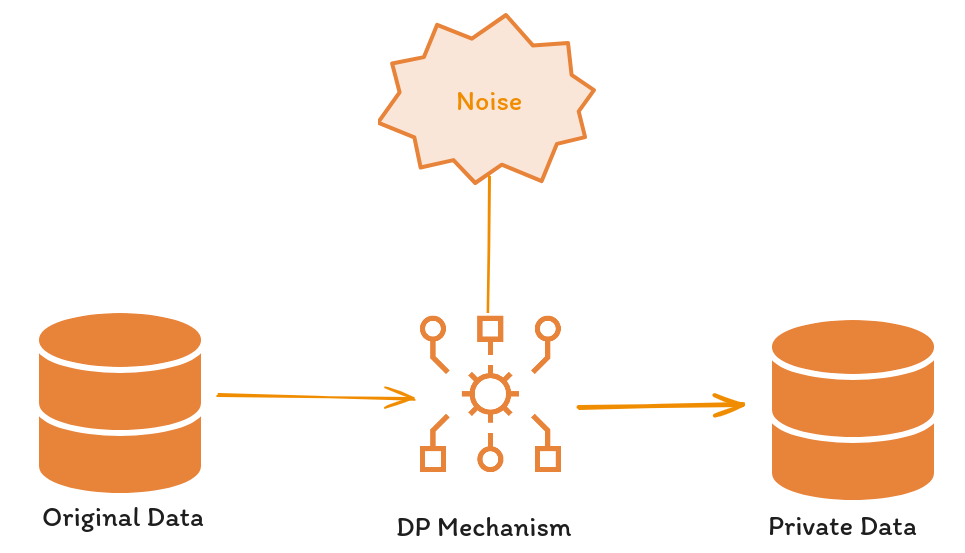
One of the first and most important techniques with a mathematical guarantee for incorporating privacy into data is differential privacy or DP (Dwork et al. 2006), addressing the challenges faced by earlier methods with a quantifiable privacy definition.
DP ensures that a randomized algorithm, A, maintains privacy across datasets D1 and D2—which differ by a single record—by keeping the probability of A(D1) and A(D2) generating identical outcomes relatively unchanged. This principle implies that minor dataset modifications do not significantly alter outcome probabilities, marking a pivotal advancement in data privacy.
The application of DP in machine learning, particularly in neural network training and inference, demonstrates its versatility and effectiveness. Notable implementations include adapting DP for supervised learning algorithms by integrating random noise at various phases: directly onto the data, within the training process, or during inference, as highlighted by Ponomareva et al. (2023) and further references.
The balance between privacy and accuracy in DP is influenced by the noise level: greater noise enhances privacy at the cost of accuracy, affecting both inference and training stages. This relationship was explored by Abadi et al. in (2016) through the introduction of Gaussian noise to the stochastic gradient descent (DP-SGD) algorithm, observing the noise’s impact on accuracy across the MNIST and CIFAR-10 datasets.
An innovative DP application, Private Aggregation of Teacher Ensembles (PATE) by Papernot et al. in (2016), divides a dataset into disjoint subsets, training networks on each without privacy, termed as teachers. These networks’ aggregated inferences, subjected to added noise for privacy, inform the training of a student model to emulate the teacher ensemble. This method also underscores the trade-off between privacy enhancement through noise addition and the resultant accuracy reduction.
Further studies affirm that while privacy can be secured with little impact on execution times (Li et a. 2015), stringent privacy measures can obscure discernible patterns essential for learning (Abadi et al. 2016). Consequently, a certain level of privacy must be relinquished in DP to facilitate effective machine learning model training, illustrating the nuanced balance between privacy preservation and learning efficiency.
Pros of Differential Privacy
The advantages of using DP are:
Effortless. Easy to implement into algorithms and code.
Algorithm independence. Schemes can be made independent of the training or inference algorithm.
Fast. Some DP mechanisms have shown to have little impact on the execution times of algorithms.
Tunable privacy. The degree of desired privacy can be chosen by the algorithm designer.
Cons of Differential Privacy
Access to private data is still necessary. Teachers in the PATE scheme must have full access to the private data (Papernot et al. 2016) in order to train a neural network. Also, the stochastic gradient descent algorithm based on DP only adds noise to the weight updates and needs access to private data for training (Abadi et al. 2016).
Privacy-Accuracy-Speed trade-off on data. All implementations must sacrifice some privacy in order to get good results. If there is no discernable pattern in the input, then there is nothing to train (Feyisetan et al. 2020). The implementation of some noise mechanisms can impact execution times, necessitating a balance between speed and the goals of privacy and accuracy.
Zero-Knowledge Machine Learning (ZKML)
A zero-knowledge proof system (ZKP) is a method allowing a prover P to convince a verifier V about the truth of a statement without disclosing any information apart from the statement’s veracity. To affirm the statement’s truth, P produces a proof π for V to review, enabling V to be convinced of the statement’s truthfulness.
Zero-Knowledge Machine Learning (ZKML) is an approach that combines the principles of zero-knowledge proofs (ZKPs) with machine learning. This integration allows machine learning models to be trained and to infer with verifiability.
For an in-depth examination of ZKML, refer to the work by Xin et al. in (2023). Below we provide a brief explanation that focuses on the utilization of ZKPs for neural network training and inference.
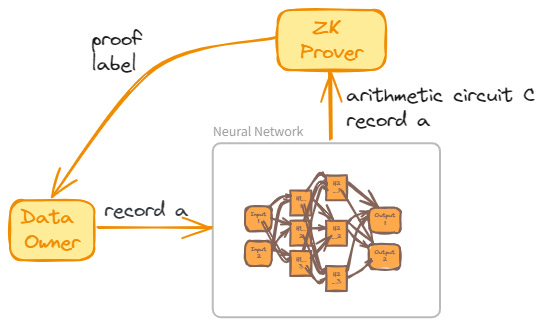
ZKML Inference
Consider an unlabeled dataset A and a pretrained neural network N tasked with labeling each record in A. To generate a ZK proof of N‘s computation during labeling, an arithmetic circuit C representing N is required, including circuits for each neuron’s activation function. Assuming such a circuit C exists and is publicly accessible, the network’s weights and a dataset record become the private and public inputs, respectively. For any record a of A, N‘s output is denoted by a pair (l,π), where l is the label and π is a zero-knowledge argument asserting the existence of specific weights that facilitated the labeling.
This model illustrates how ZK proves the accurate execution of a neural network on data, concealing the network’s weights within a ZK proof. Consequently, any verifier can be assured that the executing agent possesses the necessary weights.
ZKML Training
ZKPs are applicable during training to validate N‘s correct execution on a labeled dataset A. Here, A serves as the public input, with an arithmetic circuit C depicting the neural network N. The training process requires an additional arithmetic circuit to implement the optimization function, minimizing the loss function. For each training epoch i, a proof π_i is generated, confirming the algorithm’s accurate execution through epochs 1 to i-1, including the validity of the preceding epoch’s proof. The training culminates with a compressed proof π, proving the correct training over dataset A.
The explanation above illustrates that during training, the network’s weights are concealed to ensure that the training is correctly executed on the given dataset A. Additionally, all internal states of the network remain undisclosed throughout the training process.
Pros of ZKML
The advantages of using ZKPs with neural networks are:
Privacy of model weights. The weights of the neural network are never revealed during training or inference in any way. The weights and the internal states of the network algorithm are private inputs for the ZKP.
Verifiability. The proof certifies the proper execution of training or inference processes and guarantees the accurate computation of weights.
Trustlessness. The proof and its verification properties ensure that the data owner is not required to place trust in the agent operating the neural network. Instead, the data owner can rely on the proof to confirm the accuracy of both the computation and the existence of correct weights.
Cons of ZKML
The disadvantages of using ZKPs with neural networks are:
No data privacy. The agent running the neural network needs access to the data in order to train or do inference. Data is considered a parameter that is publicly known to the data owner and the prover running the neural network (Xing et al. 2023).
No privacy for the model’s algorithm. In order to create a ZK proof, the algorithm of the entire neural network should be publicly known. This includes the activation functions, the loss function, optimization algorithm used, etc (Xing et al. 2023).
Proof generation of an expensive computation. Presently, the process of generating a ZK proof is computationally demanding—-see for example this report on the computation times of ZK provers. Creating a proof for each epoch within a training algorithm can exacerbate the computational burden of an already resource-intensive task.
Federated Learning (FL)
In Federated Learning or FL we look to train a global model using a dataset that is distributed in multiple servers with local data samples but without each server sharing their local data.
In FL there is a global objective function that is being optimized which is defined as
𝑓(𝑥1,…,𝑥𝑛)=1𝑛∑𝑖=1𝑛𝑓𝑖(𝑥𝑖),\(f(x_1,\dots,x_n)=\frac 1 n \sum_{i=1}^n f_i(x_i),\)
where n is the number of servers, each variables is the set of parameter as viewed by the server i, and each function is a local objective function of server i. FL tries to find the best set of values that optimizes f.
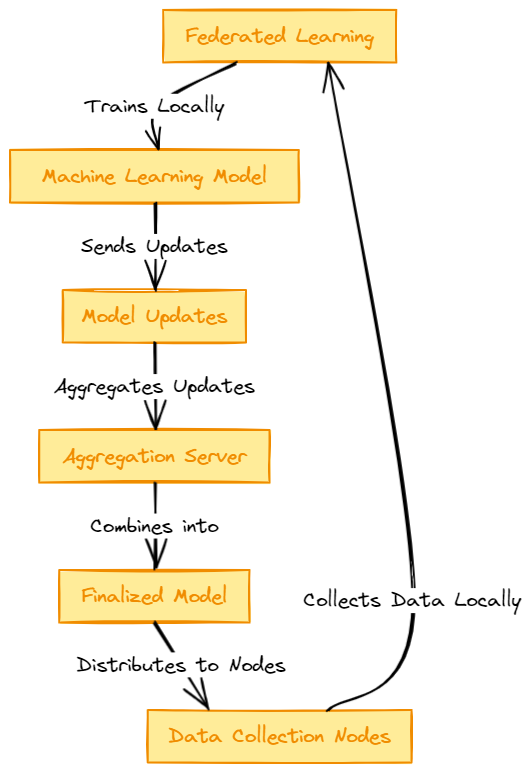
The figure below shows the general process in FL.
Initialization. An initial global model is created and distributed by a central server to all other servers.
Local training. Each server trains the model using their local data. This ensures data privacy and security.
Model update. After training, each server shares with the central server their local updates like gradients and parameters.
Aggregation. The central server receives all local updates and aggregates them into the global model, for example, using averaging.
Model distribution. The updated model is distributed again with local servers and the previous steps are repeated until a desired level of performance is achieve by the global model.
Since local servers never share their local data, FL guarantees privacy over that data. However, the model being constructed is shared among all parties, and hence, its structure and set of parameters are not hidden.
Pros of FL
The advantages of using FL are:
Data privacy. The local data on the local servers are never shared. All computations are done locally, and there is no need of communication between them.
Distributed computing. The creation of the global model is distributed among local servers, thereby parallelizing a resource-intensive computation. Thus, FL is considered a distributed machine learning framework (Xu et al. 2021).
Cons of FL
The disadvantages of using FL are:
Model is not private. The global model is shared among each local server in order to do their computations locally. This includes the aggregated weights and gradients at each step of the FL process. Thus, each local server is aware of the entire architecture of the global model (Konečný et al. 2016).
Data leakage. Recent research indicates that data leakage remains a persistent issue, notably through mechanisms such as gradient sharing—see for example Jin et al. (2022). Consequently, FL cannot provide complete assurances of data privacy.
Trust. Since no proofs are generated in FL, every party involved in the process need to be trusted that their computation and parameters were computed as expected (Gao et al. 2023).
Fully Homomorphic Encryption (FHE)
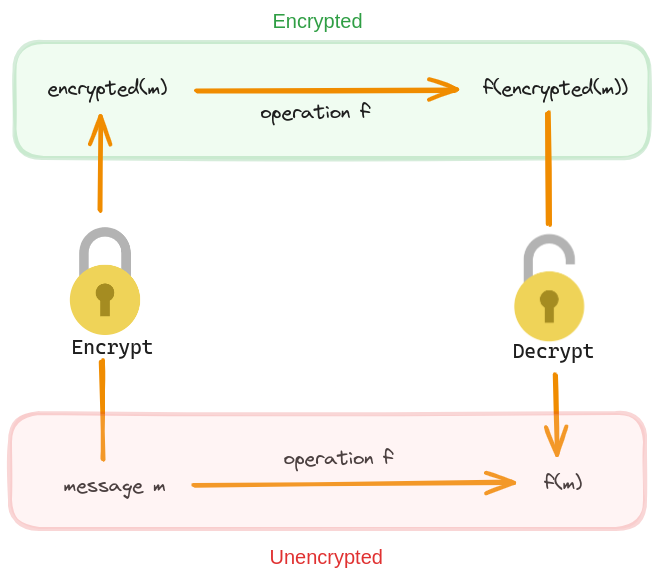
At its core, homomorphic encryption permits computations on encrypted data. By “homomorphic,” we refer to the capacity of an encryption scheme to allow specific operations on ciphertexts that, when decrypted, yield the same result as operations performed directly on the plaintexts.
Consider a scenario with a secret key k and a plaintext m. In an encryption scheme (E,D), where E and D represent encryption and decryption algorithms respectively, the condition D(k,E(k,m))=m must hold. A scheme (E,D) is deemed fully homomorphic if for any key k and messages m, the properties E(k,m+m’)=E(k,m)+E(k,m’) and E(k,m*m’)=E(k,m)* E(k,m’) are satisfied, with addition and multiplication defined over a finite field. If only one operation is supported, the scheme is partially homomorphic. This definition implies that operations on encrypted data mirror those on plaintext, crucial for maintaining data privacy during processing.
In plain words, if we have a fully homomorphic encryption scheme, then operating over the encrypted data is equivalent to operating over the plaintext. We will write FHE to refer to a fully homomorphic encryption scheme. The figure below shows how an arbitrary homomorphic operation works over a plaintext and ciphertext.
The homomorphic property of FHE makes it invaluable in situations where data must remain secure while still being used for computations. For instance, if we possess sensitive data and require a third party to perform data analysis on it, we can rely on FHE to encrypt the data. This allows the third party to conduct analysis on the encrypted data without the need for decryption. The mathematical properties of FHE guarantee the accuracy of the analysis results.
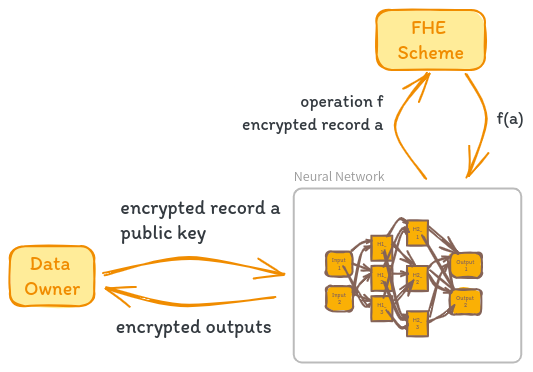
FHE Inference
Fully Homomorphic Encryption (FHE) can be used to perform inference in neural networks while preserving data privacy. Let’s consider a scenario where N is a pretrained neural network, A is a dataset, and (E,D) is an asymmetric FHE scheme. The goal is to perform inference on a record a of A without revealing the sensitive information contained in a to the neural network.
The inference process using FHE begins with encryption. The data owner encrypts the record a using the encryption algorithm E with the public key public_key, obtaining the encrypted record a’ = E(public_key, a).
Next, the data owner sends the encrypted record a’ along with public_key to the neural network N. The neural network N must have knowledge of the encryption scheme (E,D) and its parameters to correctly apply homomorphic operations over the encrypted data a’. Any arithmetic operation performed by N can be safely applied to a’ due to the homomorphic properties of the encryption scheme.
One challenge in using FHE for neural network inference is handling non-linear activation functions, such as sigmoid and ReLU, which involve non-arithmetic computations. To compute these functions homomorphically, they need to be approximated by low-degree polynomials. The approximations allow the activation functions to be computed using homomorphic operations on the encrypted data a’.
After applying the necessary homomorphic operations and approximated activation functions, the neural network N obtains the inference result. It’s important to note that the inference result is still in encrypted form, as all computations were performed on encrypted data.
Finally, the encrypted inference result is sent back to the data owner, who uses the private key associated with the FHE scheme to decrypt the result using the decryption algorithm D. The decrypted inference result is obtained, which can be interpreted and utilized by the data owner.
By following this inference process, the neural network N can perform computations on the encrypted data a’ without having access to the original sensitive information. The FHE scheme ensures that the data remains encrypted throughout the inference process, and only the data owner with the private key can decrypt the final result.
It’s important to note that the neural network N must be designed and trained to work with the specific FHE scheme and its parameters. Additionally, the approximation of non-linear activation functions by low-degree polynomials may introduce some level of approximation error, which should be considered and evaluated based on the specific application and accuracy requirements.
FHE Training
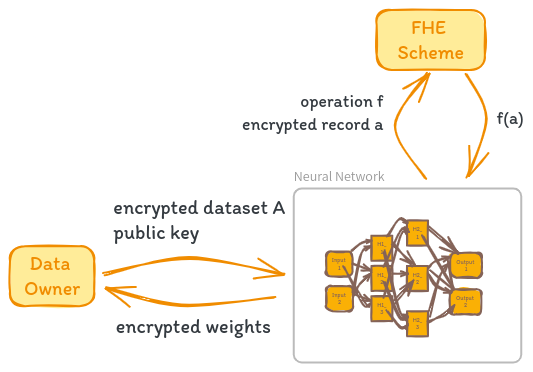
The process of training a neural network using Fully Homomorphic Encryption (FHE) is conceptually similar to performing inference, but with a few key differences. Let’s dive into the details.
Imagine we have an untrained neural network N and an encrypted dataset A’ = E(public_key, A), where E is the encryption function and public_key is the public key of an asymmetric FHE scheme. Our goal is to train N on the encrypted data A’ while preserving the privacy of the original dataset A.
The training process unfolds as follows. Each operation performed by the network and the training algorithm is executed on each encrypted record a’ of A'. This includes both the forward and backward passes of the network. As with inference, any non-arithmetic operations like activation functions need to be approximated using low-degree polynomials to be compatible with the homomorphic properties of FHE.
A fascinating aspect of this approach is that the weights obtained during training are themselves encrypted. They can only be decrypted using the private key of the FHE scheme, which is held exclusively by the data owner. This means that even the agent executing the neural network training never has access to the actual weight values, only their encrypted counterparts.
Think about the implications of this. The data owner can outsource the computational heavy lifting of training to a third party, like a cloud provider with powerful GPUs, without ever revealing their sensitive data. The training process operates on encrypted data and produces encrypted weights, ensuring end-to-end privacy.
Once training is complete, the neural network sends the collection of encrypted weights w’ back to the data owner. The data owner can then decrypt the weights using his private key, obtaining the final trained model. He is the sole party capable of accessing the unencrypted weights and using the model for inference on plaintext data.
There are a few caveats to keep in mind. FHE operations are computationally expensive, so training a neural network with FHE will generally be slower than training on unencrypted data.
Pros of FHE
The advantages of using FHE are:
Data privacy. Third-party access to encrypted private data is effectively prevented, a security guarantee upheld by the assurances of FHE and lattice-based cryptography(Gentry 2009).
Model privacy. Training and inference processes are carried out on encrypted data, eliminating the need to share or publicize the neural network’s parameters for accurate data analysis.
Effectiveness. Previous studies have demonstrated that neural networks operating on encrypted data using FHE maintain their accuracy—see for example Nandakumar et al. (2019) and Xu et al. (2019). Therefore, we can be assured that employing FHE for training and inference processes will achieve the anticipated outcomes.
Quantum resistance. The security of FHE, unlike other encryption schemes, is grounded in difficult problems derived from Lattice theory. These problems are considered to be hard even for quantum computers (Regev 2005), thus offering enhanced protection against potential quantum threats in the future.
Cons of FHE
The disadvantages of using FHE are:
Verifiability. FHE does not offer proofs of correct encryption nor correct computation. Hence, we must rely on trust that the data intended for encryption is indeed the correct data (Viand et al. 2023).
Speed. Relative to conventional encryption schemes, FHE is still considered to be slow during parameter setups, encryption and decryption algorithms (Gorantala et al. 2023).
Memory requirements. The number of weights that need to be encrypted are proportional to the size of the network. Even for small networks, the RAM memory requirements are in the order of gigabytes (Chen et al. 2018), (Nandakumar et al. 2019).
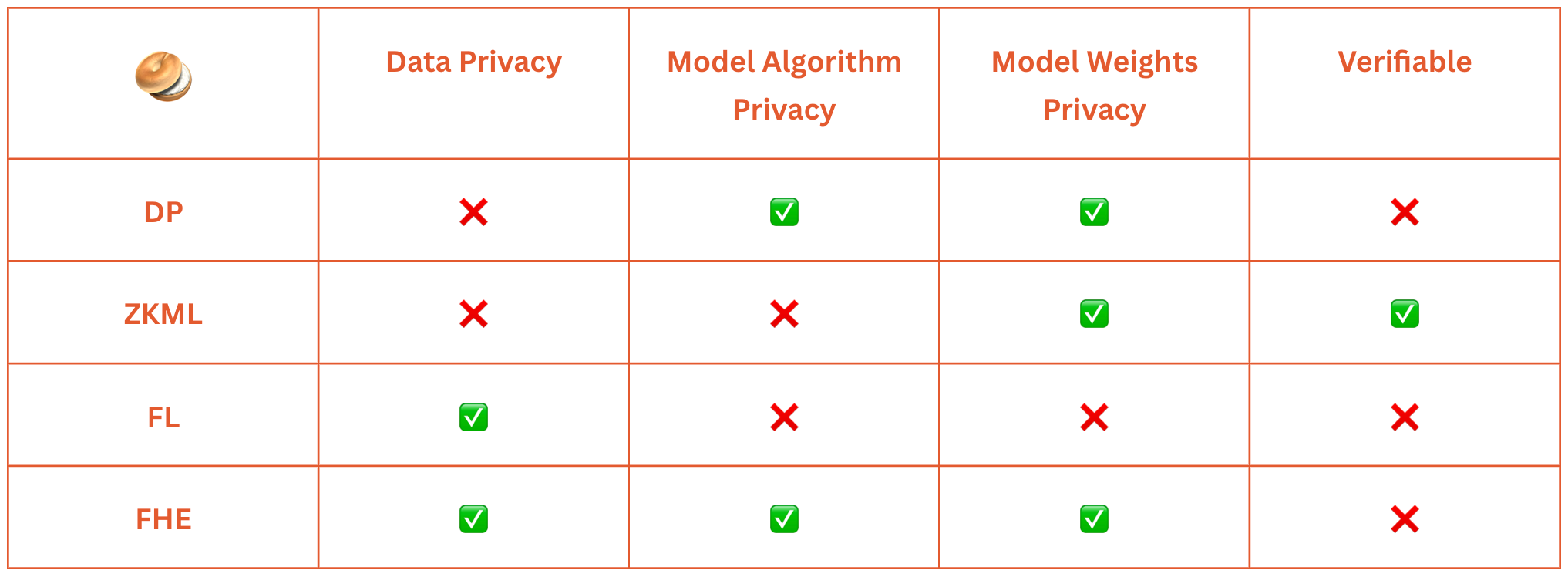
We examined the four most widely used privacy-preserving techniques in machine learning, focusing on neural network training and inference. We evaluated these techniques across four dimensions: data privacy, model algorithm privacy, model weights privacy, and verifiability.
Data privacy considers the model owner’s access to private data. Differential privacy (DP) and zero-knowledge machine learning (ZKML) require access to private data for training and proof generation, respectively. Federated learning (FL) enables training and inference without revealing data, while fully homomorphic encryption (FHE) allows computations on encrypted data.
Model algorithm privacy refers to the data owner’s access to the model’s algorithms. DP does not require algorithm disclosure, while ZKML necessitates it for proof generation. FL distributes algorithms among local servers, and FHE operates without accessing the model’s algorithms.
Model weights privacy concerns the data owner’s access to the model’s weights. DP and ZKML keep weights undisclosed or provide proofs of existence without revealing values. FL involves exchanging weights among servers for decentralized learning, contrasting with DP and ZKML’s privacy-preserving mechanisms. FHE enables training and inference on encrypted data, eliminating the need for model owners to know the weights.
Verifiability refers to the inherent capabilities for verifiable computation. ZKML inherently provides this capability. DP, FL, and FHE would not provide similar levels of integrity assurance.
The table below summarizes our findings:
What’s Next 🥯
At Bagel, we recognize that existing privacy-preserving machine learning solutions fall short in providing end-to-end privacy, scalability, and strong trust assumptions. To address these limitations, our team has developed a novel approach based on a modified version of homomorphic encryption (FHE).
Our pilot results are extremely promising, indicating that our solution has the potential to revolutionize the field of privacy-preserving machine learning. By leveraging the strengths of homomorphic encryption and optimizing its performance, we aim to deliver a scalable, trustworthy, and truly private machine learning framework.
We believe that our work represents a paradigm shift in the way machine learning is conducted, ensuring that the benefits of AI can be harnessed without compromising user privacy or data security. As we continue to share more about our approach, we invite you to follow our progress by subscribing to the Bagel blog.
For more thought pieces from Bagel, follow out their blog here.
To stay updated on the latest Filecoin happenings, follow the @Filecointldr handle.
Disclaimer: This information is for informational purposes only and is not intended to constitute investment, financial, legal, or other advice. This information is not an endorsement, offer, or recommendation to use any particular service, product, or application.
Editor’s Note: This article draws heavily from David Aronchick’s presentation at the Filecoin Unleashed Paris 2023. David is the CEO of Expanso and former head of Compute-over-data at Protocol Labs which is responsible for the launch of the Bacalhau project. This blog post represents the independent view of the creator of the original content, who has given permission for this re-publication.
The world will store more than 175 zettabytes of data by 2025, according to IDC. That’s a lot of data, precisely 175 trillion 1GB USB sticks. Most of this data will be generated between 2020 and 2025, with an estimated compound annual growth of 61%.
The rapidly growing data sphere broadly poses two major challenges today:
Moving data is slow and expensive. If you attempted to download 175 zettabytes at current bandwidth, it would take you roughly 1.8 billion years.
Compliance is hard. There are hundreds of data-related governances worldwide which makes compliance across jurisdictions an impossible task.
The combined result of poor network growth and regulatory constraints is that nearly 68% of enterprise data is unused. That’s precisely why moving compute resources to where the data is stored (broadly referred to as compute-over-data) rather than moving data to the place of computation becomes all the more important, something which compute-over-data (CoD) platforms like Bacalhau are working on.
In the upcoming sections, we will briefly cover:
How organizations are currently handling data today
Propose alternative solutions based on compute-over-data
There are three main ways in which organizations are navigating the challenges of data processing today — none of which are ideal.
Using Centralized Systems
The most common approach is to lean on centralized systems for large-scale data processing. We often see enterprises use a combination of compute frameworks — Adobe Spark, Hadoop, Databricks, Kubernetes, Kafka, Ray, and more — forming a network of clustered systems that are attached to a centralized API server. However, such systems fall short of effectively addressing network irregularities and other regulatory concerns around data mobility.
This is partly responsible for companies coughing up billions of dollars in governance fines and penalties for data breaches.
Building It Themselves
An alternative approach is for developers to build custom orchestration systems that possess the awareness and robustness the organizations need. This is a novel approach but such systems are often exposed to risks of failure by an over-reliance on a few individuals to maintain and run the system.
Doing Nothing
Surprisingly, more often than not, organizations do nothing with their data. A single city, for example, may collect several petabytes of data from CCTV recordings a day and only view them on local machines. The city does not archive or process these recordings because of the enormous costs involved.
Building Truly Decentralized Compute
There are 2 main solutions to the data processing pain points.
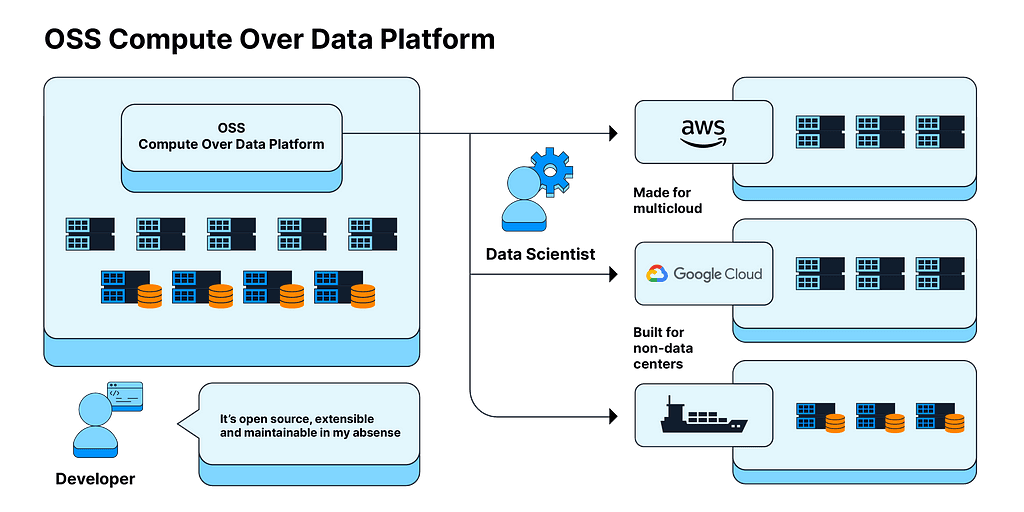
Solution 1: Build on top of open-source compute-over-data platforms.
Solution 1: Open Source Compute Over Data Platforms
Instead of using a custom orchestration system as specified earlier, developers can use an open-source decentralized data platform for computation. Because it is open source and extensible, companies can build just the components they need. This setup caters to multi-cloud, multi-compute, non-data-center scenarios with the ability to navigate complex regulatory landscapes. Importantly, access to open-source communities makes the system less vulnerable to breakdowns as maintenance is no longer dependent on one or a few developers.
Solution 2: Build on top of decentralized data protocols.
With the help of advanced computational projects like Bacalhau and Lilypad, developers can go a step further and build systems not just on top of open-source data platforms as mentioned in Solution 1, but on truly decentralized data protocols like the Filecoin network.
Solution 2: Decentralized Compute Over Data Protocols
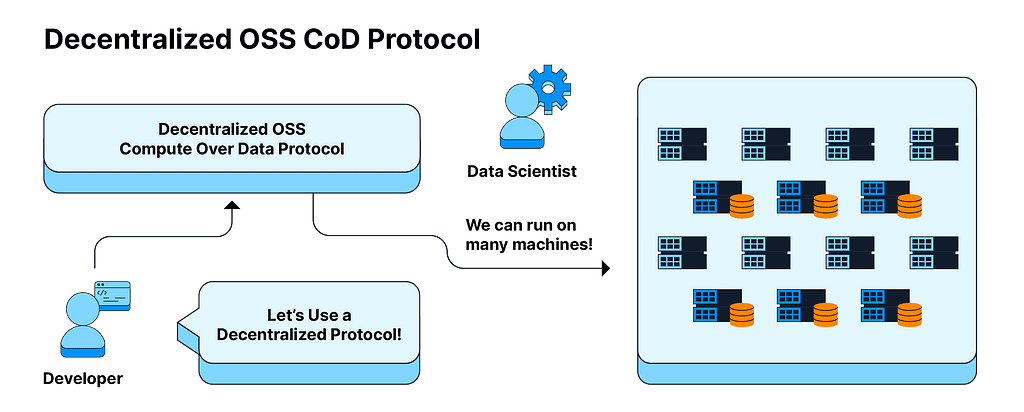
What this means is that organizations can leverage decentralized protocols that understand how to orchestrate and describe user problems in a much more granular way and thereby unlock a universe of compute right next to where data is generated and stored. This switchover from data centers to decentralized protocols can be carried out ideally with very few changes to the data scientists’ experience.
Decentralization is About Maximizing Choices
By deploying on decentralized protocols like the Filecoin network, the vision is that clients can access hundreds (or thousands) of machines spread across geographies on the same network, following the same protocol rules as the rest. This essentially unlocks a sea of options for data scientists as they can request the network to:
Select a dataset from anywhere in the world
Comply with any governance structures, be it HIPAA, GDPR, or FISMA.
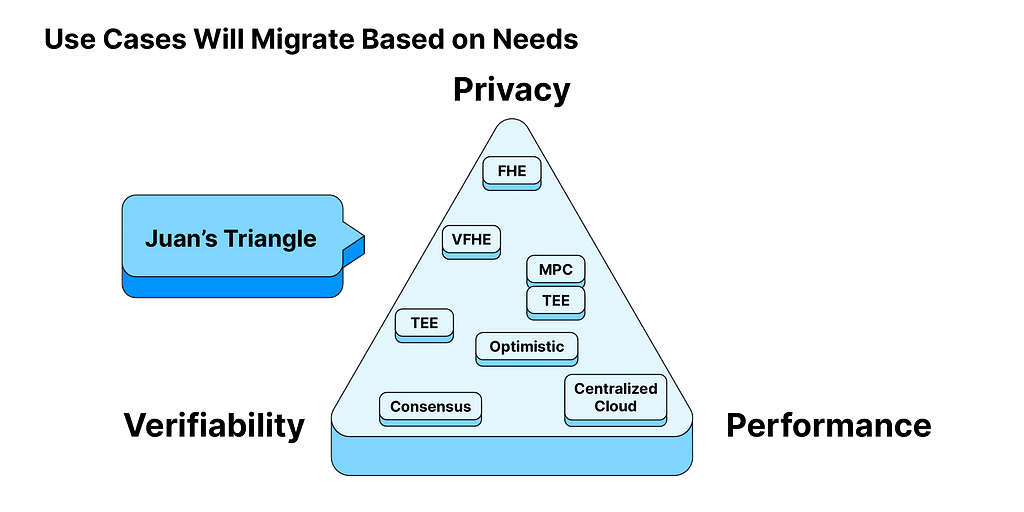
The concept of maximizing choices brings us to what’s called “Juan’s triangle,” a term coined after Protocol Labs’ founder Juan Benet for his explanation of why different use cases will have (in the future) different decentralized compute networks backing them.
Juan’s triangle explains that compute networks often have to trade off between 3 things: privacy, verifiability, and performance. The traditional one-size-fits-all approach for every use case is hard to apply. Rather, the modular nature of decentralized protocols enables different decentralized networks (or sub-networks) that fulfill different user requirements — be it privacy, verifiability, or performance. Eventually, it is up to us to optimize for what we think is important. Many service providers across the spectrum (shown in boxes within the triangle) fill these gaps and make decentralized compute a reality.
In summary, data processing is a complex problem that begs out-of-the-box solutions. Utilizing open-source compute-over-data platforms as an alternative to traditional centralized systems is a good first step. Ultimately, deploying on decentralized protocols like the Filecoin network unlocks a universe of compute with the freedom to plug and play computational resources based on individual user requirements, something that is crucial in the age of Big Data and AI.
Follow the CoD working group for all the latest updates on decentralized compute platforms. To learn more about recent developments in the Filecoin ecosystem, tune into our blog and follow us on social media at TL;DR, Bacalhau, Lilypad, Expanso, and COD WG.
Editor’s Note: This blogpost is a repost of the original content published on 7 June 2023, by Luffistotle from Zee Prime Capital. Zee Prime Capital is a VC firm investing in programmable assets and early-stage founders globally. They call themselves a totally supercool and chilled VC (we tend to agree) investing in programmable assets, collaborative intelligence and other buzzwords. Luffistotle is an Investor at Zee Prime Capital. This blogpost represents the independent view of the author, who has given permission for this re-publication.
Table of Contents
History of P2P
Decentralized Storage Network Landscape
FVM
Permanent Storage
Web 3’s First Commercial Market
Consequences of Composability
Storage is a critical part of any computing stack. Without this fundamental element, nothing is possible. Through the continued advancement of computational resources, a great deal of excess and underutilized storage has been created. Distributed Storage Networks (DSNs) offer a way to coordinate and utilize these latent resources and turn them into productive assets. These networks have the potential to bring the first real commerce vertical into Web 3 ecosystems.
History of P2P
The history of real Peer-to-peer file sharing began to hit the mainstream with the advent of Napster. While there were early methods of sharing files on the internet before this, the mainstream finally joined with the sharing of MP3 files that Napster brought. From this initial starting point, the distributed systems world exploded with activity. The centralization within Napster’s model (for indexing) made it easy to shut down given its legal transgressions, however, it laid the foundation for more robust methods of file sharing.
The Gnutella Protocol followed this trailblazing and had many different effective front-ends leveraging the network in different ways. As a more decentralized version of the napstereqsue query network, it was much more robust to censorship. Even in its day, it experienced censorship. AOL had acquired the developing company Nullsoft, and quickly realized the potential, shutting distribution down almost immediately. However, it had already made it outside and was quickly reverse-engineered. Bearshare, Limewire, and Frostwire are likely the most notable of these front-end applications you may have encountered. Where it ultimately failed was the bandwidth requirements (a deeply limited resource at the time) combined with the lack of liveness and content guarantees.
Remember this? If not do not worry, it has been reborn as an NFT marketplace…
What came next was Bittorrent. This presented a level-up due to the two-sided nature of the protocol and its ability to maintain Distributed Hash Tables (DHTs). DHTs are important because they serve as a decentralized version of a ledger that stores the locations of files and is available for lookup by other participating nodes in the network.
After the advent of Bitcoin and blockchains, people started thinking big about how this novel coordination mechanism could be used to tie together networks of latent unused resources and commodities. What followed soon after was the development of DSNs.
Something that would perhaps surprise many people, is that the history of tokens and P2P networks goes back much farther than the existence of bitcoin and blockchains. What pioneers of these networks realized very quickly was a couple of the following points:
Monetizing a useful protocol you have built is difficult as a result of forking. Even if you monetize a front end and serve ads or utilize other forms of monetization, a fork will likely undercut you.
Not all usage is created equal. In the case of Gnutella, 70% of users did not share files and 50% of requests were for files hosted by the top 1% of hosts.
Power laws.
How does one remedy these problems? For BitTorrent it is seeding ratios (download/upload ratio), for others, it was the introduction of primitive token systems. Most often called credits or points they were allocated to incentivize good behavior (that promotes the health of the protocol) and stewardship of the network (like regulating content in the form of trust ratings). For a deeper dive into the broader history of all of this, I highly recommend these (now deleted, available via web archive) articles by John Backus:
Interestingly a DSN was part of the original vision for Ethereum. The “holy trinity” as it was called was meant to provide the necessary suite of tools for the world computer to flourish. Legend has it, that it was Gavin Wood’s idea for the concept of Swarm as the storage layer for Ethereum with Whisper as the messaging layer.
Mainstream DSNs followed and the rest is history.
Decentralized Storage Network Landscape
The decentralized storage landscape is most interesting because of the huge disparity between the size of the leader (Filecoin) and the other more nascent storage networks. While many people think of the storage landscape as two giants of Filecoin and Arweave, it would likely surprise most people that Arweave is the 4th largest by usage, behind Storj and Sia (although Sia seems to be declining in usage). And while we can readily question how legitimate the FIL data stored is, even if we handicapped it by say 90%, FIL usage is still ~400x Arweave.
What can we infer from this?
There is clear dominance in the market right now, but the continuity of this is dependent on the usefulness of these storage resources. The DSNs all roughly use the same architecture, node operators have a bunch of unused storage assets (hard drives), and they can pledge these to the network, mine blocks, and earn miner rewards for storing data. While the approaches to pricing and permanence may differ, the most important will be how easy and affordable retrieval and computation of the stored data is.
Fig 1. Storage Networks by Capacity and Usage
N.B:
Arweave Capacity is not directly measurable; instead, node operators are always incentivized to have sufficient buffer and to increase supply to meet demand. How big is the buffer? Given the immeasurability of it, we can not know.
Swarm’s actual network usage is impossible to tell, we can only look at how much storage has been paid for already. Whether it is used is unknown.
While this is the table of live projects, there are other DSNs in the works. These include ETH Storage, Maidsafe, and others.
FVM
Before going further it is probably worth noting that Filecoin has recently launched the Filecoin Ethereum Virtual Machine (FEVM). The FVM is a WASM VM that can support many different other runtimes on top via hypervisor. For instance, this recently launched FEVM is an Ethereum Virtual Machine runtime on top of the FVM/FIL network. The reason this is worth highlighting is that it facilitates the explosion of activity concerning smart contracts (i.e. stuff) on top of FIL. Before the March launch, there were 11 active smart contracts on FIL, following the FVM launch this has exploded. It benefits from composability in the form of leveraging all the work done in solidity to build out new businesses on top of FIL. This means innovations like quasi-liquid staking type primitives from teams like GLIF, and the various additional financialization of these markets you can build on top of such a platform. We believe this will accelerate storage providers because of the increases in capital efficiency (SPs need FIL to actively mine/seal storage deals). This differs from typical LSDs as there is an element of assessing the credit risk of the individual storage providers.
Permanent Storage
I believe Arweave gets the most airtime on this front, it has a flashy tagline that appeals to the deepest desires of Web 3 Participants:
Permanent Storage.
But what does this mean? It is an extremely desirable property, but in reality, execution is everything. Ultimately execution comes down to sustainability and cost for the end users. Arweave’s model is based on a pay-once, store forever (200 years upfront + deflation of storage value assumption) model. This kind of pricing model works well in a deflationary pricing environment of the underlying asset, as there is a constant goodwill accrual (i.e. old deals subsidize new deals) however the inverse is true in inflationary environments. History tells us this shouldn’t be an issue as the cost of computer storage has more or less been down only since inception but hard drive cost alone is not the whole picture.
Arweave creates permanent storage via the incentives of the Succinct Proof of Random Access (SPoRA) algorithm which incentivizes miners to store all the data and prove they can randomly produce a historical block. Doing so gives them a higher probability of being selected to create the next block (and earn the corresponding rewards).
While this model does a good job of getting node runners to want to store all of the data, it does not mean it is guaranteed to happen. Even if you set super high redundancy and use conservative heuristics to decide the parameters of the model, you can never get rid of this underlying risk of loss.
Source: Twitter
Fundamentally the only way to truly execute permanent storage would be to deterministically force somebody (everybody?) to and throw them in the gulag when they screw up. How do you properly incentivize personal responsibility such that you can achieve this? There is nothing wrong with the heuristic approach, but we need to identify the optimal way to achieve and price permanent storage.
All of this is a long-winded way of getting to the point of asking what level of security we deem acceptable for permanent storage, and then we can think about that pricing over a given time frame. In reality, consumer preferences will fall along the spectrum of replication (permanence), and thus they should be able to decide what this level is and receive the corresponding pricing.
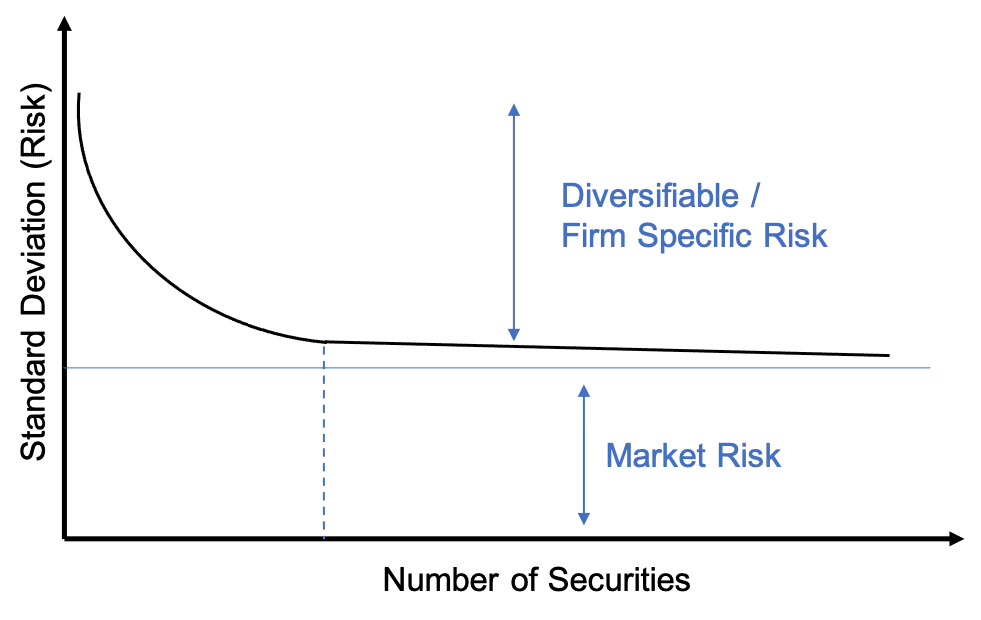
In traditional investing literature and research, there is infamous knowledge about how the benefits of diversification work on the overall risk of a portfolio. While adding stocks initially brings risk reduction to your portfolio, very quickly the diversification benefits of adding stock become more or less not valuable.
I believe the pricing of storage over and above some default standard of replication on the DSN should follow a similar curve but for cost and security of the storage with an increasing amount of replication.
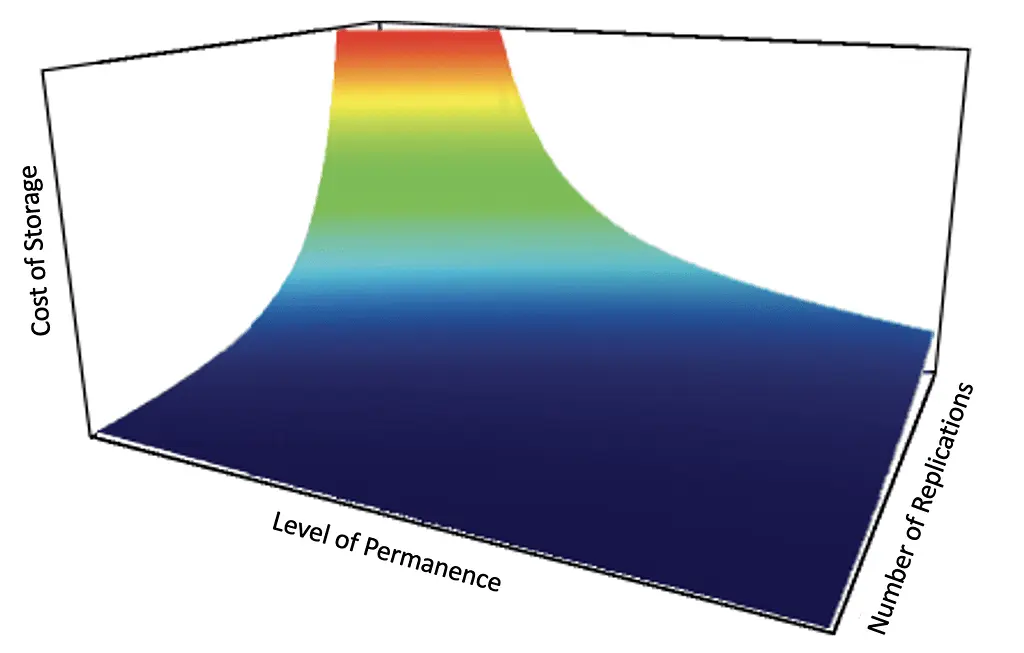
For the future, I am most excited about what more DSNs with easily accessible smart contracting can bring to the market for permanent storage. I think overall consumers will benefit the most from this as the market opens up this spectrum of permanence.
For instance, in the chart above we can think of the area in green as the area of experimentation. It may be possible to achieve exponential decreases in the cost of that storage with minimal changes to the number of replications and level of permanence.
Additional ways of constructing permanence could come from replication across different storage networks rather than just within a single network. These kinds of routes are more ambitious but naturally lead to more differentiated levels of permanence. The biggest question here would be is there some kind of “permanence-free lunch” we could achieve by spreading it across DSNs in the same way we diversify market risk across a portfolio of publicly traded equities?
The answer could be yes, but it depends on node provider overlap and other complex factors. It could also be constructed via forms of insurance, possibly by node runners subjecting themselves to higher levels of slashing conditions in exchange for these assurances. Maintaining such a system would also be extremely complex as multiple codebases and coordination between them are required. Nonetheless, we look forward to this design scape expanding significantly and forwarding the general idea of permanent storage for our industry.
Web 3’s First Commercial Market
Matti tweeted recently about the promise of storage as the use case to bring Web 3 some real commerce. I believe this is likely.
I was having a conversation recently with a team from a layer one where I told them it is their moral imperative to fill their blockspace as stewards of the L1, but even more than this, it is to do this with economic activity. The industry often forgets the second part of its name.
The whole currency part.
Any protocol that launches a token that would not like to be down only is asking for some kind of economic activity to be conducted in that currency. For layer 1s it’s their native token, processing payments (executing computation) and charging a gas fee for doing so. The more economic activity happening, the more gas is used, and the more demand for their token. This is the crypto-economic model. For other protocols, it is likely some kind of middleware SaaS service.
What makes this model most interesting is when it is paired with some kind of commercial good, in the case of classical L1s it is computation. The problem with this is that as it pertains to something like financial transactions, having variable pricing on the execution is a horrible UX. The cost of execution should be the least important part of a financial transaction such as a swap.
What becomes difficult is filling this blockspace with economic activity in the face of this bad UX. While scaling solutions are on the way that will help stabilize this (I highly recommend this whitepaper on Interplanetary Consensus warning PDF), the flooded market of layer 1s makes it difficult to find enough activity for a given one.
This problem is much more addressable when you pair this computational capacity with some kind of additional commercial good. In the case of DSNs, this is storage. The economic activity of data being stored and the related elements such as financing and securitization of these storage providers is an immediate filler.
But this storage also needs to be a functional solution for traditional businesses to use. Particularly those who deal with regulations around how their data is stored. This most commonly comes in the form of auditing standards, geographical restrictions, and making the UX simple enough to use.
We’ve discussed Banyan before in our Middleware Thesis part 2, but their product is a fantastic step in the right direction on this front. Working with node operators in a DSN to secure SOC certifications for the storage being provided while offering a simple UX to facilitate the upload of your files.
But this alone is not enough.
The content stored also needs to be easily accessible with efficient retrieval markets. One thing we are very excited about at Zee Prime is the promise of creating a Content Distribution Network (CDN) on top of a DSN. A CDN is a tool to cache content close to the users and deliver improved latency when retrieving the content.
We believe this is the next critical component to making DSNs widely adaptable as this allows videos to load quickly (think building decentralized Netflix, Youtube, TikTok, etc.). One proxy to this space is our portfolio company Glitter, which focuses on indexing DSNs. This is important because it is a critical piece of infrastructure to improve the efficiency of retrieval markets and facilitate these more exciting use cases.
The potential for these kinds of products excites us as they have demonstrated PMF with high demand in Web 2. Despite this adoption, many face frictions that could benefit from leveraging the permissionless nature of Web 3 solutions.
Consequences of Composability
Interestingly, we think some of the best alpha on DSNs is hiding in plain sight. In these two pieces by Jnthnvctr he shares some great ideas on how these markets will evolve and the products that will come (on the Filecoin side):
One of the most interesting takeaways is the potential for pairing off-chain computation in addition to storage and on-chain computation. This is because of the natural computational needs of providing storage resources in the first place. This natural pairing can add commercial activity to flow through the DSN while opening up new use cases.
The launch of the FEVM makes many of these level-ups possible and will make the storage space much more interesting and competitive. For founders searching for new products to build, there is even a resource of all the products Protocol Labs is requesting people to build with potential grants available.
In Web 2 we learned that data has a kind of gravitational pull, where companies that collected/created a lot of it can reap the rewards and were accordingly incentivized to close it off in such a way to protect that.
If our dreams of user-controlled data solutions become mainstream, we can ask ourselves how the point where this value accrual happens changes. While users become primary beneficiaries, receiving cash flows in exchange for their data, no doubt monetization tools that unlock this potential also benefit, but where and how this data is stored and accessed also changes dramatically. Naturally, this kind of data can sit on DSNs which benefit from the usage of this data via robust query markets. This is a shift from exploitation toward flow.
What comes after could be extremely exciting.
When we think about the future of decentralized storage, it is fun to consider how it might interact with operating systems of the future like Urbit. For those unfamiliar, Urbit is a kind of personal server built with open-source software that allows you to participate in a peer-to-peer network. A true decentralized OS to do self-hosting and interact with the internet is a P2P way.
If the future plays out the way Urbit maximalists might hope, decentralized storage solutions undoubtedly become a critical piece of the individual stack. One can easily imagine hosting all their user-related data encrypted on one of the DSNs and coordinating actions via their Urbit OS. Further to this, we could expect further integrations with the rest of Web 3 and Urbit, especially with projects such as Uqbar Network, which brings smart contracting to your Nook environment.
These are the consequences of composability, the slow burn continues to build up exponentially until it delivers something really exciting. What feels like thumb twaddling becomes a revolution, an alternative path towards existing in a hyper-connected world. While Urbit might not be the end solution on this front (it has its criticisms), what it does show us is how these pieces can come together to open up a new river of exploration.